Microsoft Patents a Language Model System That Fills Gaps in Sparse Technical Data
Databases full of holes are a silent killer for data-driven research — and Microsoft thinks a fine-tuned language model can patch them. This patent describes a system that trains an LLM on technical data, then uses it to predict and fill in missing values at scale.
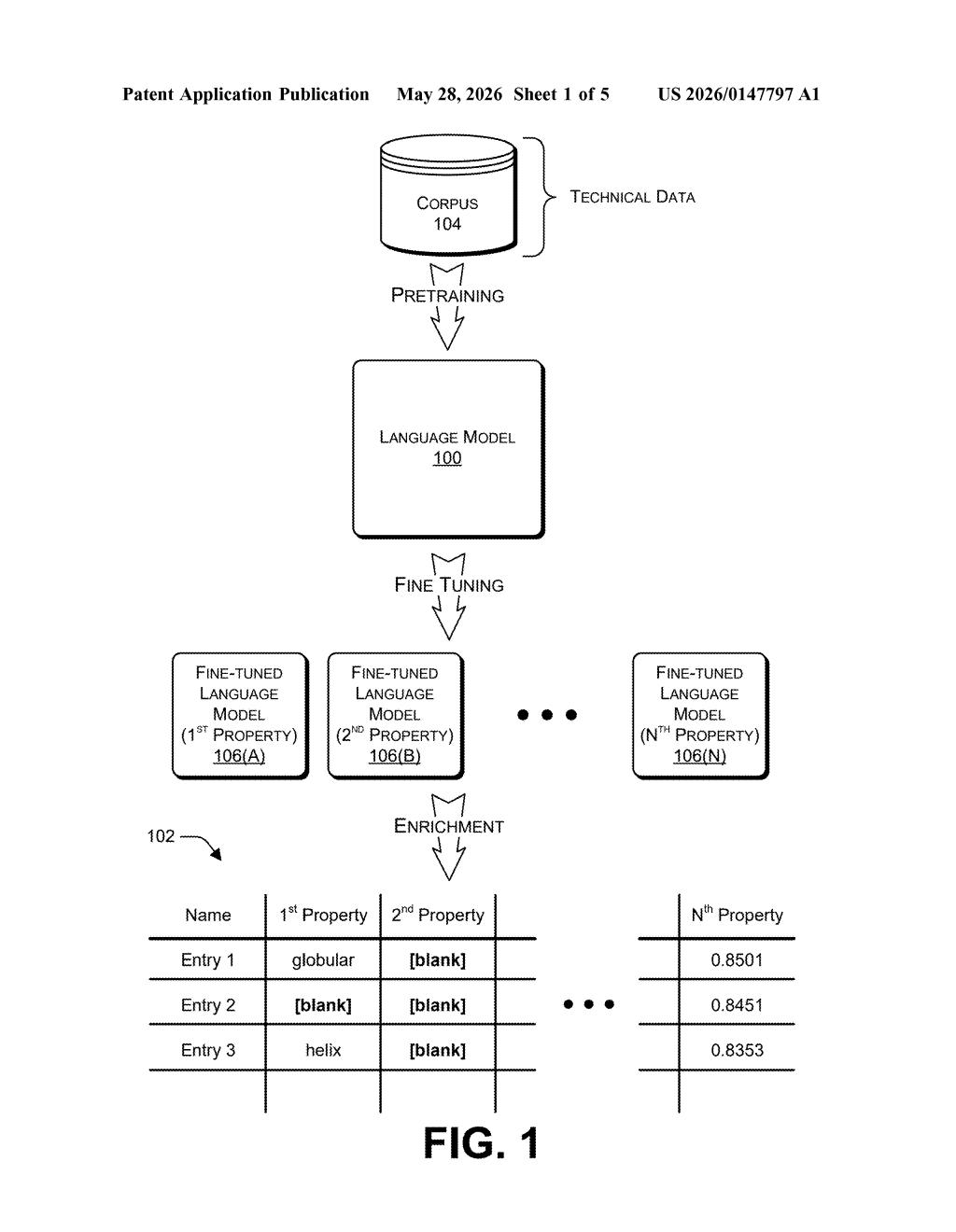
How Microsoft's LLM patches incomplete technical datasets
Imagine you're working with a massive spreadsheet of chemical compounds, materials, or electronic components. Most rows have some data, but huge chunks of columns are blank — nobody ever measured or recorded those properties. That's the "sparse dataset" problem, and it slows down research and engineering work everywhere.
Microsoft's patent describes a way to use a language model — similar in spirit to the AI behind ChatGPT, but trained on technical data instead of web text — to predict what those missing values probably are. The model learns the statistical patterns of your dataset, then fills in the blanks like a very well-informed autocomplete.
The system also goes a step further: it can predict values for entirely new properties that weren't in the original dataset at all. The results get surfaced directly in a user interface, so researchers or engineers can work with a richer, more complete picture of their data without manually hunting down every missing measurement.
How pretraining and fine-tuning combine to predict missing values
The patent outlines a three-stage pipeline built around a language model trained on technical data — think materials science databases, chemical property tables, or component specifications encoded as text strings.
- Pretraining: A language model is trained from scratch (or from a base checkpoint) on a large corpus of unlabeled technical data using masked language modeling — the same technique that powered BERT, where the model learns to predict hidden tokens from context. This gives the model a deep statistical understanding of how technical values relate to one another.
- Fine-tuning per property: The pretrained model is then fine-tuned separately for each specific property you want to predict (e.g., melting point, resistivity, tensile strength). Crucially, fine-tuning only modifies a portion of the model, keeping the shared representations intact while adapting the output head to each target.
- Enrichment and UI output: The fine-tuned models predict missing values for existing records and can even generate values for brand-new properties. A structured data output is generated for display in a user interface, combining original data with the model's predictions.
The approach is explicitly designed to scale — the patent emphasizes transforming large sparse datasets into more complete ones, suggesting this is aimed at enterprise or research-grade data pipelines rather than small-scale use.
What this means for AI-assisted scientific research pipelines
Sparse datasets are an underappreciated bottleneck in materials science, drug discovery, semiconductor R&D, and anywhere else where collecting every measurement is expensive or simply impossible. A system that can reliably impute missing values — and flag new properties worth exploring — could meaningfully accelerate research workflows without requiring more lab time.
For Microsoft, this fits neatly into its broader push to embed AI into enterprise data tools. A capability like this could show up in Microsoft Fabric, Azure's data platform, or research-focused tooling — essentially making LLMs useful not just for text generation but as inference engines over structured scientific and technical knowledge.
This is applied ML for a genuinely unglamorous but high-value problem: incomplete data. The masked-language-modeling approach applied to technical corpora is well-established in research (think MatBERT or ChemBERTa), so the novelty here is more in the system architecture and UI integration than in the modeling technique itself. Still, if Microsoft ships this into Fabric or Azure Data, it's the kind of quiet infrastructure win that earns real loyalty from data-heavy enterprise customers.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.