Nvidia Patents a 3D-Grounded Video Generation System for Precise Camera Control
Most AI video generators are essentially very sophisticated guessers — they hallucinate geometry and let objects flicker between frames. Nvidia's new patent tries to fix that by anchoring the entire generation process to a real 3D representation of the scene.
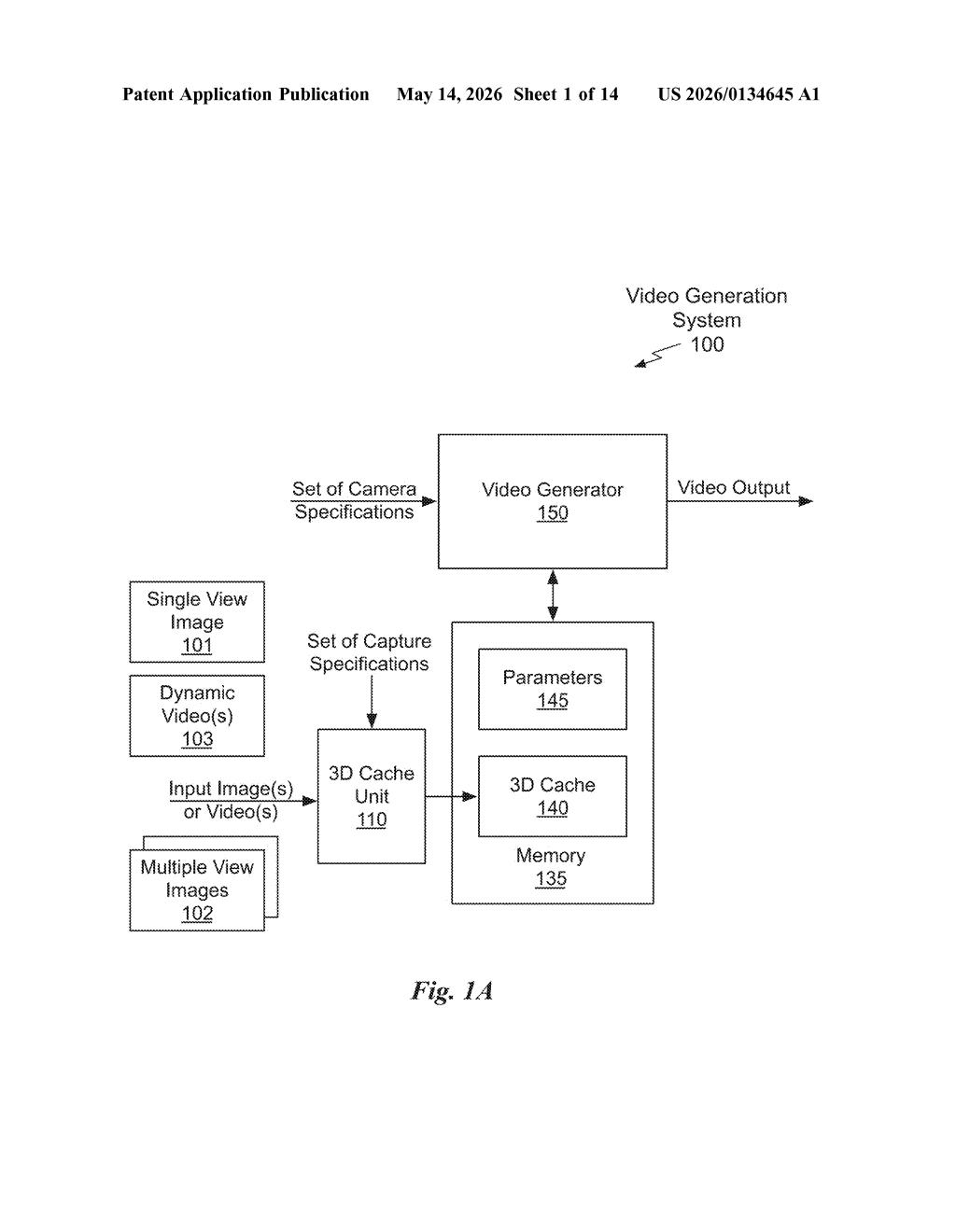
What Nvidia's 3D-anchored video generator actually does
Imagine you're a filmmaker who wants to reshoot a scene from a completely different camera angle — but you only have the original footage. Today's AI video tools would try to fill in the missing view, and the result usually looks unstable: objects change shape, lighting shifts weirdly, and the whole thing feels like a dream sequence.
Nvidia's patent describes a smarter approach. Instead of generating new video from scratch, the system first builds a 3D model of the scene from your existing images or video frames. Think of it like reconstructing a little 3D diorama from photos. Then, when you ask it to generate video from a new camera angle, it renders that diorama first — filling in what the camera should see — and uses that as a guide for the AI.
The result is video that stays consistent: objects don't change shape between frames, and the camera moves feel physically grounded. You can also specify things like focal length, depth of field, or cinematic lens effects as part of the input — the system bakes all of that into the output automatically.
How the 3D cache drives Nvidia's diffusion video pipeline
The core of this patent is a pipeline that connects 3D scene reconstruction with a video diffusion model (the type of AI that generates video frame-by-frame by iteratively refining noise into imagery).
Here's how the pieces fit together:
- 3D Cache Construction: The system takes two or more 2D images of a scene and computes a compact 3D representation — essentially a structured cache of geometry and appearance data for that environment.
- Camera-Controlled Rendering: Given a set of camera specifications (position, orientation, focal length, etc.), the 3D cache is rendered into a frame sequence and a mask sequence. The mask identifies pixels that are missing or uncertain — areas the camera couldn't see in the original images.
- Latent Fusion: Each rendered frame is encoded into a latent representation (a compressed mathematical description used by diffusion models). Time-synchronized latent frames are then fused together — merging what the 3D render knows with what the AI needs to fill in.
- Video Generation: The fused latents are processed by the video diffusion model to produce the final output frames, with the 3D render acting as a strong structural prior (a constraint that keeps the AI honest about geometry and continuity).
The mask sequence is particularly clever — it tells the diffusion model exactly where it has reliable 3D data versus where it needs to improvise, so it doesn't waste capacity second-guessing geometry it already knows.
What this means for AI video and virtual production workflows
The biggest unsolved problem in AI video generation today is temporal consistency — keeping objects looking the same from frame to frame, especially under camera movement. This patent directly attacks that problem by grounding generation in explicit 3D geometry rather than letting the model infer it implicitly. For use cases like virtual production, game cinematics, or visual effects previsualization, that's a meaningful step up from current tools.
Nvidia's positioning here is also strategic. The company already supplies the hardware that runs most AI video pipelines, and a proprietary 3D-grounded generation method would give its Omniverse and content-creation platforms a differentiated capability. If this ships in a product, it could tighten the feedback loop between 3D scene authoring and AI video generation in ways that matter for studios and developers.
This is genuinely interesting work, not just incremental. The insight of separating 'what the 3D data knows for certain' from 'what the AI needs to hallucinate' — and encoding that distinction explicitly via masking — is a clean architectural choice that addresses a real and annoying failure mode. The patent has a strong team behind it (several authors have published influential work on neural rendering and 3D reconstruction), and the core idea is specific enough to be worth watching.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.