Microsoft Patents a Domain-Aware Scoring System for AI-Generated Text Edits
When a doctor rewrites an AI-generated clinical note, not every edit carries the same weight — changing a drug name matters far more than fixing a comma. Microsoft's new patent wants to build a scoring system that knows the difference.
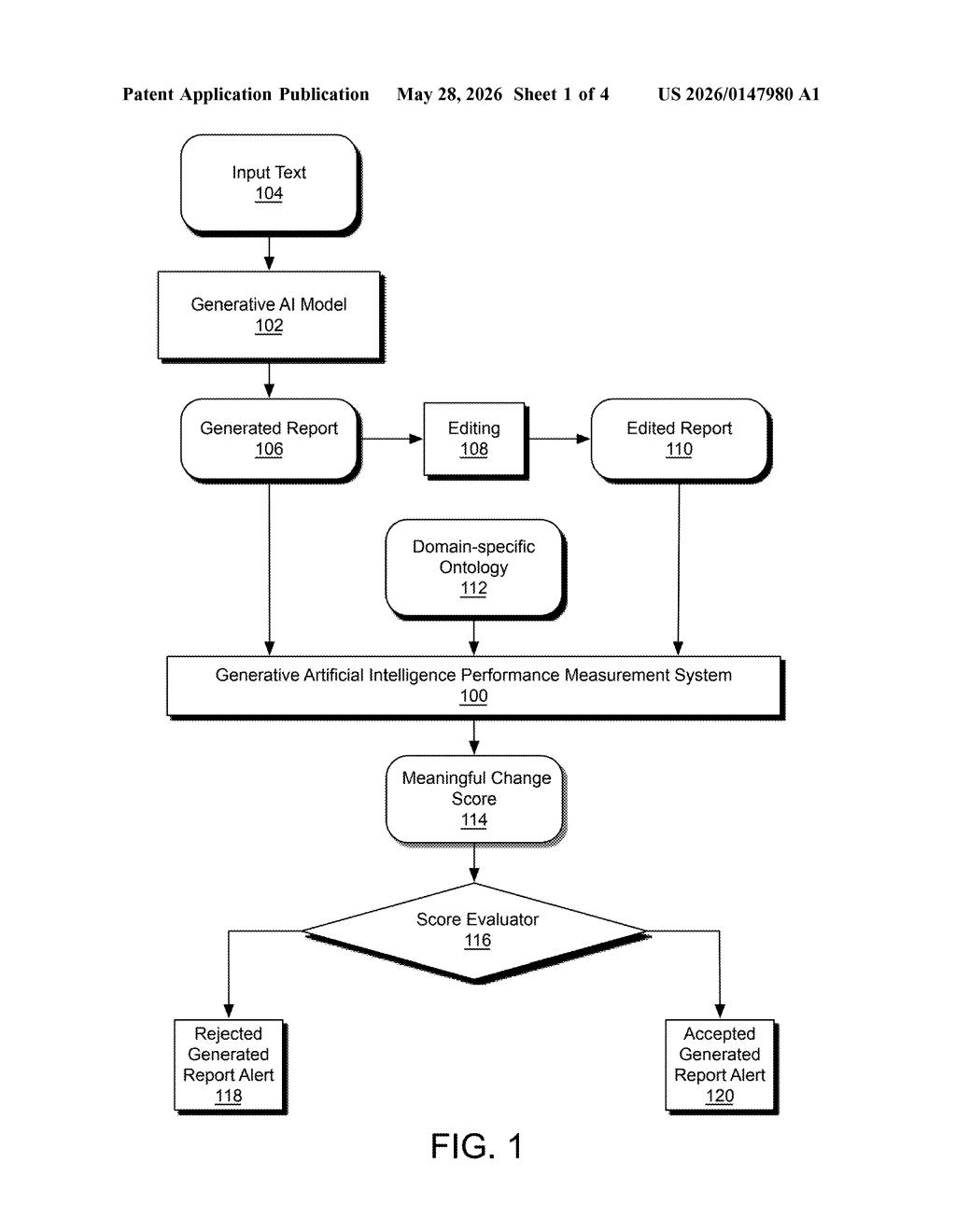
How Microsoft grades human corrections to AI writing
Imagine an AI writes a medical report, and a physician reviews it and makes changes. Some of those changes are trivial — a rephrased sentence, a style tweak. Others are critical — correcting a wrong diagnosis or changing a medication dosage. Today, most AI evaluation tools treat all edits equally, which makes it hard to know whether your AI is actually producing useful output or just plausible-sounding nonsense that experts have to heavily fix.
Microsoft's patent describes a system that measures the domain-meaningful edits a human makes to AI-generated text. It uses something called a domain-specific ontology — essentially a structured map of important concepts in a field (like healthcare or finance) — to figure out which edits actually matter in context.
The end result is a "meaningful change score" that tells you how much a human expert had to correct the AI's output in ways that count. That score can then be used to flag poor AI performance, retrain models, or decide whether a generated report should be accepted or rejected outright.
How the ontology links entities to domain-meaningful weights
The system works in a pipeline with several distinct stages. First, it runs named-entity recognition (NER) — algorithms that identify key terms in both the original AI-generated text and the human-edited version. Think of this as highlighting every noun that could matter: drug names, patient conditions, financial instruments, legal clauses.
Next, each identified entity is linked to a domain-specific ontology — a formal knowledge graph that defines relationships between concepts in a particular field. In healthcare, for example, an ontology might encode that "metformin" is a diabetes medication, and that medications sit higher in a clinical importance hierarchy than, say, appointment scheduling details.
- Delta identification: The system compares the generated and edited texts to find exactly where changes were made.
- Domain-meaningfulness check: Each edit is evaluated against the ontology to determine whether it touches a concept that actually matters in the domain.
- Weight assignment: Domain-meaningful edits get weights based on how important those ontology concepts are — a correction to a drug interaction would score higher than a date format fix.
- Aggregated scoring: All the weighted edits are summed into a single meaningful change score.
The score feeds into an evaluator component that can trigger alerts — flagging a generated report for rejection or routing it back into the AI's feedback loop for retraining.
What this means for enterprise AI quality control
For enterprise use cases — healthcare documentation, legal drafting, financial reporting — the gap between "the AI wrote something grammatically correct" and "the AI wrote something a professional would actually sign off on" is enormous. Current benchmarks like BLEU or ROUGE measure surface-level text similarity, not whether the AI got the important parts right. This patent is Microsoft's attempt to build evaluation infrastructure that's actually domain-aware.
If this ships inside something like Microsoft 365 Copilot or Azure AI services, it could give enterprise customers a measurable, auditable signal for how much their human reviewers are correcting AI output — and whether those corrections are meaningful enough to justify concern. That's exactly the kind of compliance and quality metric regulated industries have been asking for.
This is genuinely useful infrastructure work that addresses a real blind spot in AI evaluation. The insight — that not all human edits to AI text are equally significant, and that domain ontologies can be used to weight them — is practical and well-targeted at regulated enterprise verticals like healthcare and finance. It's not flashy, but it's the kind of plumbing that makes AI deployments trustworthy rather than just impressive-looking.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.