Google Patents a Multi-AI Bidding System Where LLMs Compete and Collaborate on Tasks
Instead of routing your question to a single AI, Google's new patent describes a system where multiple language models raise their hands, compete to answer, and then work together to give you a better result.
How Google's AI assistants bid on your questions
Imagine you ask a question and, behind the scenes, a panel of specialists each decides whether they're the right person to answer — then the best one takes the lead while the others chime in with their own perspectives. That's essentially what this Google patent describes for AI assistants.
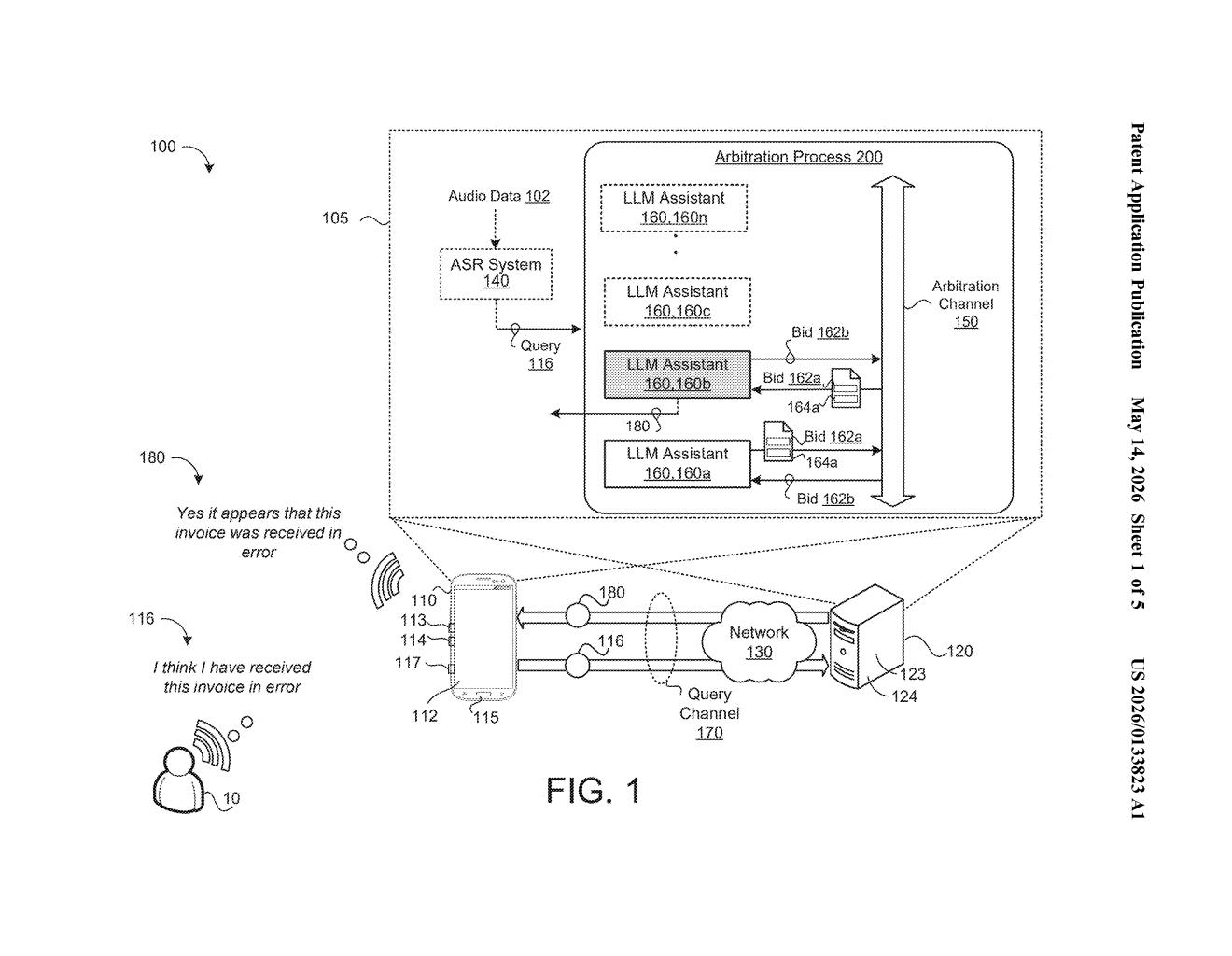
When you send a query, multiple LLM-based assistants each independently evaluate whether they're capable of handling it. The ones that think they can submit a volunteer bid — basically raising their hand. One assistant is then selected from that pool to take the lead.
But here's the twist: the selected assistant doesn't just go it alone. It asks the other assistants that also volunteered to weigh in — and uses their responses as extra context before generating your final answer. Think of it as a lead writer consulting subject-matter experts before hitting publish.
Inside Google's LLM arbitration and collaboration channel
The patent describes a coordination layer called an arbitration communication channel — a shared messaging bus that lets multiple LLM-based assistants talk to each other during the process of answering a query.
The process has two main phases:
- Bidding phase: Each available LLM assistant processes the incoming query and decides whether it can handle the task. If it believes it can, it broadcasts a volunteer bid over the arbitration channel to all the other assistants in the pool.
- Selection phase: From the subset of assistants that volunteered, one is chosen to be the lead — the patent doesn't fully specify the selection criteria, which is common in broad filings.
- Collaboration phase: The selected assistant then solicits collaboration inputs from the other volunteers — essentially asking them, "how would you have answered this?" — and incorporates those perspectives into a final answer.
The design is notably decentralized: assistants self-select rather than being dispatched by a central router. The arbitration channel acts more like a group chat than a dispatcher queue. This structure could make it easier to add or swap out specialized models without redesigning the whole pipeline.
What multi-LLM arbitration means for Google Assistant
For Google, this is architecturally interesting because it formalizes a way to blend multiple specialized models — imagine one assistant optimized for code, another for factual lookup, another for creative tasks — without a hard-coded routing table deciding who does what. The models themselves decide.
For you as a user, the practical payoff would be answers that are more robust because they're cross-checked by multiple AI perspectives before you ever see them. It also gives Google a framework for mixing proprietary models with potentially third-party or task-specific ones, which matters a lot as the AI assistant market fragments into specialized agents.
This is a genuinely clever architectural idea — letting models self-nominate rather than relying on a centralized dispatcher is a cleaner design that scales better as the number of specialized LLMs grows. The collaboration step is the real differentiator: it's essentially a built-in peer review loop before the answer ships. Whether Google can make the latency acceptable in a real product is the harder engineering question this patent doesn't answer.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.