Microsoft Patents a Split Neural Network System That Runs Across Device and Cloud
What if your phone only had to do part of the AI thinking, and the cloud quietly filled in the gaps? That's exactly the architecture Microsoft is patenting here.
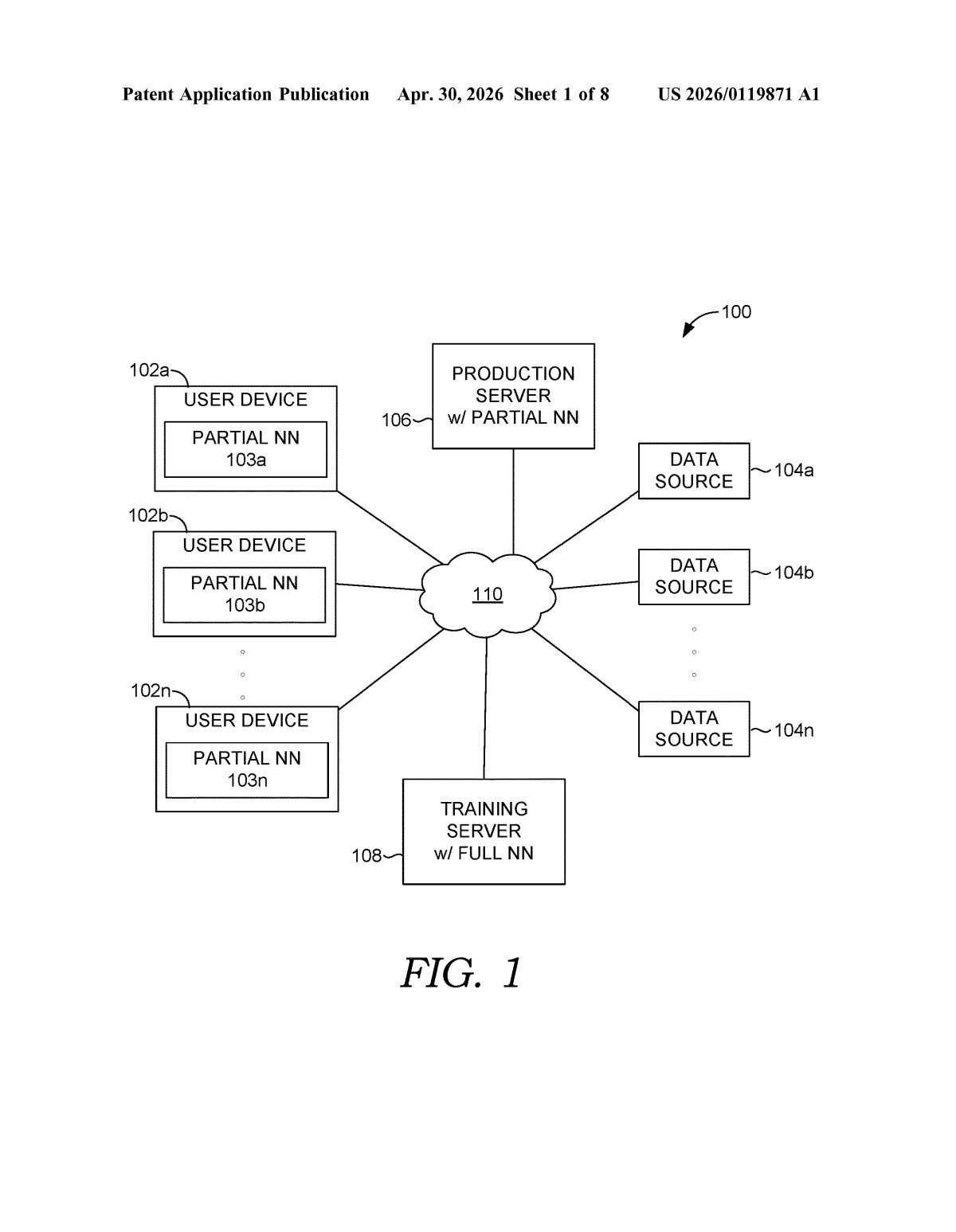
Inside Microsoft's device-plus-cloud neural network split
Imagine you're running an AI model on your laptop — something like a smart autocomplete or a vision system. Your device is capable, but not powerful enough to run the whole model at full speed. So what if it only ran most of the work, and a server picked up the rest?
That's the core idea behind this Microsoft patent. The neural network — the engine behind most modern AI — gets split into two pieces. Your device runs the bigger chunk of a given layer, while a server in the cloud runs a much smaller slice (less than 20% of the nodes). The two sides then combine their outputs into a single result, which gets sent back to your device.
The clever part is that neither side is idle or redundant. Your device does the heavy lifting, keeping latency low and data local, while the cloud's slice acts more like a corrective or complementary signal. It's a team effort — and one that could make powerful AI models feel snappier on everyday hardware.
How Microsoft's partial-node layer handoff actually works
This patent describes a hybrid deployment architecture for neural networks — systems where a single model layer is processed simultaneously by two different compute environments: the user's device and a remote server.
Here's the key mechanic: for any given layer in the neural network, the client-side (your device) runs a portion containing less than 100% of that layer's nodes. The server-side runs a much smaller complementary slice — less than 20% of the nodes for that same layer. Both sides receive the same layer input (the raw data going into that layer), but each computes its own partial output independently.
The server then combines the two partial outputs — client-side and server-side — into a single final output for that layer, which is sent back to the client to continue the forward pass through the rest of the network. Think of it like two calculators solving different parts of the same equation and then merging answers.
The architecture targets what engineers call the edge-cloud trade-off: running everything on-device is fast and private but resource-constrained; running everything in the cloud is powerful but adds latency and bandwidth costs. This system tries to split the difference — literally — by assigning most computation to the client while letting the server provide a lightweight corrective or complementary signal.
What this means for on-device AI and cloud cost trade-offs
For end users, this could mean AI features that feel faster and more capable on mid-range devices — think smarter real-time translation, better on-device image recognition, or more responsive Copilot-style assistants — without requiring beefy local hardware or a constant fat data pipe to the cloud.
For Microsoft strategically, this fits neatly into the ongoing push to run AI closer to the edge as model sizes balloon. If you can keep 80%+ of compute on the device, you cut cloud inference costs dramatically while reducing the amount of raw user data that ever leaves the phone or laptop. That's a privacy and cost story wrapped in one architecture.
This is genuinely interesting infrastructure work. The specific threshold — server handles under 20% of nodes — suggests Microsoft has done real empirical work on where the efficiency cliff is, not just filed a broad concept patent. Whether it ships in Azure AI services, Windows Copilot runtime, or something else entirely, the underlying idea is one of the more practical approaches to hybrid AI deployment we've seen filed.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.