Samsung Patents a Transcription Method That Reads the Screen Before It Listens
Most transcription tools only listen. Samsung's new patent describes a system that also reads whatever text is visible on screen, then uses that visual context to make the audio transcription more accurate.
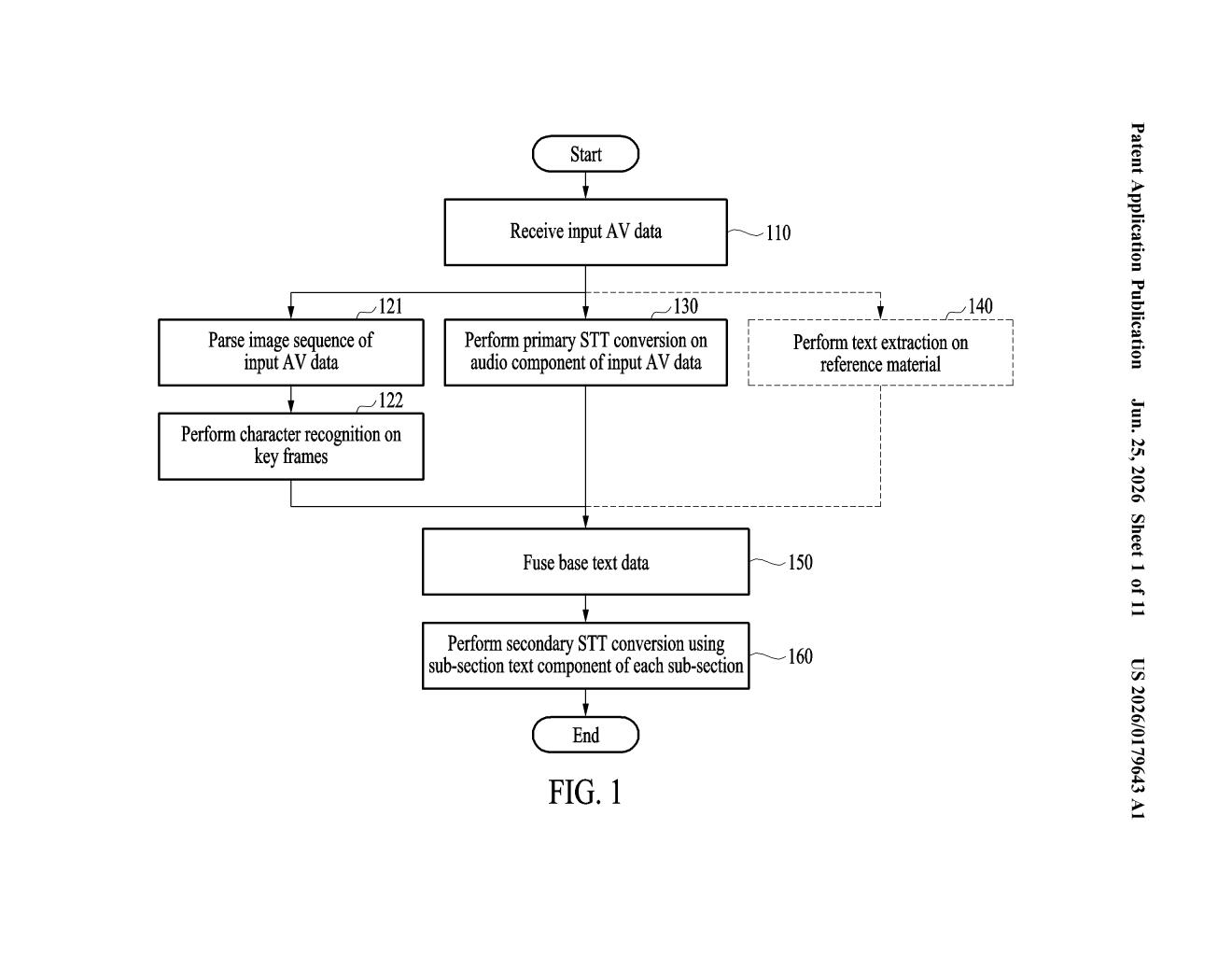
How Samsung's combined video-and-audio transcription works
Imagine you're recording a lecture where the professor writes key terms on a whiteboard. A standard voice-to-text tool might stumble over technical words it has never encountered, but if it could also read the whiteboard, it would know exactly what word to expect.
That's the core idea here. Samsung's patent describes a two-step process: the device first scans each video frame for visible text, like slides, signs, or on-screen labels, and simultaneously runs a first-pass transcription of the audio. It then combines both sources into keyword hints, organized by which part of the video they came from.
Those keywords feed into a second, more careful audio transcription pass. Because the system already knows the vocabulary in play for each segment, it can fill in words that a plain speech-to-text engine might mangle or miss entirely. Think of it as giving the transcription tool a cheat sheet before the test.
How the two-pass STT pipeline uses visual context
The patent describes a two-pass speech-to-text (STT) pipeline that processes video and audio together rather than treating them as separate streams.
Pass one runs two operations in parallel:
- Optical character recognition (OCR) scans each video frame for visible text, such as presentation slides, captions, or product labels.
- Primary STT transcribes the audio into a rough first-draft text.
The system then divides the video into segments using inter-frame similarity (a measure of how much consecutive frames visually differ, used to detect scene or slide changes). For each segment, it merges the OCR output and the first-pass audio transcript into a set of keywords that capture the vocabulary specific to that part of the video.
Pass two reruns the audio transcription, but this time it supplies those per-segment keywords as context. This is the core claim: informed by what the camera could read, the second transcription pass is less likely to substitute a wrong word for a domain-specific term it didn't recognize the first time.
The output is a time-aligned transcript where each section of audio has been transcribed with knowledge of the visual vocabulary present at that moment.
What this means for auto-captioning on Galaxy devices
Auto-captioning already exists on Samsung Galaxy devices, but accuracy drops sharply when speakers use technical, medical, legal, or non-English vocabulary that a general-purpose speech model wasn't trained on. This approach could reduce those errors without requiring a specialized model for every domain, because the visual context provides the missing vocabulary on the fly.
For you as a user, that could mean better transcripts when you record a conference talk, a doctor's appointment with printed materials visible, or a foreign-language video with on-screen subtitles. The system is also structured by video segment, so even a long recording with topic shifts could stay accurate throughout rather than degrading as context changes.
This is a genuinely practical improvement on a problem every auto-caption user has hit: the transcript looks fine until a speaker says something specific and the tool guesses wrong. Using visible on-screen text as a vocabulary hint is a logical fix, and structuring it segment-by-segment rather than globally is the right engineering call. Whether Samsung ships this in a live transcription feature or buries it in a cloud API is the real question.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.