IBM Patents a System for Automatically Matching ML Models to Edge Hardware
Running AI at the edge is messy — not every device can handle every model. IBM's new patent describes a system that automatically figures out which machine learning model fits which edge node, then ships it there on demand.
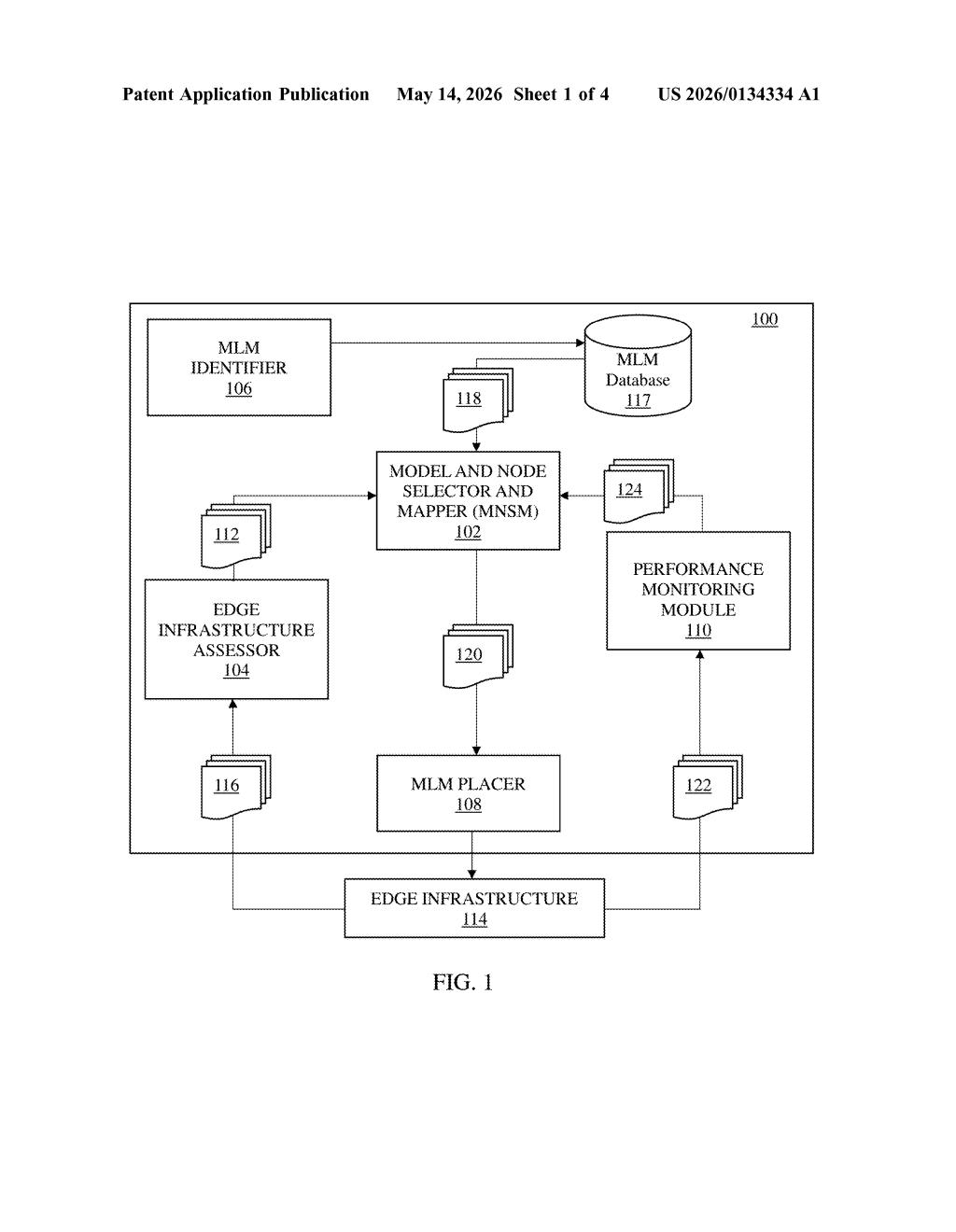
What IBM's edge ML deployment system actually does
Imagine you have dozens of small computers scattered across a factory floor, a retail chain, or a telecom network. Some are powerful, some are stripped-down. Now imagine you want to run an AI model on one of them to analyze sensor data or video — but you're not sure which machine can handle it. That's the edge AI deployment problem.
IBM's patent describes a system that scans all your edge nodes, checks what each one can handle (CPU, memory, accelerators, etc.), and compares that against a library of available AI models and the demands of whatever task you need done. It then picks the best-fit model for the best-fit node and automatically deploys it over the network.
Think of it like a smart job scheduler, but for AI. Instead of a human engineer manually pushing the right model to the right machine, this system handles the matchmaking and delivery automatically — and keeps watching performance after the fact.
How IBM's model-node matcher selects and deploys MLMs
The patent describes a pipeline with four main components working together:
- Edge Assessor — continuously detects the processing capabilities (compute, memory, hardware accelerators) of each node in the edge infrastructure.
- Model and Node Selector and Mapper (MNSM) — compares node profiles against a library of ML model profiles and the requirements of a given task, then picks the best model-node pairing.
- MLM Placer — handles the actual deployment, pushing the selected model over a data communication network to the target edge node.
- Performance Monitoring Module — watches what happens after deployment so the system can adapt or reassign if performance degrades.
The core idea is profile-based matching: each ML model has a stored profile describing what resources it needs, and each edge node has a detected capability profile. The system does a structured comparison rather than a one-size-fits-all deployment.
This is essentially an automated operations layer (often called MLOps) for heterogeneous edge environments — where nodes wildly differ in capability, unlike a homogeneous cloud cluster.
What this means for AI workloads at the network edge
Edge AI is growing fast in industrial, retail, and telecom settings, but deploying models to heterogeneous hardware is still largely a manual, brittle process. A system that automates capability detection and model-node matching could meaningfully reduce the operational burden of running AI outside the data center.
For IBM, this fits squarely into its hybrid cloud and AI infrastructure strategy — particularly around platforms like IBM Edge Application Manager. If this kind of dynamic dispatch can be productized, it makes edge AI more accessible to enterprises that don't have dedicated ML engineers managing every deployment. You get smarter edge infrastructure without needing to babysit it.
This is solid infrastructure plumbing — not flashy, but genuinely useful for anyone running ML at the edge at scale. The four-component architecture is well-scoped and the profile-matching approach is sensible. The risk is that it's also fairly obvious to practitioners in this space, which could make it a tough patent to defend against prior art challenges.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.