Google Patents On-Device Audio That Strips Out Every Voice Except Yours
Imagine being on a noisy call and having your phone automatically strip away every voice except the person you asked it to listen to. That's exactly what this Google patent is describing — and it runs entirely on your device.
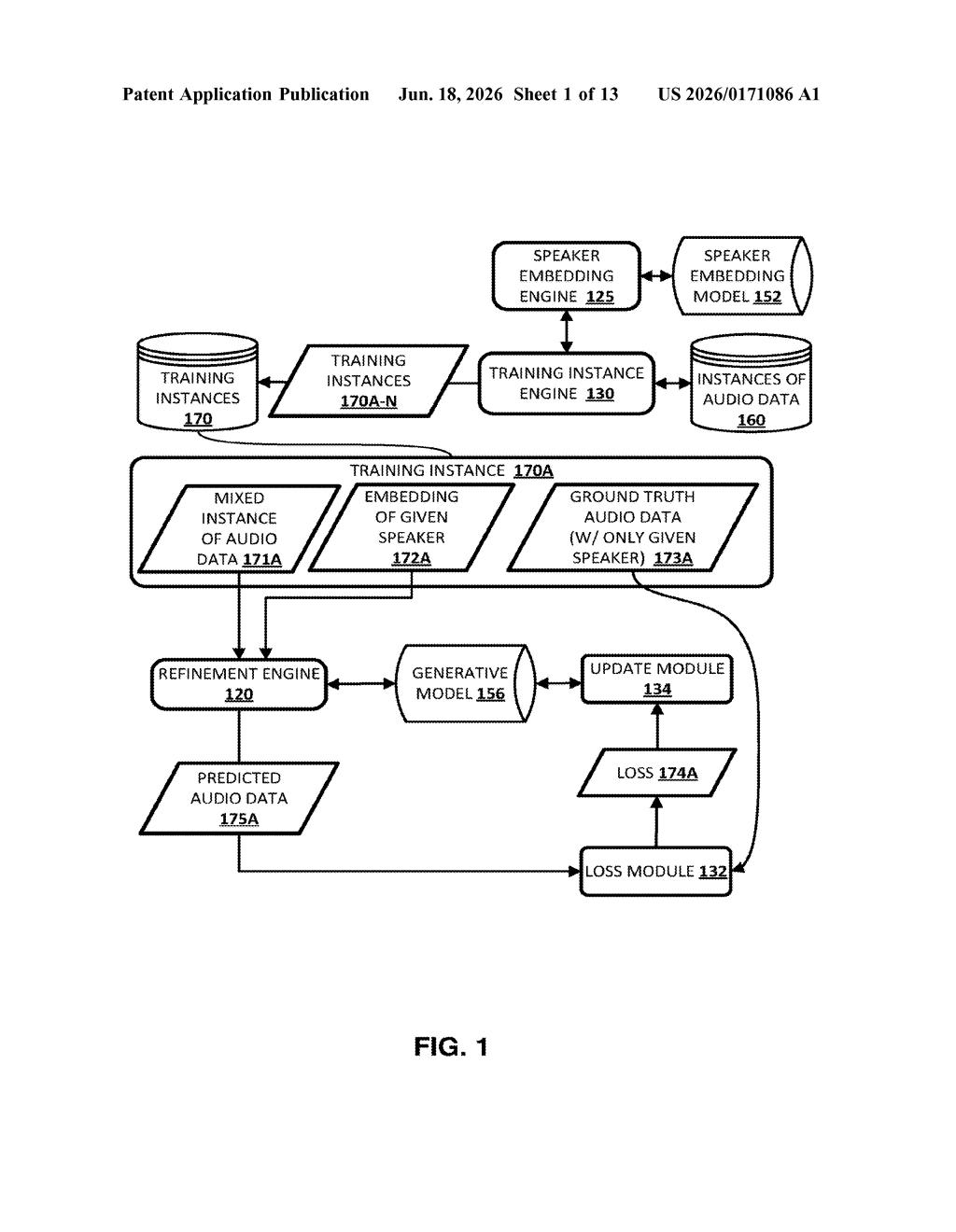
How Google's voice-isolation system picks you out of a crowd
Picture this: you're recording a voice memo in a coffee shop, and your phone picks up the barista, background music, and three separate conversations. Later, you only want your words transcribed. Today, that cleanup is messy at best.
Google's patent describes a system where your device stores a small "voice fingerprint" — a compact mathematical snapshot of what you sound like. When audio comes in, a neural network uses that fingerprint to decide, moment by moment, which sounds belong to your voice and which don't. The result is a cleaned-up audio track with everything else removed.
The key detail here is that it all happens on your device, not in the cloud. Your voice fingerprint never has to leave your phone, which has real privacy implications.
How the neural network uses your voice profile to filter audio
The patent describes a technique called speaker diarization — the process of figuring out "who spoke when" in a multi-person audio recording. But this implementation goes a step further: instead of just labeling speakers, it generates a brand-new, cleaned-up audio track that contains only the target speaker's voice.
Here's the core mechanism:
- A speaker embedding is created for the target person — this is a compact numerical representation (think of it as a voice fingerprint) that captures the unique acoustic qualities of how someone speaks.
- That embedding is fed into a trained generative model (a neural network that can produce new audio data, not just classify it). The embedding influences the network's internal calculations — specifically how its hidden layers activate — so the model learns to pay attention to the target voice and discount everything else.
- The model outputs a refined audio file directly: a version of the original recording where only the target speaker's utterances remain.
Critically, the patent specifies this runs on a client device (your phone or tablet), using a speaker embedding stored locally. That means the voice fingerprint doesn't need to travel to a server to do its job.
What this means for Google's transcription and assistant tools
Voice-related features — transcription, dictation, call summaries, live captions — are central to Google's Assistant and Pixel hardware strategy. A system that can cleanly isolate one speaker's audio on-device would make all of those features more accurate in noisy, real-world conditions. It's not just a cleanup tool; it's a foundation layer for better AI audio features generally.
The on-device angle is also worth flagging for privacy-conscious users. If your voice fingerprint stays on your phone and the processing happens locally, that's a meaningfully different data exposure story than cloud-based alternatives. Whether Google ships this as a consumer feature or keeps it as infrastructure plumbing inside its apps, it has clear practical destinations.
This is genuinely useful work. Speaker isolation that runs on-device, uses a stored voice profile, and produces actual cleaned audio — not just speaker labels — solves a real problem that anyone who's ever tried to transcribe a group conversation has hit. It's not flashy, but it's the kind of foundation that makes a dozen other features better.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.