Google Patents a System That Auto-Fills AI Prompts With Cloned Synthetic Data
Imagine writing an AI prompt with a blank space — a placeholder that says 'insert customer invoice here' — and having the system automatically generate a realistic fake invoice to fill it. That's exactly what Google is patenting.
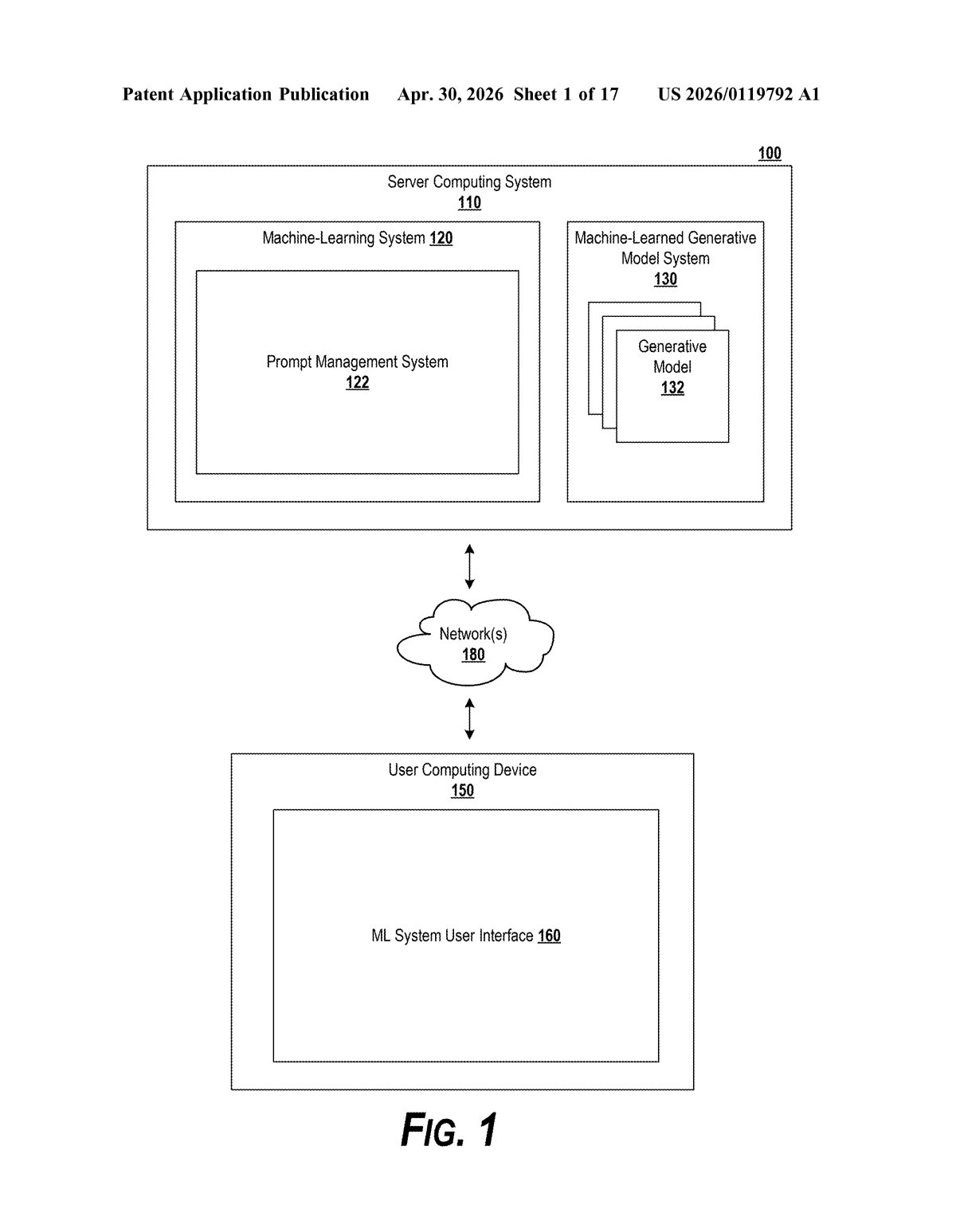
What Google's synthetic prompt-filler actually does
Picture you're a developer building an AI tool that reads customer contracts. To test it, you need sample contracts — but real ones are confidential and fake ones take forever to write. This patent describes a system that does that busywork for you.
You write a prompt with a variable — basically a blank space labeled 'put a contract here' — and point it at a real data source. Google's system reads that data source, figures out what kind of document you need and what context you're working in, then generates a synthetic version that mimics the structure and style of the real thing, without copying sensitive content.
The filled-in prompt then gets sent to your target AI model as if it had real data in it. The result: you can test and develop AI pipelines with realistic-looking data, no actual sensitive documents required.
How the system clones real data into prompt-ready fakes
The system works in a four-step pipeline, each step handled by a machine-learned model:
- Step 1 — Understand intent: A generative model reads your prompt (including the variable placeholder) and any data source reference, then identifies the context (what the prompt is trying to do) and the data type (what kind of data belongs in the blank).
- Step 2 — Find the best examples: An embedding model (a model that converts text into numerical representations so similar content can be compared mathematically) searches the referenced data source and retrieves the most relevant document chunks — small sections that best match the needed data type and context.
- Step 3 — Extract attributes: The generative model analyzes those chunks to identify their structural and stylistic attributes — things like format, length, terminology patterns, and schema.
- Step 4 — Synthesize and inject: Using all of the above — context, data type, example chunks, and extracted attributes — the model generates a synthesized data sample that emulates the real data. That sample replaces the variable in your original prompt, which is then executed against your target AI model.
The patent describes this as a fully automated loop, meaning no human has to manually craft the fake data at any point.
What this means for AI testing and data privacy
For AI developers, one of the most tedious parts of building pipelines is sourcing safe, realistic test data. Real datasets are often proprietary or privacy-sensitive; hand-crafted fake data is time-consuming and rarely realistic enough to expose edge cases. Google's approach automates that middle layer — letting developers reference a real data source for structure and style without ever exposing the underlying content to the model being tested.
This also has implications for enterprise AI deployments, where companies want to demo or test AI on customer data types without using actual customer records. If this system ships inside a Google Cloud or Vertex AI product, it could meaningfully reduce the friction of responsible AI development — and give Google a differentiated selling point in a space where AWS and Azure are competing hard.
This is a genuinely useful piece of infrastructure for AI developers, not a flashy consumer feature. The core insight — that you can extract structural attributes from real data and synthesize a privacy-safe clone — is clever and practical. It slots neatly into Google's Vertex AI strategy, and the single-inventor filing suggests it may have already been prototyped internally.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.