Google Patents a Two-Model System for Smarter AI Training Data Selection
Training a good AI model is only as good as the data you feed it — and most companies are drowning in low-quality pairs. Google's latest patent describes a clever two-model judging system that automatically scores which training examples are actually worth learning from.
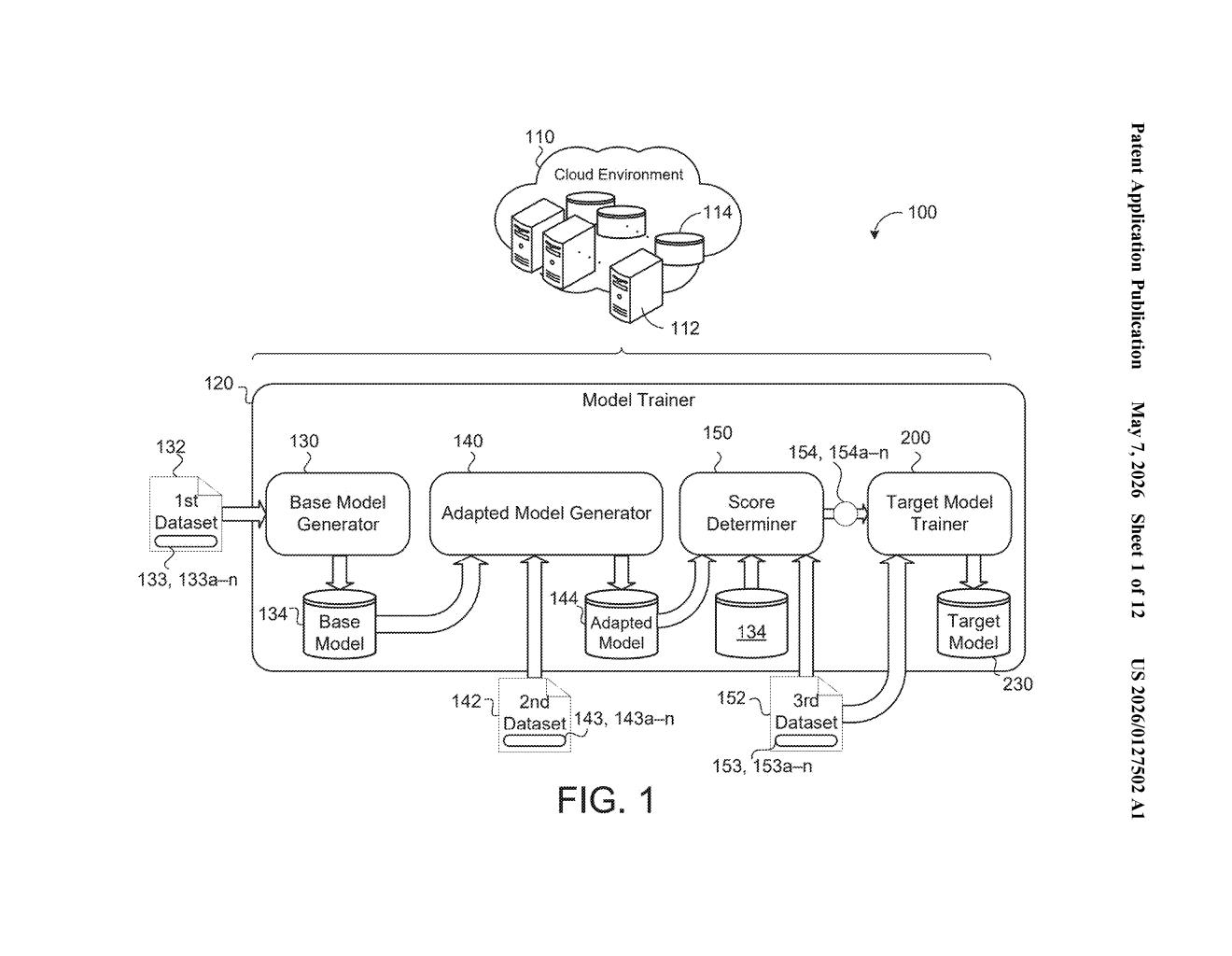
How Google's dual-model data filter actually works
Imagine you're trying to teach someone a new language using flashcards. Most of those flashcards are fine, but some have typos, bad translations, or just weird examples that would confuse more than help. You'd want to sort them before studying, but manually checking millions of cards is impossible.
That's essentially the problem Google is solving here. Their patented method trains two AI models — a general "base" model and a more specialized "adapted" model — and then uses both together to score how useful each piece of training data is. If the specialized model finds a data pair much more meaningful than the generic one, that's a signal the data is high-quality and relevant.
The result: instead of training your final AI on all the messy data, you train it on a curated, scored subset. You get a smarter model with less wasted compute. It's a quality filter baked directly into the training pipeline.
How the contrastive score ranks training data pairs
The patent describes a three-stage pipeline for training sequence-to-sequence models (the class of AI that powers translation, summarization, and similar tasks):
- Stage 1 — Base model: Train a general-purpose model on a broad first dataset. Think of this as your AI with wide but shallow knowledge.
- Stage 2 — Adapted model: Fine-tune that base model on a smaller, domain-specific second dataset to create a specialized version.
- Stage 3 — Contrastive scoring: For every data pair in a large third dataset, compute a contrastive score — a measure derived from the probability difference between what the adapted model predicts and what the base model predicts for that pair. A high score means the adapted model finds this example especially informative relative to its general-purpose sibling.
The contrastive score acts as a proxy for data quality: data pairs that the specialized model assigns much higher probability to (compared to the base model) are likely well-formed, in-domain, and worth learning from.
Finally, a target model is trained only on the highest-scoring subset — or using the scores as sample weights — making the whole training run more data-efficient. The approach is related to techniques like data selection via cross-entropy difference, a well-studied NLP idea, but operationalized here as a full end-to-end trainable pipeline.
What this means for AI model quality at scale
Data quality is one of the least glamorous but most impactful levers in AI development. As models get bigger and training runs get more expensive, wasting compute on bad data becomes a real cost. Google's system could meaningfully cut the amount of data needed to reach a given quality level — which matters enormously for specialized tasks like low-resource language translation or domain-specific summarization.
For you as a user, cleaner training pipelines tend to produce models that make fewer embarrassing errors on the specific tasks they're designed for. If this method gets folded into Google Translate or Gemini's fine-tuning infrastructure, the downstream effect would be more reliable, less noisy outputs — especially in niche languages or subject areas where good training data is scarce.
This is a solid, technically grounded patent in a well-established research area — contrastive data selection has been an active NLP topic for over a decade. The novelty here appears to be in how Google formalizes and systematizes it as an end-to-end pipeline, rather than a fundamentally new idea. It's not headline-grabbing, but for a company running translation and summarization at Google's scale, even a modest improvement in data efficiency is worth patenting.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.