Microsoft Patent Splits AI Model Layers Across Chips by Their Strengths
Running a massive AI model is expensive partly because today's systems don't always match workloads to the right hardware. Microsoft has filed a patent for a system that automatically routes different parts of an AI model to chips that are purpose-built for each job.
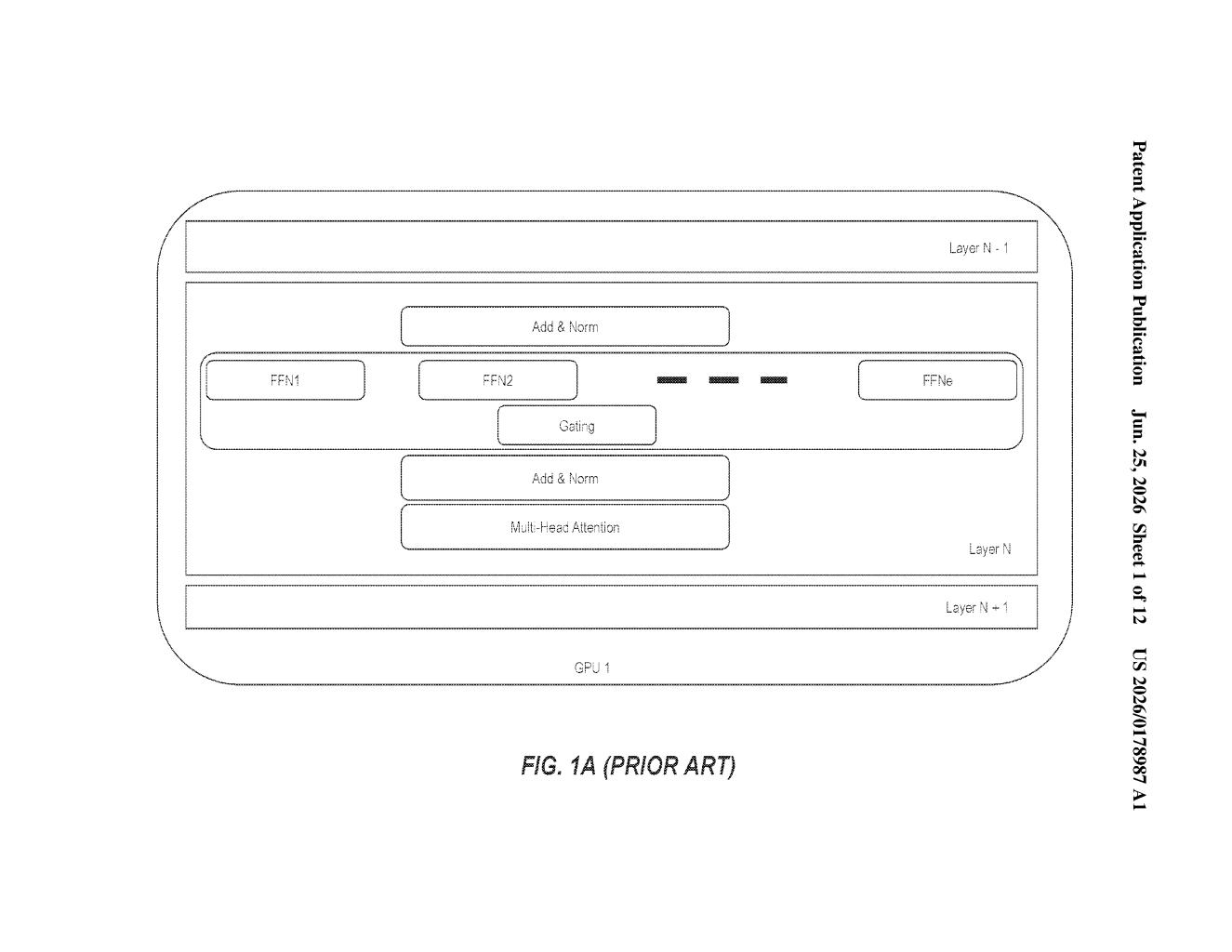
What Microsoft's chip-splitting AI system actually does
Imagine your kitchen had two appliances: a big slow-cooker with plenty of space and a small high-powered blender. You wouldn't cook a roast in the blender. Microsoft's patent applies that same logic to AI chips.
Modern AI models contain two types of work. Some parts (called dense layers) involve lots of rapid calculation across every piece of data. Other parts (called sparse layers, common in a design known as Mixture-of-Experts) mostly need to hold large lookup tables in memory and read from them. These two jobs need very different hardware.
The patent describes a system that automatically assigns each type of work to the chip category that suits it best: high-memory chips for the lookup-heavy sparse parts, and high-speed processors for the calculation-heavy dense parts. The two sets of chips then pass data back and forth as the model runs.
How dense and sparse layers get routed to different hardware
The patent covers a software-managed computing system that distributes the layers of a Mixture-of-Experts (MoE) model (an AI architecture that activates only a small subset of its internal "experts" for any given input, keeping most parameters idle) across two distinct classes of accelerator chips.
- First set of accelerators (memory-heavy): These chips have large memory capacity but lower raw processing speed. They host the model's sparse layers, the parts of the MoE that store many specialist sub-networks and selectively load them.
- Second set of accelerators (compute-heavy): These chips have high processing throughput but smaller memory. They run the model's dense layers, where every parameter is used on every input and throughput matters most.
The key coordination step: the system is designed so that a sparse-layer chip can receive multiple simultaneous inputs from several dense-layer chips. That fan-in design keeps the fast chips from sitting idle while waiting for the memory-heavy chips to respond.
The patent does not tie the system to a specific chip brand or product. It defines the architecture at the software instruction level, meaning it could theoretically run on any combination of accelerators that fits the memory-vs-compute tradeoff.
What this means for running large AI models cheaply
Running large MoE-style AI models (the architecture behind several frontier models) today often means buying a uniform cluster of expensive, high-memory chips even though parts of the model would run fine on cheaper, faster hardware. A system that lets operators mix chip types could cut infrastructure costs significantly, or let the same budget support a larger model.
For Microsoft, which runs Azure's AI infrastructure and hosts OpenAI models, even modest efficiency gains at scale translate to real money. This patent suggests the company is building out the plumbing to run next-generation models on heterogeneous hardware fleets rather than uniform, premium-chip clusters.
This is unglamorous infrastructure work, but it's the kind that pays off at cloud scale. If Microsoft can run MoE models on mixed hardware without a performance penalty, that's a meaningful cost advantage over competitors locked into homogeneous GPU clusters. It won't make headlines the way a new AI feature does, but it's worth watching.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.