Nvidia Patents an API That Batches Tensor Math Into a Single GPU Call
Every time a GPU switches between separate math operations, there's overhead. Nvidia's new patent describes an API designed to collapse a chain of tensor operations into one coordinated call — potentially shaving time off the kind of workloads that run millions of times per second in AI training.
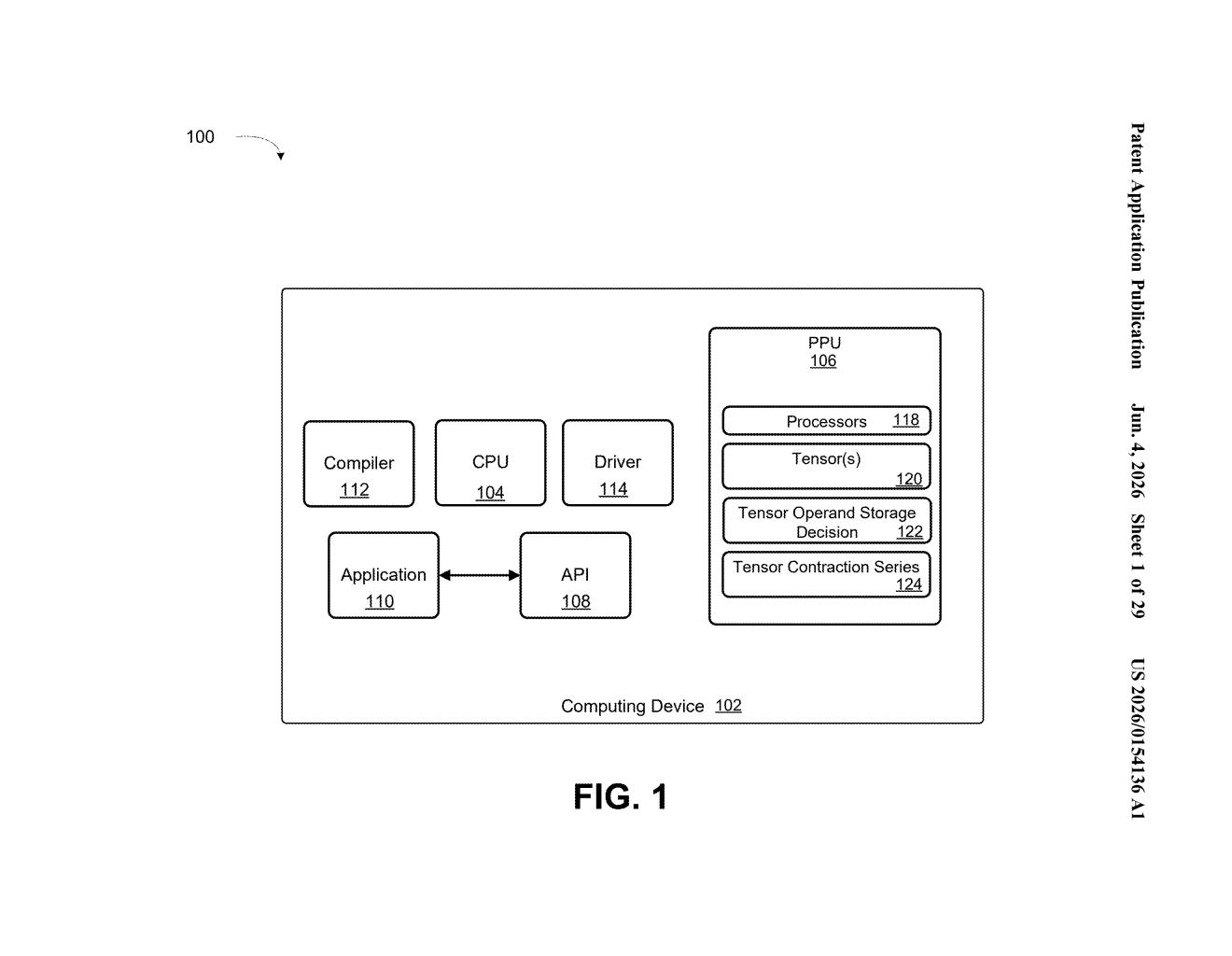
What Nvidia's tensor-batching API actually does for GPUs
Imagine you're baking a cake and every time you need a new ingredient, you have to walk back to the store individually — flour, then eggs, then sugar, one trip each. That's roughly what happens when a GPU processes a long chain of math operations one at a time. Each round-trip has overhead, and those costs add up fast.
Nvidia's patent describes a programming interface (essentially a standardized way for software to talk to hardware) that lets developers describe a series of tensor operations — the heavy matrix math at the heart of AI — all at once. Instead of handing each operation to the GPU separately, you declare all the inputs, shapes, and connections upfront, and the hardware can plan the whole sequence together.
The benefit is that the GPU doesn't have to keep stopping and restarting between steps. For AI workloads that stack dozens or hundreds of these operations back to back, that kind of batching can meaningfully cut down on wasted cycles.
How the API stores operands across chained tensor contractions
At the core of this patent is an API for tensor contractions — a tensor contraction is a generalization of matrix multiplication, the fundamental operation behind most neural network layers. When you multiply two matrices together, you're doing a simple contraction; more complex AI operations chain many of these together across higher-dimensional arrays.
The patent describes circuits (hardware logic inside a processor) that expose an API call capable of accepting parameters for two or more tensor contractions at once. Crucially, it stores the operands (the input data arrays) and their dimension descriptors (the shape metadata that tells the hardware how the data is laid out) for the entire sequence before execution begins.
This matters because of how modern GPU programming typically works: software calls an operation, waits for a result, then issues the next call. Each call involves driver overhead, memory bandwidth negotiation, and kernel launch costs. By pre-registering the full chain:
- The hardware or driver can plan memory reuse across steps
- Intermediate results may never need to leave fast on-chip memory
- The scheduler can overlap or fuse operations that would otherwise run sequentially
The patent is framed broadly — it covers storing those parameters, which suggests the key innovation is in the API contract itself, not a specific fusion algorithm.
What this means for AI model training and inference speed
For AI researchers and ML engineers, tensor operation overhead is a real, frustrating bottleneck. Training large models involves chaining thousands of these contractions per forward and backward pass, and anything that reduces the per-operation cost compounds into significant time and energy savings at scale. Nvidia's CUDA ecosystem already has libraries like cuBLAS and cuTENSOR — this patent suggests a higher-level API layer on top that makes batching these sequences easier to express.
For you as an end user, this kind of plumbing rarely shows up with a brand name, but it's the sort of improvement that quietly makes the next generation of AI models cheaper to train — and therefore faster to ship.
This is deep infrastructure work — the kind of patent that won't headline a GTC keynote but quietly underpins everything above it. The claim is narrow (just storing parameters for a sequence of contractions), which makes the actual novelty hard to assess from the outside, but Nvidia filing in this space signals they're investing in making chained tensor math a first-class concept at the API layer rather than a library-level workaround. That's worth watching.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.