Nvidia Patents a Self-Correcting Training Loop for Self-Driving AI
Teaching a self-driving car to recover from a mistake is hard — but generating millions of those recovery moments synthetically, on demand, is a genuinely clever shortcut. That's exactly what Nvidia's latest patent is trying to do.
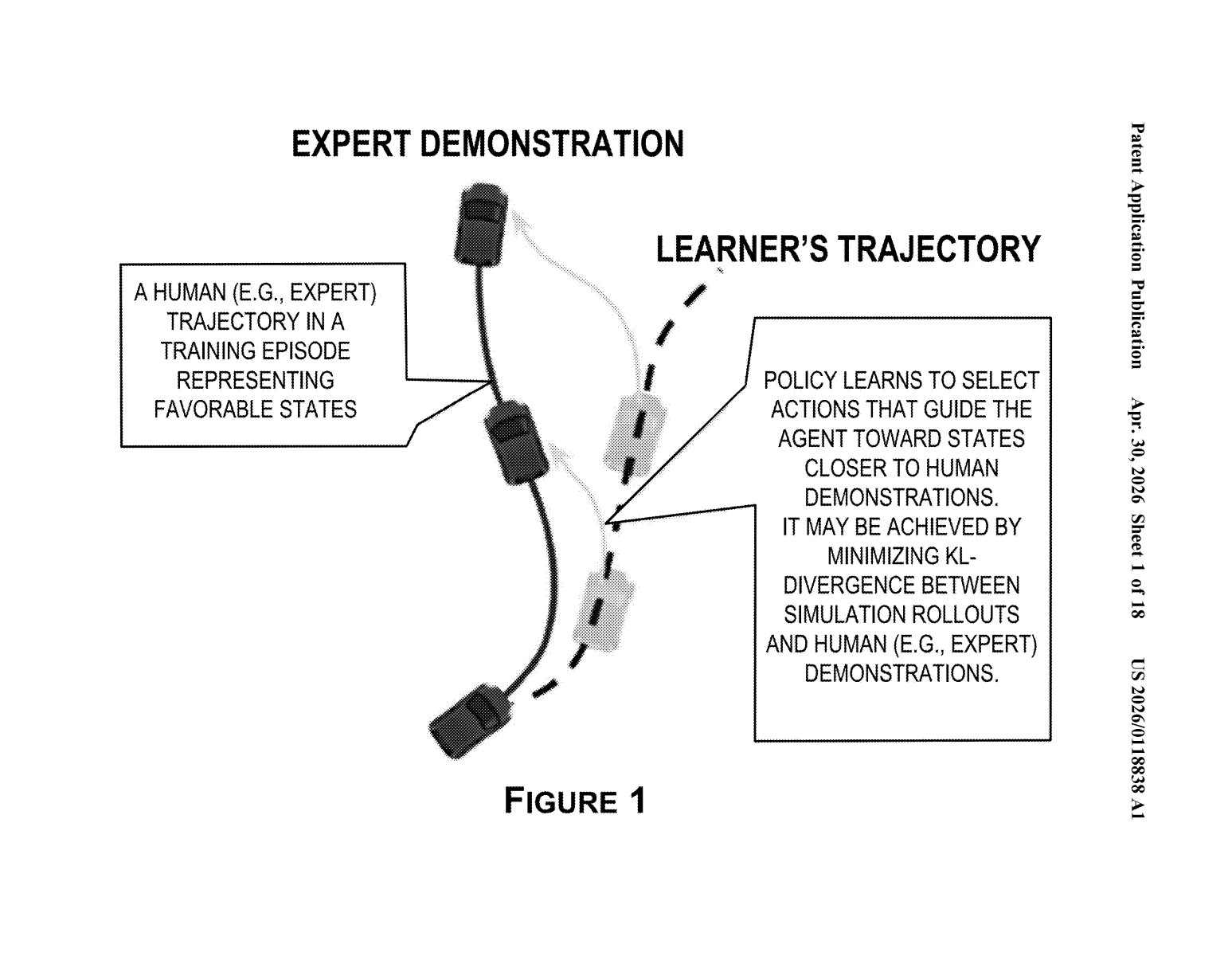
How Nvidia teaches self-driving AI to recover from bad decisions
Imagine you're learning to drive and your instructor keeps slamming on the brakes to show you what a near-miss feels like, then demonstrating how to regain control. That's exhausting and dangerous to do in the real world — but what if you could run that drill thousands of times in a simulator?
That's the core idea here. Nvidia's system lets a neural planner (the AI brain steering the car) make a mistake — or artificially drift off course — inside a simulation. Then a separate, more experienced AI takes over and steers the car back onto the right path. That recovery maneuver gets recorded and fed back to the neural planner as a lesson.
The result: the neural planner learns not just how to drive straight, but how to get back on track when things go sideways — all without a single real-world incident. It's a training loop that makes self-driving AI more resilient by design.
How the probabilistic simulation stack generates recovery data
The patent describes a system called a probabilistic state simulation stack — essentially a generative AI model that can simulate how a vehicle and its environment evolve over time, operating partly in a compressed mathematical space called a latent space (think of it as a compact internal representation of the world, rather than a full pixel-by-pixel rendering).
Here's the four-step training loop the patent lays out:
- Initialize the simulation with a real driving episode (actual sensor data from a real drive).
- Let the neural planner drive for a while — or deliberately inject a bad control command to force a drift from the ideal path.
- Hand off to the simulation stack's own navigation policy, which recovers from the drift and plays out the rest of the episode in latent space.
- Record that recovery trajectory and use it as training data to update the neural planner.
The key insight is that the generative DNN (deep neural network) inside the simulation stack was trained separately and already knows how to drive well. Its recovery maneuvers become ground truth — the gold-standard examples the neural planner should learn to mimic. This sidesteps a classic problem in autonomous vehicle training: you can collect millions of hours of normal driving, but near-miss recoveries are rare and dangerous to manufacture in the real world.
What self-correcting loops mean for autonomous vehicle reliability
Self-driving AI systems fail most often not in normal conditions but in edge cases — unexpected lane drift, slippery patches, a sudden obstacle. Getting recovery behavior right is arguably more important than getting cruise-control behavior right, and it's historically much harder to train for because real recovery data is scarce.
This patent points toward a more systematic way to close that gap. By using simulation to mass-produce exactly the kind of corrective data that's hardest to collect in the real world, Nvidia could give its DRIVE platform — and the automakers using it — a meaningful edge in handling the long tail of weird, dangerous situations that still trip up autonomous systems. For you as a passenger or driver, that translates to a car that's more likely to course-correct gracefully instead of freezing or overcorrecting.
This is a genuinely interesting systems-level idea, not just an incremental tweak. The move to use a more capable simulation-based policy to generate training signal for a weaker deployed policy is a neat bootstrapping trick — and it mirrors how human experts teach novices by modeling recovery, not just ideal behavior. Whether it ships in DRIVE Thor or stays in the research stack is the real question.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.