Nvidia Patents a Way to Stop AI Chips from Choking on Their Own Math
Matrix multiplication is the heartbeat of every AI model — and Nvidia is patenting a way to give software explicit control over how much of those results gets loaded at once, which could squeeze more performance out of the same silicon.
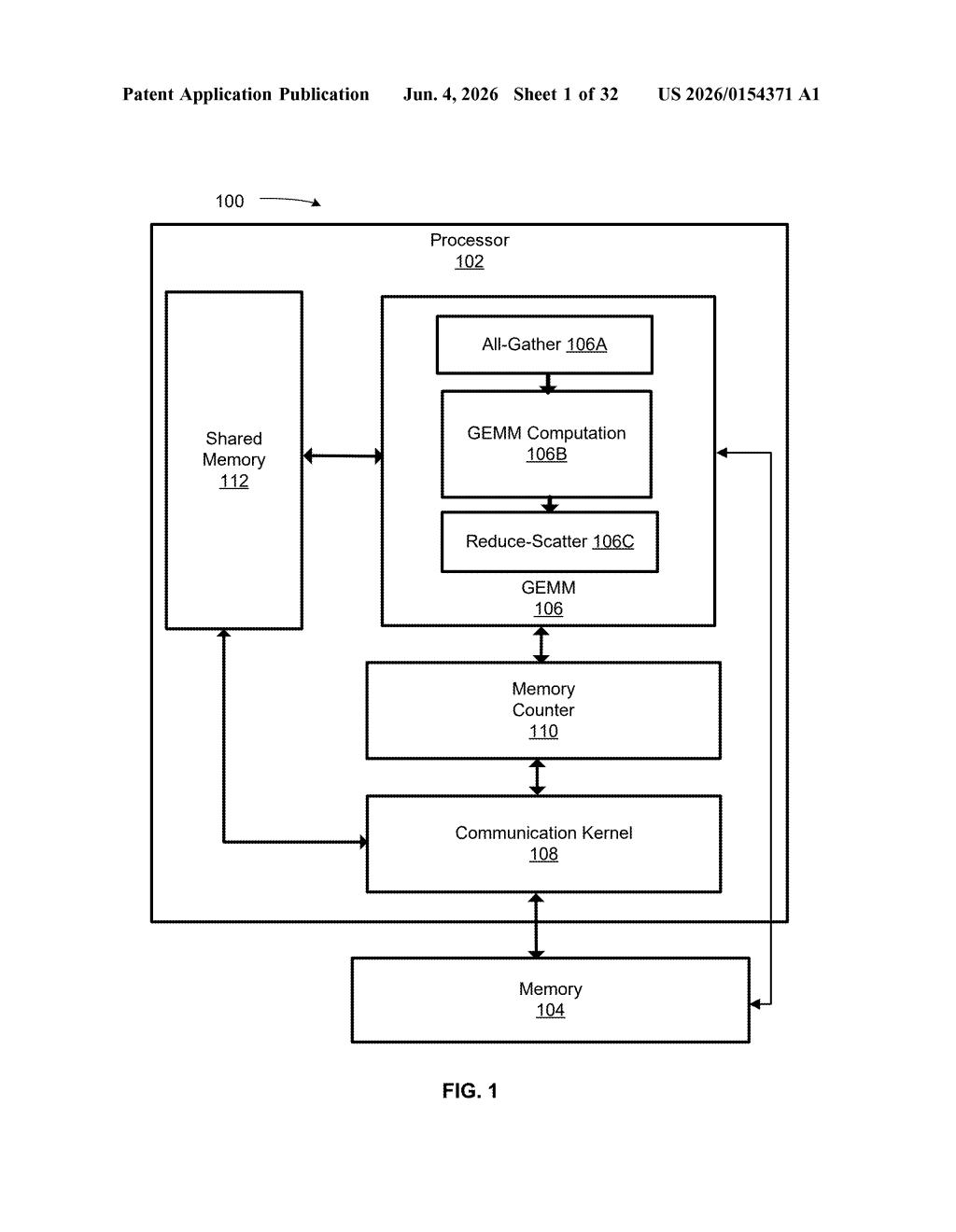
What Nvidia's partial matrix-load API actually does
Imagine you're carrying groceries from the car. You could haul every single bag in one trip and risk dropping them, or you could make two focused trips and place each bag exactly where it needs to go. GPUs face a similar tradeoff when doing the math that powers AI.
Nearly every AI model — from image generators to chatbots — relies on an operation called matrix multiplication: multiplying enormous grids of numbers together, over and over. The results of that math have to land somewhere in the chip's memory before the next step can begin. Right now, that landing process can be all-or-nothing.
Nvidia's patent describes an API — essentially a software command — that lets a developer (or the compiler acting on their behalf) tell the chip: "only bring in this portion of the result right now." That kind of fine-grained control can reduce wasted memory bandwidth and keep the pipeline flowing without unnecessary stalls.
How the GEMM partial-load instruction works
The patent centers on a new application programming interface (API) exposed at the processor level — meaning it's a formal instruction or call that software can issue directly to the hardware. The specific operation targeted is the GEMM (General Matrix Multiply), which is the foundational compute primitive behind neural network layers like linear projections, attention, and convolutions.
Typically, after a GEMM finishes, the full result tile is written to or loaded from a register file or shared memory before downstream operations can consume it. This patent proposes letting the API indicate which portion of those results should be partially loaded — think of it as a windowed or masked load rather than a full transfer.
- Partial loading: only the relevant slice of the output matrix is moved, reducing register pressure and memory traffic.
- API-level control: the mechanism is exposed as a programmable interface, so compilers or kernel authors can tune it per workload.
- One or more GEMM operations: the claim is written broadly to cover chained or batched matrix multiplications, not just single operations.
The practical effect is that the chip can pipeline or overlap work more aggressively — the next operation doesn't have to wait for a full result matrix to materialize before it can start consuming the part it actually needs.
What this means for AI training and inference throughput
For AI inference and training, GEMM throughput is often the binding constraint. Any mechanism that reduces unnecessary data movement between compute units and memory directly translates to lower latency and higher utilization of the GPU's tensor cores. At the scale Nvidia operates — data centers running thousands of H100s or Blackwell chips — even small efficiency gains per GEMM compound into meaningful cost and speed differences.
For developers writing custom CUDA kernels or using frameworks like cuBLAS, an explicit partial-load API would give finer control over how fused operations are structured. This kind of low-level handle is exactly what high-performance ML engineers optimize for when squeezing out the last few percent of throughput on a model.
This is unglamorous but genuinely important plumbing work. GEMM optimization is one of those areas where Nvidia has historically built durable competitive moats — small API-level improvements accumulate into the kind of performance gap that keeps customers locked into CUDA. It's not a headline feature, but it's the sort of thing that shows up quietly in a future CUDA toolkit release and makes benchmarks tick up.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.