IBM Patents a Decoder-Only System for Linking Plain-English Questions to Databases
Before an AI can turn your plain-English question into a SQL query, it has to figure out which tables and columns in a database are even relevant — and IBM's new patent tackles exactly that step with a leaner, decoder-only approach.
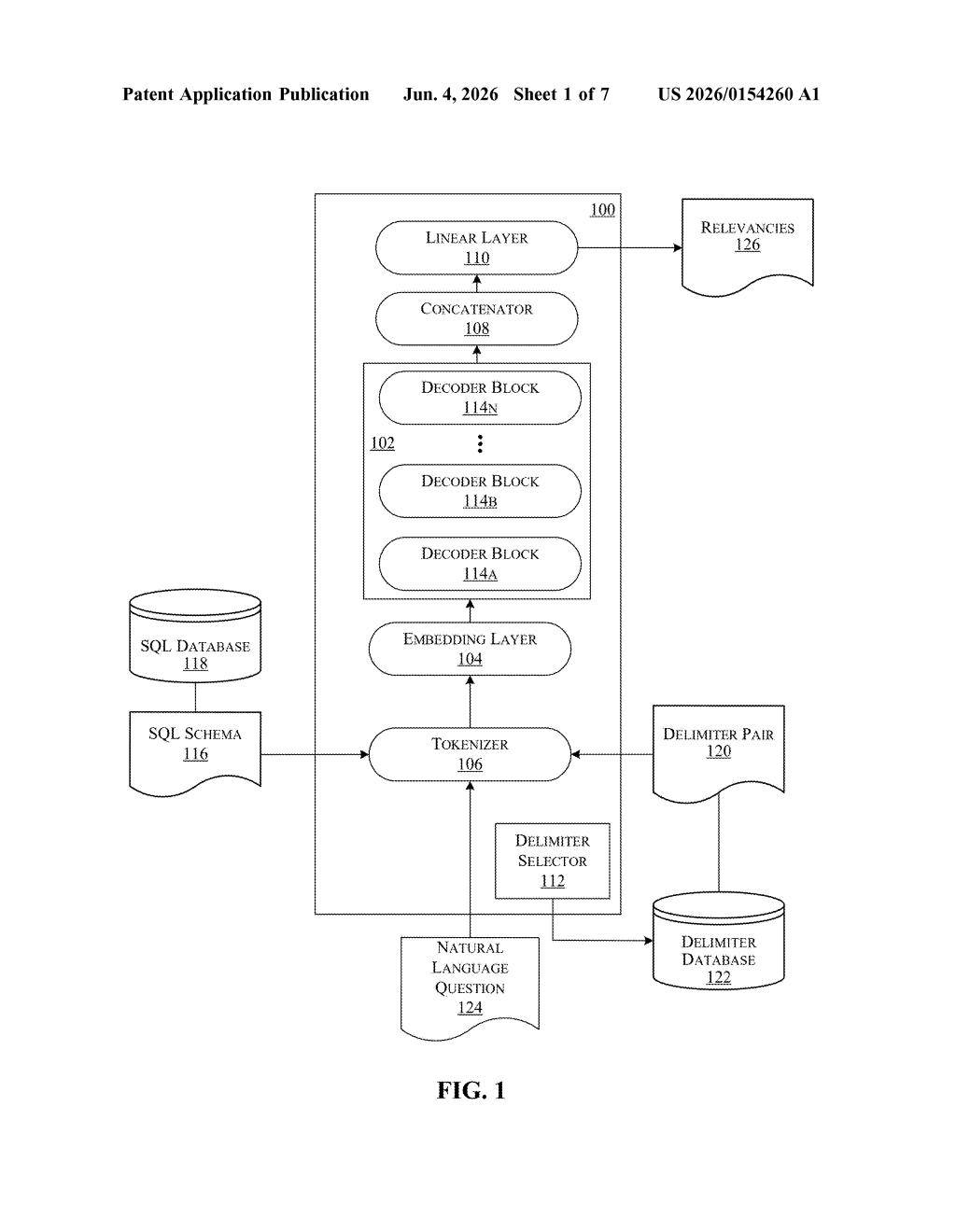
How IBM's text-to-SQL matching actually works
Imagine you ask a business intelligence tool, "Which sales reps closed the most deals last quarter?" Behind the scenes, the AI has to search through a database with hundreds of tables and thousands of columns to figure out which ones — maybe sales_rep_id, deal_closed_date, and revenue — are actually relevant before it can write a SQL query. That matching step is called schema linking, and getting it wrong means the query fails.
IBM's patent describes a way to do this matching using a decoder-only language model — the same architecture style behind GPT-style AI — instead of the encoder-based models that have traditionally handled this task. The system wraps each candidate column or table name in special delimiter tokens, runs everything through the model, then scores relevancy by combining the vector representations at those delimiters.
The practical payoff is that you could use a single, unified model architecture for both the schema-linking step and the SQL generation step, potentially making text-to-SQL pipelines simpler to build and deploy.
How the decoder scores each candidate table and column
The system takes three inputs and processes them together: the full SQL schema (the database's structure — its tables and columns), a natural language question from the user, and a set of candidate schema elements (individual table names, column names, etc.) that might be relevant to answering that question.
Each candidate is tokenized — broken into subword tokens — and wrapped with a first token (initial delimiter) and a last token (end delimiter), essentially bookending each candidate with special markers. All of this — schema, question, and delimited candidates — is passed through a decoder-only transformer model (think GPT-style, where each token only attends to tokens that came before it, not bidirectionally like BERT).
The key scoring trick is what IBM calls concatenated vectors: for each candidate, the system takes the model's output vector at the first delimiter token and the output vector at the last delimiter token, then concatenates them into a single vector. That combined representation is used to produce a quantitative relevancy score for each candidate — essentially a ranking of which tables and columns are most likely needed to answer the question.
This matters architecturally because most prior schema linking work used encoder-only models (like BERT), which are less compatible with modern generative LLMs. Using a decoder-only backbone means the schema-linking module could potentially share weights or be integrated more cleanly with the SQL generation model downstream.
What this means for AI-powered database querying
Text-to-SQL is one of the more practical near-term applications of LLMs in enterprise software — it lets non-technical users query databases in plain English. But the schema-linking step has historically been a weak link: get it wrong and the generated SQL references columns that don't exist or misses the ones that do. IBM's approach here is less about a big accuracy leap and more about architectural alignment — making schema linking compatible with the decoder-only models that dominate the current LLM landscape.
For enterprise customers building natural language database interfaces — think business intelligence tools, internal analytics chatbots, or customer data platforms — a tighter, more unified pipeline could mean fewer moving parts and easier fine-tuning on proprietary schemas. IBM's watsonx platform is the obvious deployment target.
This is solid, focused engineering work on a genuinely tricky subproblem in text-to-SQL pipelines. It's not a flashy AI patent — there's no new model architecture or training trick — but the decoder-only framing is a real and practical contribution because it closes the architectural mismatch between schema linking and modern generative models. Worth paying attention to if you build enterprise data query tools.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.