Qualcomm Patents Technology That Catches Its Own AI Errors to Speed Up Responses
Qualcomm has filed a patent for a technique that lets a single AI model draft its own answer in advance, check how wrong that draft was, and use both the draft and the error signal to produce a better final response — all in one pass.
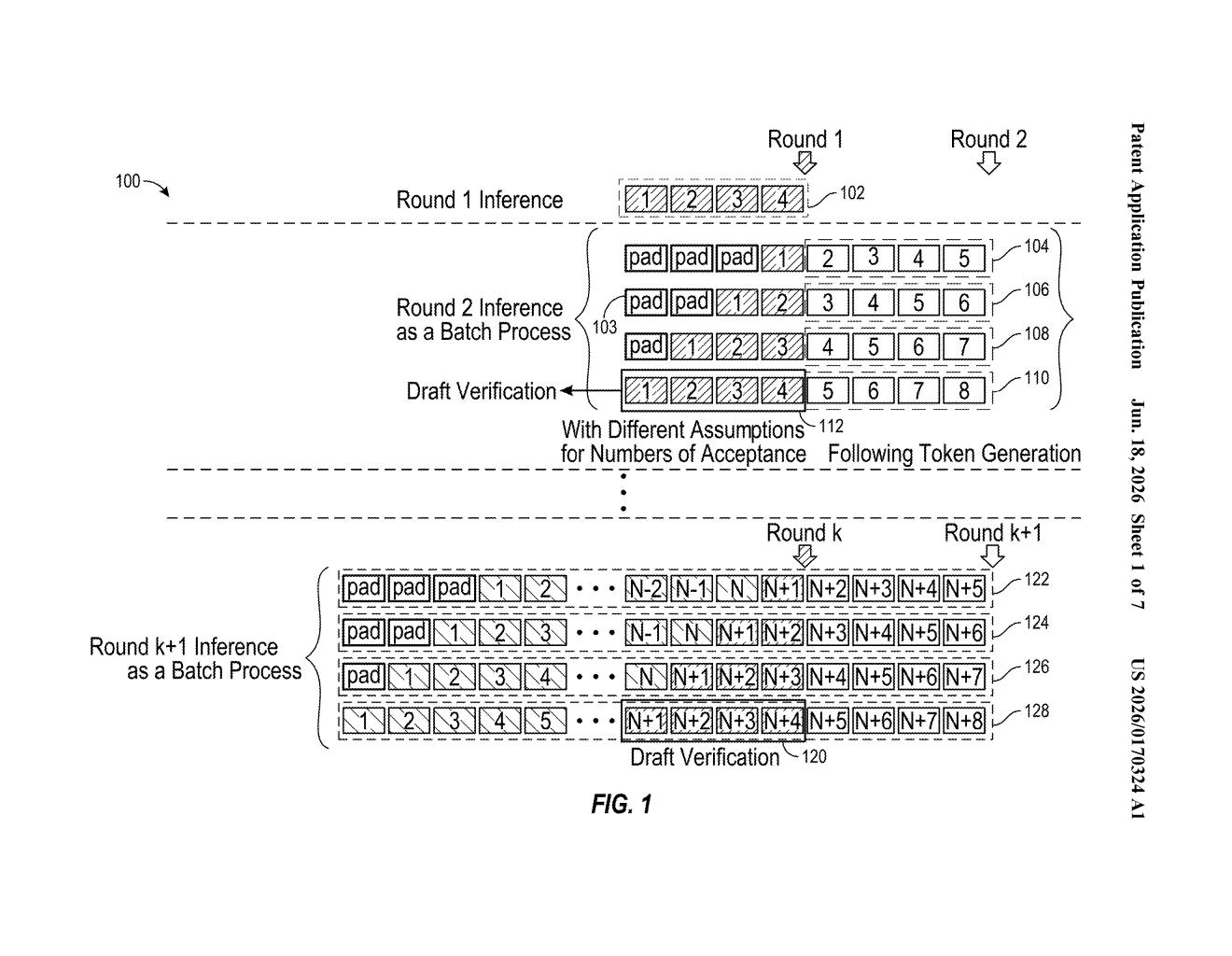
How Qualcomm's AI response drafting shortcut works
Imagine a student who, before finishing an essay, quickly jots down a rough outline of where the argument is going. Then, as they write, they compare that rough outline to what they've actually written — and use the gap between the two to keep themselves on track. Qualcomm's patent describes something similar for AI text generation.
When you type a prompt into an AI assistant, the model normally generates your answer one word (or token) at a time, slowly and sequentially. This patent proposes that the model first make a quick, speculative guess about several upcoming words all at once, then measure how far off that guess turned out to be, and then feed both the guess and the error measurement back into itself as it generates the real answer.
The goal is to make AI responses faster without needing a second, separate "helper" model — which is how most current speed-up techniques work. Instead, one model does both jobs, keeping things efficient enough to run on devices like phones or laptops.
Inside the forecast-embed-and-bias correction loop
The patent describes a method called injected self-speculative decoding, a variation on an existing AI speed-up strategy called speculative decoding. In standard speculative decoding, a small draft model guesses several tokens (individual words or word-pieces) ahead, and a larger model then checks them in parallel — much faster than generating each token one at a time.
Qualcomm's twist removes the need for that separate draft model. Instead, the same generative AI model performs both roles:
- Forecast embedding: After generating the first token of a response, the model speculatively predicts several more tokens ahead and encodes those predictions as a compressed numerical representation (an "embedding" — think of it as a summary fingerprint of the guessed words).
- Bias parameter: The system then measures the difference between those speculative guesses and the tokens the model actually accepts as correct. That error measurement is itself encoded as another embedding — essentially a "how wrong was I?" signal.
- Guided generation: Both the forecast embedding and the bias parameter are injected back into the model as additional context, steering the rest of the response generation.
By feeding the model its own prediction error, the system helps it course-correct in real time, potentially reducing the number of generation steps needed and improving output quality without adding a second model to the compute budget.
What this means for AI running on phones and chips
Most AI speed-up techniques require running two models simultaneously — a small, fast draft model and a larger verification model. That doubles memory usage, which is a serious problem on phones, cars, or any device where memory is limited. Qualcomm makes the chips that power a huge share of Android phones and embedded systems, so a technique that achieves similar speed gains within a single model is directly valuable to their product lineup.
For you as a user, this could translate to AI assistants on your phone responding faster and more accurately without draining your battery as quickly — because less compute is wasted on discarded draft tokens. It also points to where Qualcomm is placing its bets: keeping AI inference efficient enough to run at the edge, not just in the cloud.
This is a genuinely interesting systems patent because it targets a real bottleneck — the memory and compute cost of two-model speculative decoding — with an elegant single-model alternative. It's the kind of incremental-but-meaningful engineering that actually ships into products rather than sitting in a research paper. Whether the bias-parameter approach proves better in practice than existing methods is an empirical question, but the architecture is clean and commercially motivated.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.