Google Patents a Training Method That Wires Speech Recognition Directly Into an LLM
Getting an AI that transcribes speech to actually *understand* what was said — not just write it down — requires connecting two very different systems. Google's new patent describes a careful training recipe for doing exactly that.
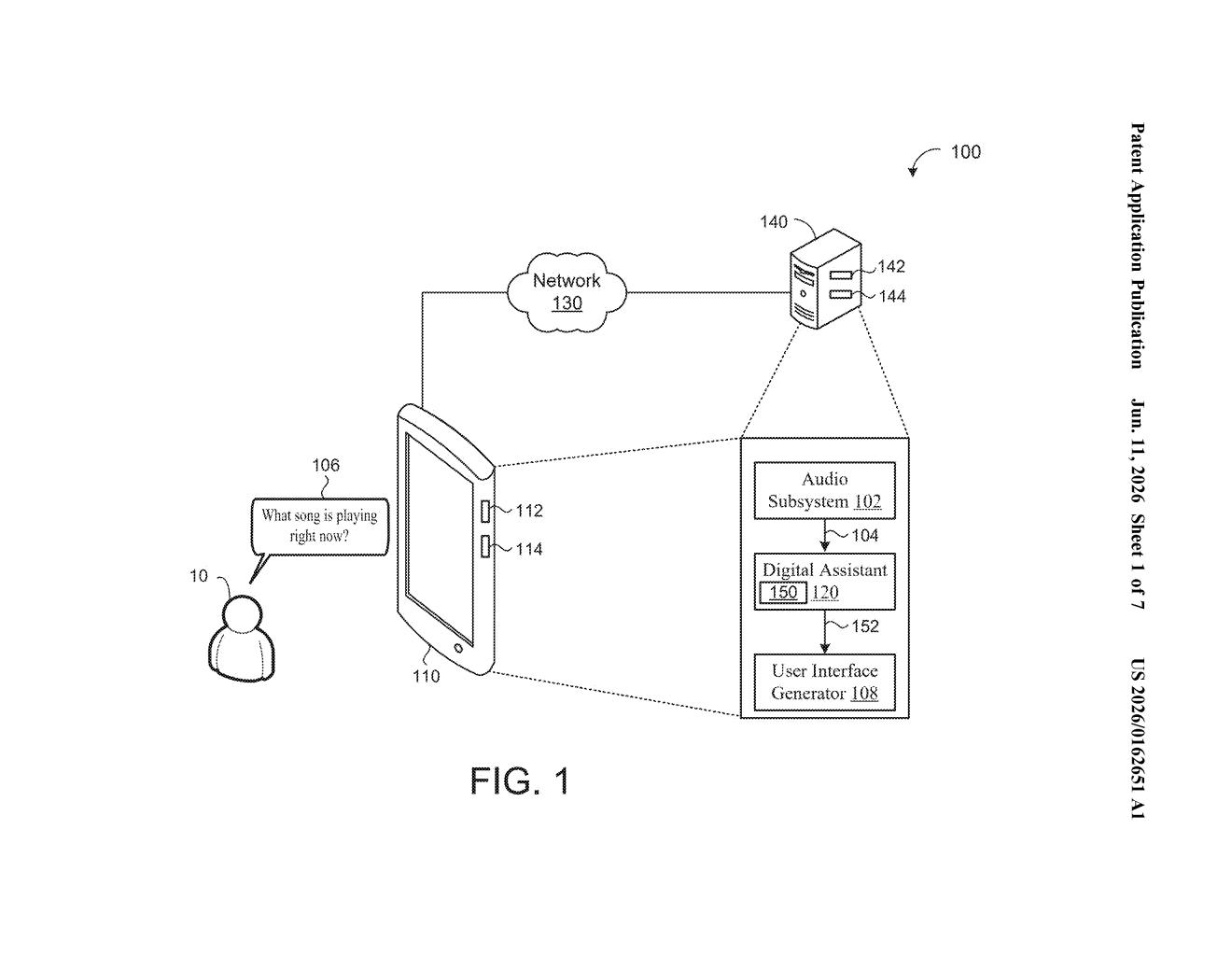
How Google teaches an LLM to understand your voice
Imagine you have two specialists: one who listens to audio and writes down words, and another who reads text and understands meaning. Right now, most voice AI works by passing a transcript from the first to the second. Google's patent describes a way to train both specialists to work together, so the second one can absorb the raw audio signal directly, not just the finished transcript.
The trick is a bridging step during training. Instead of just handing over words, the speech model passes along something richer — a probability-weighted blend of audio signals — which the language model then learns to interpret. Over thousands of training examples, the language model gets better at reading that audio-flavored input.
The result is a system where your voice assistant doesn't just recognize what you said — it processes it with the full reasoning power of a large language model, potentially making it more accurate and context-aware at the same time.
How the audio encoder feeds probabilities into the LLM
The patent describes a two-stage fine-tuning process for combining a pre-trained audio encoder (a model that converts raw audio into a sequence of probability distributions over possible words or sounds) with a pre-trained large language model (LLM).
- Step 1 — Audio encoder fine-tuning: A speech recognition model is trained on labeled audio to output, for each audio frame, a probability distribution over a vocabulary (e.g., how likely is each word or word-piece at this moment in time).
- Step 2 — Speech embeddings: Those probability distributions are used as weights in a weighted sum over the LLM's own internal word-vector table (its "input embedding table"). The output is a sequence of "speech embeddings" — vectors that live in the LLM's native representation space but carry acoustic information.
- Step 3 — LLM fine-tuning: The LLM receives a concatenation of those speech embeddings plus text embeddings of the correct transcript, and is trained to predict the correct output using a standard cross-entropy loss (a measure of how far off the model's predictions are from the right answer).
The key insight is that the bridge between the two models isn't a fixed connector — it's computed dynamically from the audio encoder's probability outputs, allowing the LLM to receive a nuanced, uncertainty-aware representation of the spoken input rather than a hard-decoded word sequence.
What this means for Google's voice-AI pipeline
For everyday users, this kind of architecture is what separates a voice assistant that types out what you said from one that genuinely understands it. By keeping the audio encoder and LLM as modular, separately trainable components, Google can swap in better speech models or larger LLMs without rebuilding the whole system from scratch.
This matters strategically because Google runs voice AI across Search, Assistant, Pixel phones, and Workspace. A cleaner pipeline from raw audio to LLM reasoning could improve transcription accuracy in noisy conditions, reduce errors on rare words, and eventually enable more natural, multi-turn voice conversations — all areas where rivals are also pushing hard.
This is solid, unsexy infrastructure work — the kind of careful training-pipeline engineering that separates production voice AI from research demos. It won't headline a product launch, but it's the type of patent that quietly ends up in every Google product that listens to you. Worth tracking if you follow voice AI.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.