IBM Patents a Self-Tuning System for LLM RAG Pipeline Parameters
Getting an LLM to answer questions accurately over your own documents depends heavily on a tangle of configuration knobs — chunk size, overlap, retrieval depth — and IBM is patenting a system that uses machine learning to find the best combination automatically, without a human having to guess.
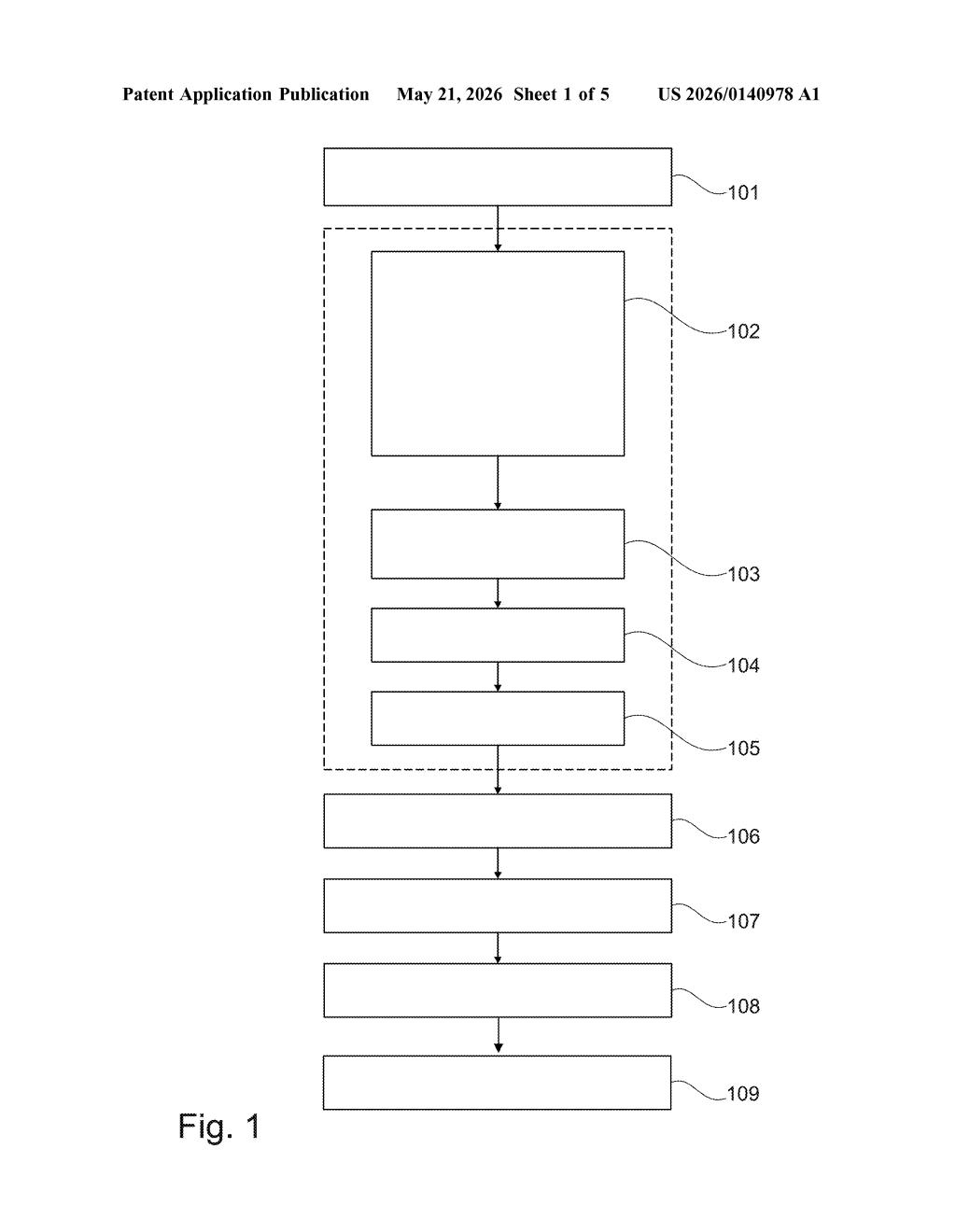
How IBM's system auto-tunes your LLM pipeline
Imagine you're building a chatbot that answers questions using your company's internal documents. The accuracy of that chatbot depends on dozens of fiddly settings: how long the text snippets fed to the AI should be, how much they overlap, how many are retrieved at a time. Getting those settings right today mostly means trial and error by a developer.
IBM's patent describes a system that automates this tuning process. It runs the LLM pipeline many times with different combinations of settings, scores each run by comparing the AI's answers against known correct answers, and then trains a secondary machine-learning model on those results. That surrogate model learns the relationship between settings and quality scores.
Once trained, that surrogate model is used to search for a combination of settings predicted to score even better than anything tested so far — without needing to run the full, expensive LLM pipeline for every possible combination. It's essentially using ML to shop for the best ML configuration.
How the ML module scores and searches parameter space
This patent covers a method for optimizing the hyperparameters of a Retrieval-Augmented Generation (RAG) pipeline — the architecture where an LLM is given relevant document chunks as context before answering a question.
The system works in two phases. In the first phase, it runs repeated experiments: each repetition uses a different "mode" (a specific combination of parameter values) to chunk documents and assemble input context, feeds the resulting prompt to the LLM, and then scores the LLM's provisional answer against a ground-truth answer from a pre-loaded Q&A set. An overall score is computed per mode.
In the second phase, those (parameter-set → score) pairs become training data for an ML surrogate model (think of it as a fast, cheap approximation of the expensive LLM pipeline). This surrogate learns to predict quality scores from parameter configurations.
Finally, the system performs an optimization search over the surrogate model's predictions to find a parameter set expected to yield a score higher than any observed in the training runs — a classic Bayesian optimization-style approach (using a learned proxy function to guide exploration instead of exhaustively testing every combination). The key parameters being tuned likely include things like chunk size, chunk overlap, number of retrieved chunks, and context assembly strategy.
What this means for enterprise LLM deployment costs
For enterprises deploying RAG-based LLM systems — think internal knowledge bases, customer support bots, or document Q&A tools — parameter tuning is a real, time-consuming, and expensive problem. Right now it largely falls on ML engineers running manual experiments. A system that automates this search could meaningfully cut the cost and time-to-deployment for production LLM pipelines.
The deeper strategic angle is that IBM's watsonx platform is squarely aimed at enterprise AI deployments, and tooling that reduces the expertise required to stand up an accurate RAG system is directly on-brand. If this approach ships as part of watsonx, it could be a meaningful differentiator for customers who don't have large ML teams to hand-tune their pipelines.
This is solid, pragmatic engineering work aimed at a real pain point in enterprise AI deployment — RAG tuning is genuinely painful and under-automated. It's not a flashy AI research breakthrough, but the kind of infrastructure tooling that actually determines whether LLM deployments succeed in production. IBM is smart to patent this territory now, as RAG optimization is becoming a commodity battleground among cloud AI platforms.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.