Google Patents a System That Auto-Generates AI Explanations for the Parts of Documents People Struggle With
Google is patenting a system that watches how people interact with documents — where they slow down, re-read, or drop off — and automatically generates AI explanations for exactly those trouble spots.
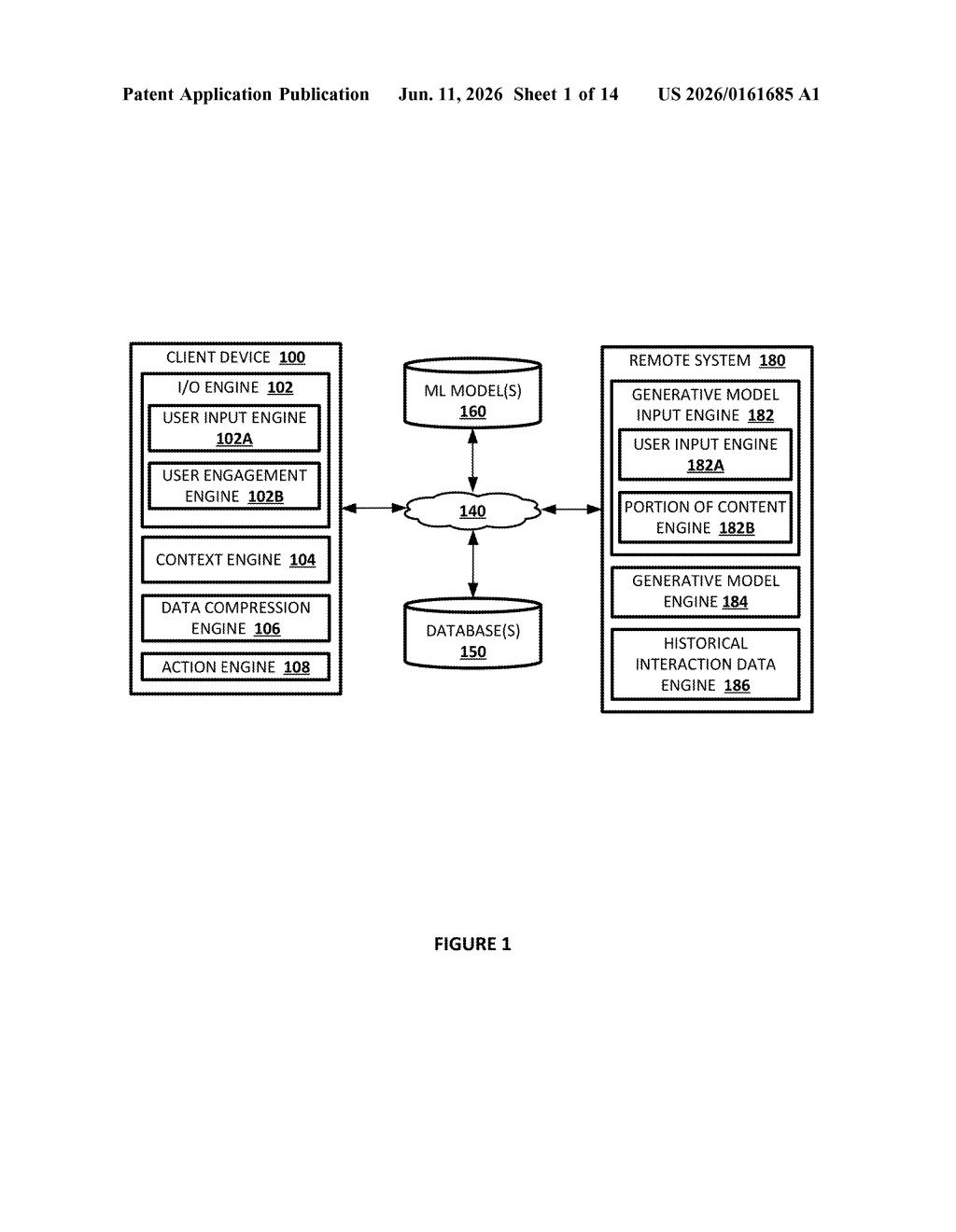
What Google's auto-AI annotation system actually does
Imagine you open a lengthy policy document, a research report, or a contract. You're not the first person to read it — thousands of others have too, and many of them got stuck on the same dense paragraph in section four. What if the document could figure that out on its own and quietly attach an AI-written explanation right where you need it?
That's what Google is building here. The system monitors how real users interact with a document over time — where they pause, re-read, highlight, or abandon it — and uses that behavioral data to identify the sections that trip people up most. Then it automatically feeds those sections to an AI model, which generates a plain-English explanation or summary. When you open the same document, that AI-generated note is already waiting for you beside the confusing part.
You don't have to ask for help, and whoever wrote the document doesn't have to rewrite it. The AI annotation appears automatically, tied to the specific passage it's explaining.
How the system picks sections and generates the content
The patent describes a two-stage pipeline. In the first stage, a backend system continuously processes historical interaction data — logs of how previous users engaged with an electronic document. The system looks for patterns in those logs: did users re-read a particular section repeatedly? Did engagement drop sharply at a certain paragraph? These behavioral signals flag specific portions of the document as candidates for AI-generated content.
Once a portion is flagged, the system constructs a prompt that includes the actual text of that section and sends it to a generative model (think a large language model similar to Gemini). The model produces an explanation, summary, or other supplemental content for that passage.
In the second stage, when a new user opens the document on any client device, the system surfaces that pre-generated AI content alongside the document — displayed near the relevant section with a clear label indicating it's AI-generated commentary, not part of the original text.
The patent also covers a variation using real-time user engagement signals (how long you personally linger on a section) to trigger on-the-fly generation if a pre-generated note doesn't already exist. The architecture is designed to work at the document-platform level, not requiring authors to do anything manually.
What this means for Google Docs and Workspace users
For anyone who works with long, complex documents inside Google Workspace — legal teams, researchers, enterprise employees — this could mean AI annotations that arrive before you even know you're confused. Rather than manually asking an AI chatbot to explain a clause, the system anticipates the need based on how thousands of people before you read the same document.
Strategically, this positions Google's document tools as actively intelligent rather than passively storing text. It also creates a feedback loop where the more a document is read, the better its AI annotations get — giving Google Docs a structural advantage that's hard for standalone AI writing assistants to replicate, since they don't have access to that crowd-sourced engagement history.
This is a genuinely clever application of behavioral analytics to AI content generation — using the crowd's confusion as a signal rather than relying on individual prompts. It's most interesting as a Workspace enterprise play: if Google can make dense internal documents self-annotating, that's a real productivity argument against Microsoft 365 Copilot. The core idea is straightforward enough that the patent faces real prior-art pressure, but the implementation details around interaction-data triggering give it some defensible specificity.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.