Intel Patents a RAG Pipeline That Continuously Fine-Tunes Its Own AI Models
Intel has patented a system where every question you ask a RAG-powered AI doesn't just get answered — it also feeds a training pipeline that gradually makes the underlying model smarter and the retrieval system cheaper to run.
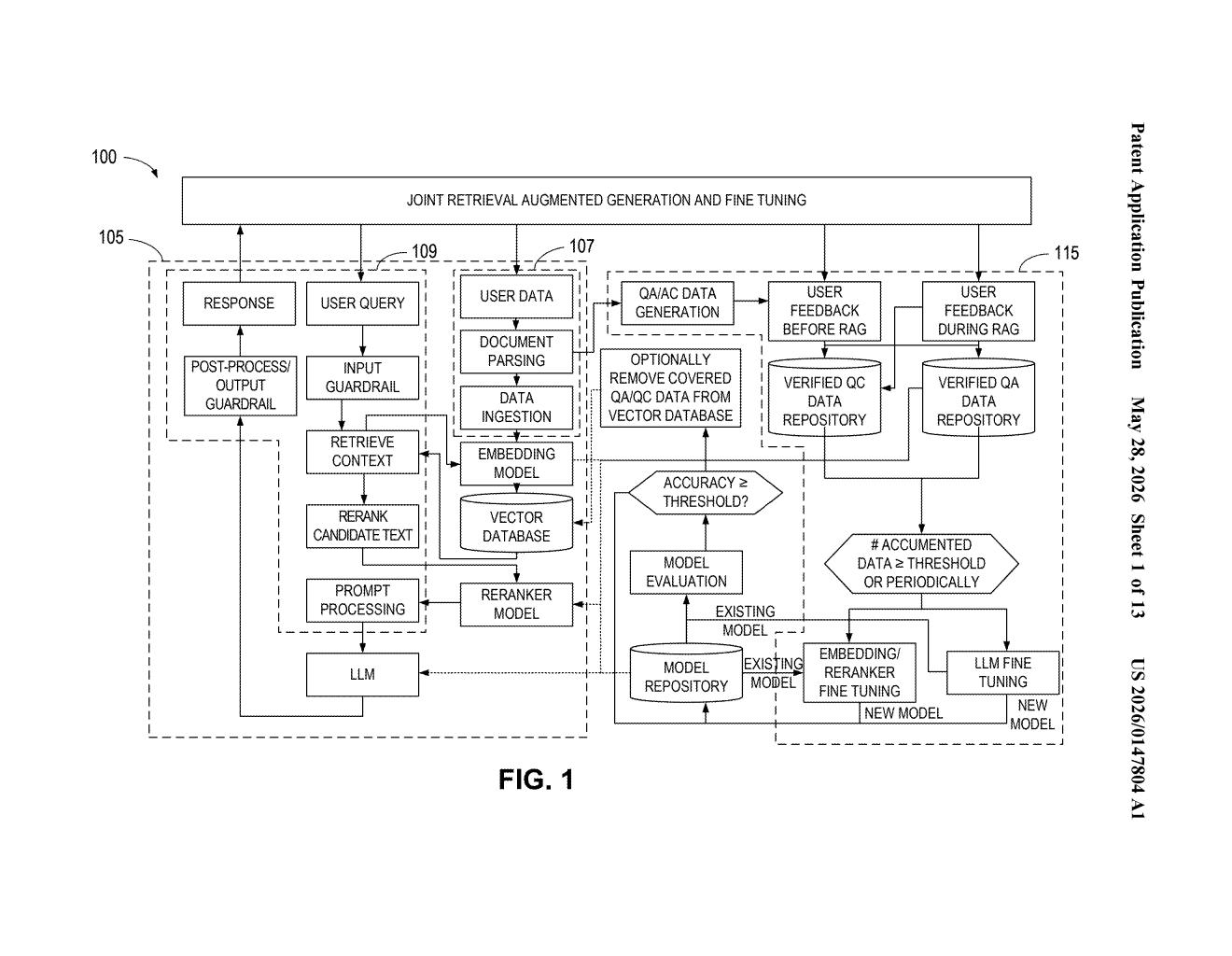
What Intel's self-improving RAG loop actually does
Imagine an AI assistant at your company that answers questions by searching a giant library of documents. Every time it finds a good answer, it has to look things up from scratch — which is slow and expensive. Intel's patent describes a system that fixes this by turning good answers into training data automatically.
Here's the loop: when the AI answers your question, the system logs that question alongside the relevant documents and the answer. Once enough of those pairs build up, it uses them to fine-tune the AI — essentially teaching it to remember what it previously had to look up. Once the model has genuinely learned that knowledge, the original documents can be deleted from the search database.
The result is an AI that gets more self-contained over time. Your retrieval library shrinks, queries get faster, and storage costs drop — all because the model absorbed the knowledge directly rather than having to hunt for it every time.
How the feedback cycle shrinks the vector database
The patent describes a bidirectional feedback loop between a Retrieval Augmented Generation (RAG) pipeline — where an AI answers queries by fetching relevant documents from a vector database — and a continuous fine-tuning workflow that consumes the output of those queries.
The system generates two types of training pairs automatically:
- Question-Answer (QA) pairs — the user's question paired with the model's verified response, used to fine-tune the LLM (the language model doing the answering)
- Question-Context (QC) pairs — the question paired with the retrieved document chunks, used to fine-tune the embedding and re-ranker models (the components that decide which documents to retrieve in the first place)
Both types of pairs are routed through an expert verification step before being stored in a fine-tuning repository. When accumulated data hits a predefined threshold, fine-tuning kicks off. If the resulting model beats a performance threshold on a validation dataset, it replaces the corresponding component in the live pipeline.
A key efficiency trick: once the LLM has demonstrably learned the content of specific documents, those documents are removed from the vector database. The patent also mentions LoRA (Low-Rank Adaptation) — a technique that fine-tunes only a small subset of model weights — enabling the process to run efficiently at low precision (INT4) without a meaningful accuracy hit.
What this means for enterprise AI infrastructure costs
The core tension in enterprise AI today is that RAG is expensive — big vector databases consume storage, retrieval adds latency, and every query has to repeat the same lookups. Fine-tuning solves that but requires curated training data that's hard to collect. Intel's system attacks both problems at once by making RAG generate its own fine-tuning dataset as a byproduct of normal operation.
For companies running internal AI assistants on proprietary document libraries, this matters a lot. If the system works as described, your AI infrastructure could become progressively leaner without any manual data labeling effort — the retrieval index shrinks as the model internalizes knowledge, and retrieval latency drops as a result. It also positions Intel's AI accelerator hardware (Gaudi, Xeon) as the natural home for this kind of continuous on-device or on-premises training loop.
This is genuinely clever systems thinking — the insight that RAG usage naturally produces fine-tuning data, and that fine-tuning can eventually obsolete parts of the RAG index, is clean and practical. It's not flashy research; it's the kind of infrastructure-level optimization that actually ships into enterprise products. Intel filing this suggests they're building it into their AI software stack (likely OpenVINO or their Gaudi software suite), and that's worth watching.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.