Google Patents a Distributed AI Training System That Keeps Your Data on Your Device
What if Google could train a smarter AI using data from millions of phones — without ever seeing what's actually on those phones? That's the core idea behind this patent, which describes what the research world calls federated learning.
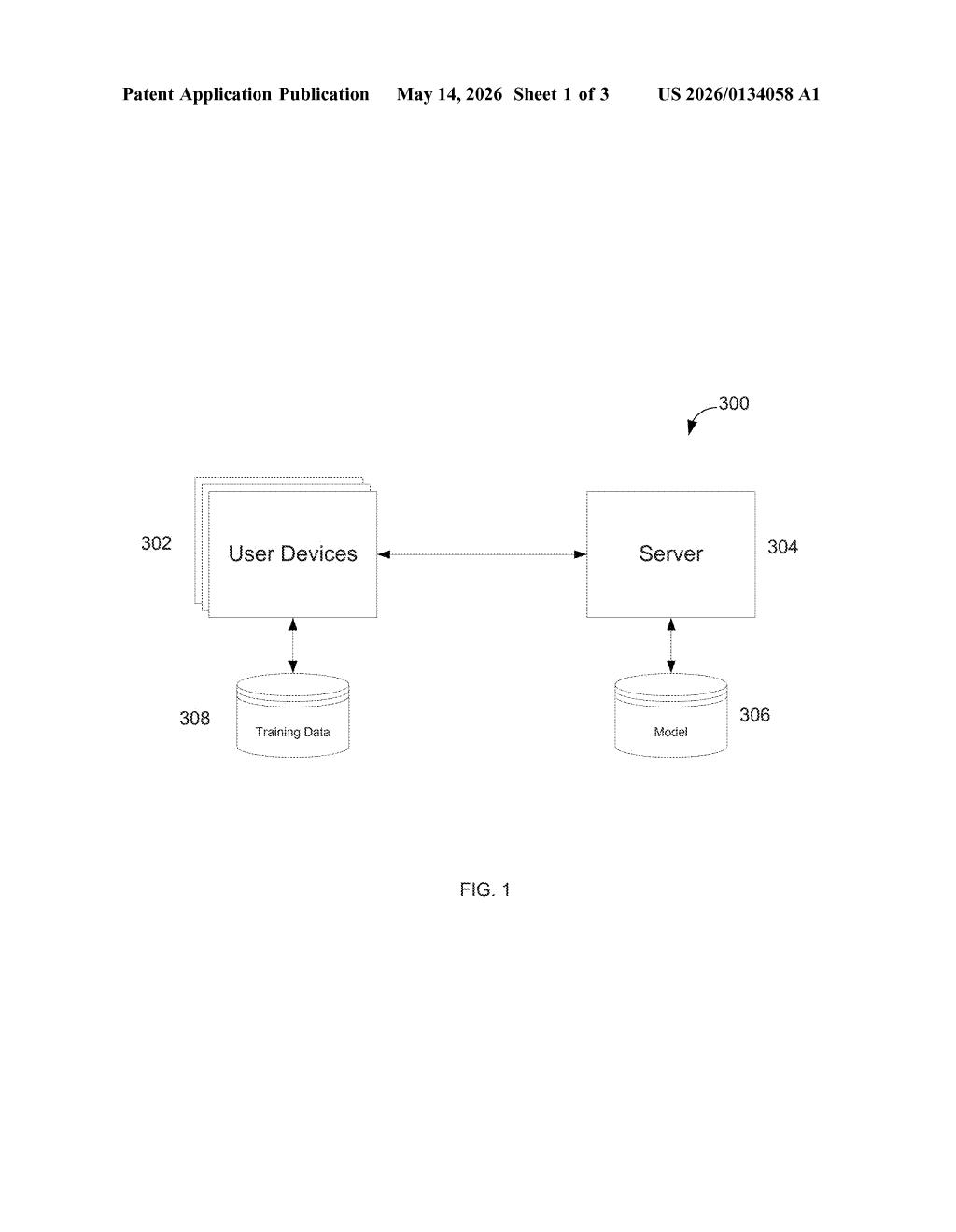
What Google's distributed model training actually does
Imagine your phone learns that you always text 'on my way' after leaving work. Normally, to improve a keyboard or assistant AI, that data would need to be uploaded to a server. But what if your phone could just send a summary of what it learned — not the raw text — and a central server combined those summaries from millions of users into a smarter model?
That's exactly what this Google patent describes. Your device trains a small model update locally using only your own data, then sends just that update — not the underlying data — to Google's servers. The server aggregates updates from thousands or millions of devices to build a global model that reflects everyone's patterns without anyone's private data leaving their device.
This approach is especially useful because real-world data is uneven — your phone has data that looks nothing like your neighbor's. The system is designed to handle that messiness and still produce a coherent, accurate model on the other end.
How local updates get aggregated into a global model
The patent describes a classic federated learning architecture — a technique where model training is distributed across many client devices rather than centralized on a server.
Here's how the loop works:
- A server sends a global gradient (essentially: the current state of the model's learning direction) down to user devices.
- Each device uses its local data to compute a local update — a small nudge to the model based on what it saw on that device alone.
- Devices send those local updates back to the server.
- The server aggregates all local updates (think: averaging millions of small nudges) to produce an improved global model.
- The cycle repeats.
A key technical challenge the patent addresses is non-IID data distribution (non-independent and identically distributed — meaning each device's data is unrepresentative of the overall population). Standard machine learning assumes balanced, representative training data. Federated learning deliberately works with the messy, skewed, fragmented data reality of real user devices.
The server architecture includes standard components — processors, memory, a network interface — but the interesting logic lives in the global updater module, which is responsible for combining heterogeneous local updates into a coherent global model without access to any individual's raw examples.
Why on-device training changes the AI privacy equation
Federated learning is the infrastructure backbone behind features like on-device autocomplete, next-word prediction, and personalized recommendations that don't require uploading your conversations or behavior to a cloud server. For you as a user, it means smarter features with a smaller privacy footprint — the model improves without Google ever seeing your specific inputs.
This filing names some of Google's most prominent ML researchers, including Brendan McMahan and Jakub Konečný, who co-authored the original federated learning paper back in 2016. The fact that Google is still patenting around this architecture suggests they're hardening their IP position as federated learning moves from research curiosity to core production infrastructure across the industry.
This is a foundational federated learning patent from the researchers who essentially invented the technique. It's not a flashy new capability — it's Google locking down the legal framework around a method that's already running on billions of Android devices. The timing, nearly a decade after the original research, suggests this is defensive IP work as federated learning becomes standard practice across the industry.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.