Google Patents a Speech Recognition Model That Trains Across Languages Using One Alphabet
Training a single AI model to understand dozens of languages is hard enough — doing it when those languages use completely different alphabets is even harder. Google's solution: convert everything to one script first, then train.
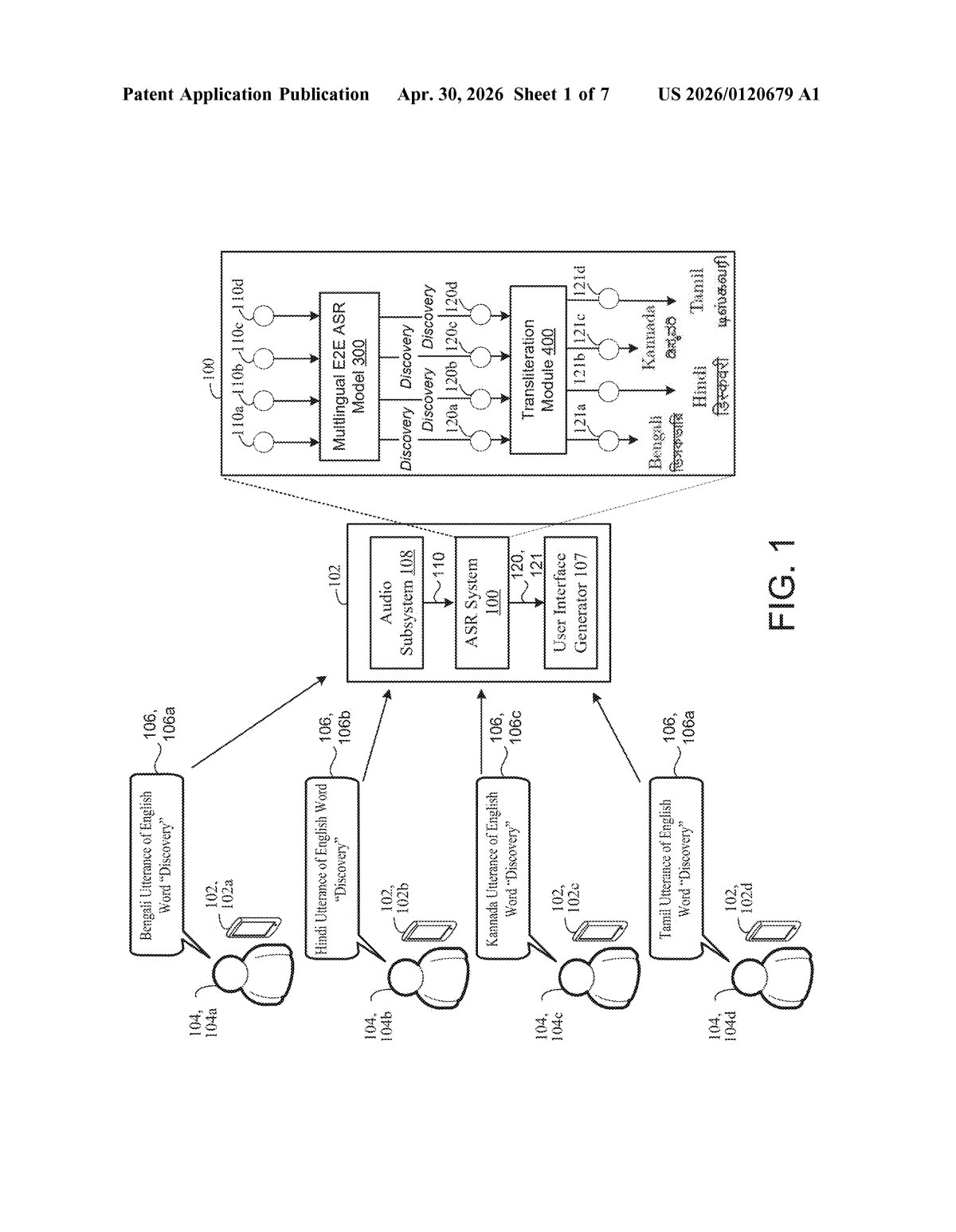
How Google's single-script speech model handles dozens of languages
Imagine trying to teach someone to read music when every composer used a different notation system. That's roughly the problem Google faces when building a speech recognizer that works across languages like Hindi, Arabic, Japanese, and English — each written in a totally different script.
Google's patent describes a clever workaround: before training the AI at all, convert every language's written transcriptions into a single target alphabet (likely the Latin script used by English). This process — called transliteration — doesn't translate the words, just respells them using the new alphabet's characters. So the Hindi word for 'water' still sounds Hindi, but it's now written in a way the model can process alongside English, Spanish, and French.
The result is one unified model that can recognize speech in many languages without needing a separate system — or a separate training dataset — for each one. That's a meaningful efficiency gain when you're trying to support hundreds of language variants worldwide.
How transliteration normalizes training data across scripts
The patent describes a multilingual end-to-end automatic speech recognition (ASR) system — meaning a single neural network that takes raw audio in and spits out text, with no intermediate phoneme-lookup step in between.
The core innovation is in how training data is prepared. Normally, a multilingual ASR model has to handle multiple output alphabets simultaneously, which adds complexity and can hurt accuracy. Here, Google introduces a transliteration module that pre-processes every training sample:
- Take audio of someone speaking, say, Bengali, paired with its Bengali-script transcript.
- Run the transcript through a transliteration engine that respells it in the target script (e.g., Latin characters).
- Pair that new Latin-script text back with the original audio to create a normalized training sample.
This is done across all languages and all training datasets before a single training step happens. The model then learns to produce outputs in just one script, regardless of which language it's hearing. Crucially, the audio is never altered — only the labels are converted. So the acoustic modeling (learning what sounds correspond to what) still happens in the native language; only the output layer is standardized.
The approach is closely related to existing techniques like romanization (converting scripts to Latin) used in multilingual NLP, but this patent applies it specifically to the ASR training pipeline as a systematic normalization step.
What this means for Google's multilingual voice products
For Google, this patent is about scaling voice recognition without scaling engineering costs. Supporting a new language on Google Assistant or Live Transcribe today often means training, maintaining, and serving a separate model. A single unified model that works across dozens of languages — even low-resource ones with limited training data — could drastically reduce that overhead.
For users, the practical payoff could be better voice recognition in languages that currently get less attention because their speaker populations are smaller. When a model pools data from many languages sharing a single output space, rare languages can borrow signal from more common ones — a concept called transfer learning. That's the real promise here: your language doesn't need to be English to get English-quality transcription.
This is solid, unglamorous infrastructure work — the kind that doesn't ship as a headline feature but quietly improves every product that uses voice input. The transliteration-normalization idea is not entirely new in NLP research, but patenting it as a systematic ASR training pipeline gives Google a clear stake in this specific approach. Worth tracking if you care about multilingual AI.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.