Samsung Patents a System That Teaches AI to Describe Images in Plain Text
Samsung has patented a method for automatically turning non-text content — think photos, audio, or sensor data — into structured text descriptions by routing the job through a team of specialized AI models working in sequence.
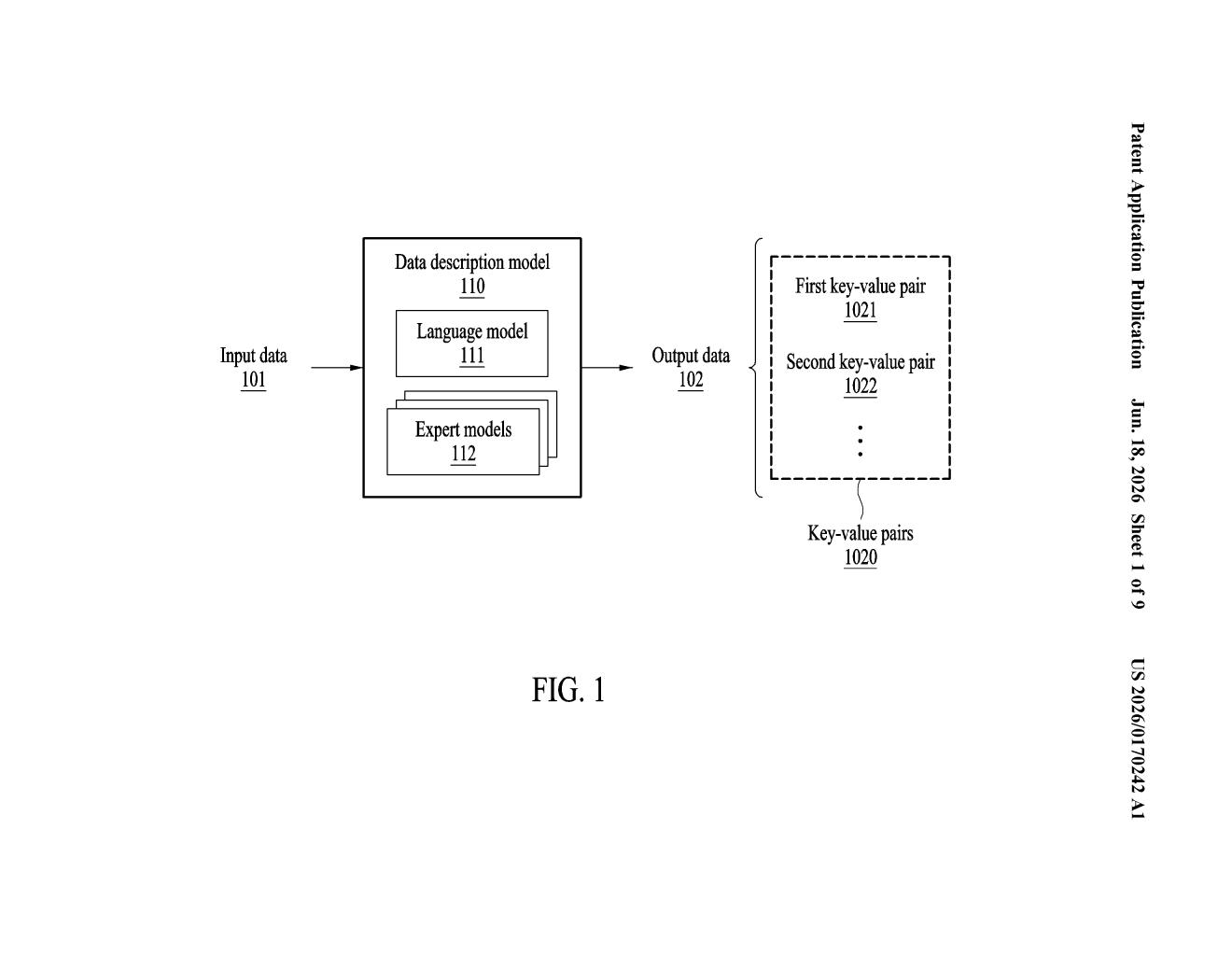
What Samsung's image-to-text description system actually does
Imagine you hand someone a photograph and ask them to describe it in a structured form, like filling out a form with labels: 'subject: a dog,' 'background: a park,' 'lighting: sunny.' That's essentially what Samsung's patent describes — but done automatically by a chain of AI models.
Here's how it works for you as a user: your image (or audio clip, or any non-text data) goes in, and what comes out is a neat, organized text description built from labeled pairs — a category name and its matching detail. The system figures out which category to describe next, picks the right specialist AI for that job, gets an answer, and then loops back to decide what to describe next.
This kind of structured output could make images searchable, help visually impaired users understand visual content, or feed clean data into other AI systems that only understand text.
How the language model and expert models trade off tasks
The patent describes a pipeline where a language model (the kind of AI that reads and generates text) acts as a coordinator. It looks at non-text input — an image, for example — and decides the first key to describe: essentially, the first category worth capturing, like 'scene type' or 'dominant color.'
That key gets handed to a specialist 'expert' model chosen specifically for that kind of question. The expert returns a value — the actual answer. Together, the key and value form one labeled pair in the final output.
The language model then looks at that first pair and decides what the next key should be, picks a new expert, gets another value, and so on. This back-and-forth continues until the full description is assembled.
- The language model drives sequencing — it decides what to describe and in what order.
- Expert models do the heavy lifting for each specific sub-task (color detection, object recognition, etc.).
- The final output is a structured key-value format (like a labeled list), which is easy for other software systems to read and process.
What this means for AI search and accessibility tools
Turning images or audio into structured, machine-readable text is a foundational problem in AI. Search engines, accessibility tools, content moderation systems, and data pipelines all depend on being able to describe visual content in words. Samsung's approach — using a language model to orchestrate a team of specialist models rather than forcing one model to do everything — is a practical architectural choice that could produce more accurate, detailed descriptions than a single general-purpose model alone.
For Samsung devices specifically, this kind of system could power on-device captioning, photo search in the Gallery app, or richer metadata for files stored on Galaxy phones. It also positions Samsung in a growing field where companies are racing to make AI that can bridge the gap between images and language.
This is a solid, workmanlike patent covering a real engineering problem — how do you get AI to generate structured descriptions of images reliably? The coordinator-plus-specialists architecture is a sensible approach, not an obvious one, and Samsung filing this suggests the company is investing seriously in on-device multimodal AI rather than just buying access to someone else's API. It's not flashy, but it's the kind of infrastructure patent that pays off quietly across a whole product line.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.