Nvidia Patents an AI That Learns to Outline Objects in Photos Without Human Help
Training an AI to recognize and outline objects in photos normally requires thousands of hours of humans manually tracing those objects. Nvidia's new patent describes a system that skips that entirely.
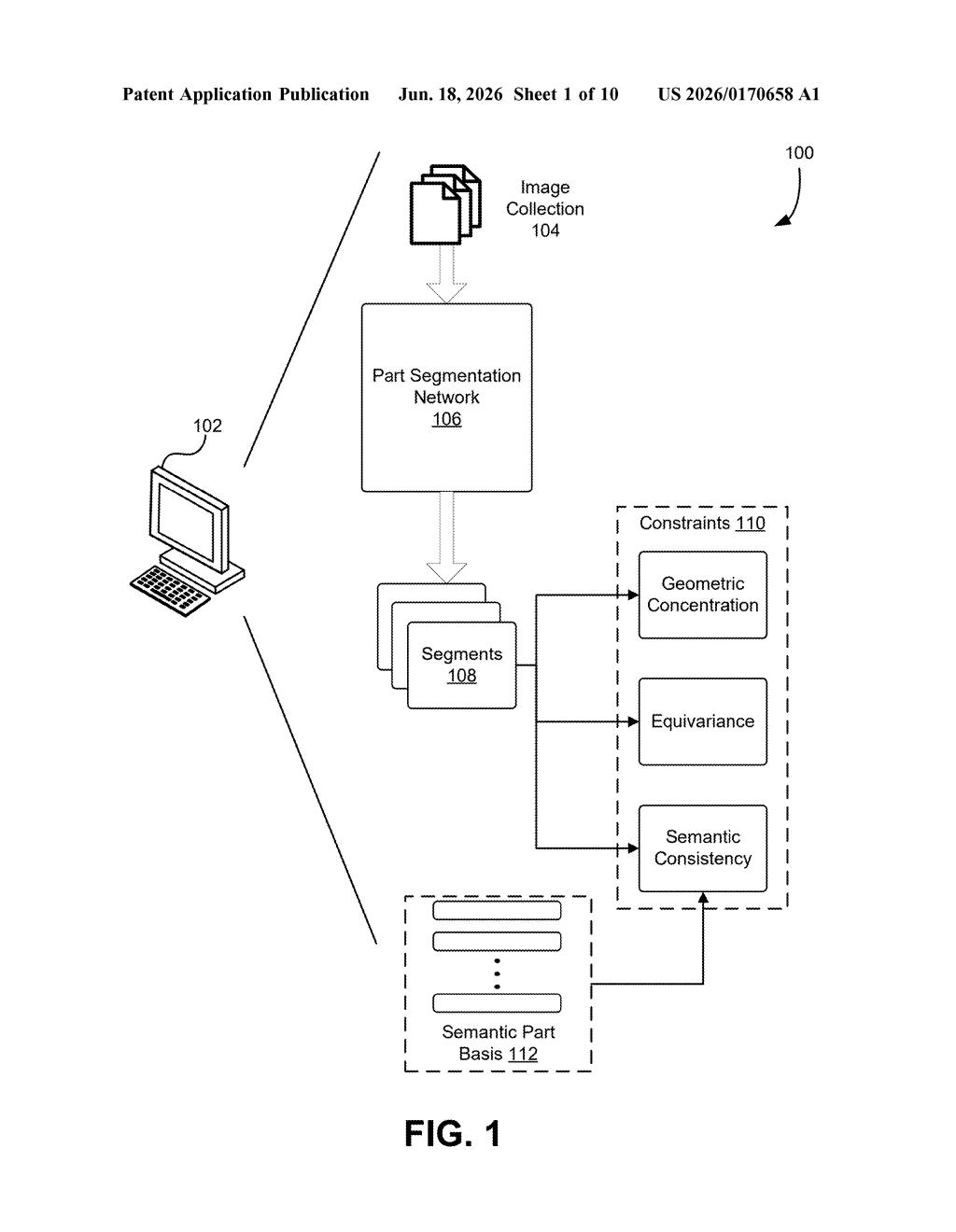
What Nvidia's label-free image segmentation actually does
Imagine you want to teach an AI to recognize a dog in a photo — not just say 'there's a dog,' but draw an exact outline around it. The usual approach involves paying people to trace outlines around thousands of dogs across thousands of photos. It's expensive, slow, and a bottleneck for every new category of object you want the AI to learn.
Nvidia's patent describes a way to train an AI to do this without any of those hand-drawn outlines. Instead, the system figures out object boundaries on its own, by testing whether its guesses hold up when the image is flipped, zoomed, or rotated. If the AI's outline of the dog is correct, it should behave consistently no matter how the image is transformed.
Unsupervised learning — training without labeled examples — is one of the biggest open challenges in computer vision. This patent tackles that problem specifically for segmentation, the task of telling pixels apart by which object they belong to.
How the neural network trains itself on image transformations
The core idea in the patent is called transformation consistency. Here's the logic: if a neural network has correctly identified which pixels belong to a dog, then rotating or flipping the image should produce an identically rotated or flipped outline. If the outline doesn't follow the transformation correctly, the network knows its segmentation was wrong and adjusts accordingly.
This creates a self-correcting training loop — the AI generates a segmentation, applies a transformation to the image, checks whether the segmentation transformed the same way, and uses any mismatch as a learning signal. No human needs to tell the network what's right or wrong; the geometry of the transformation does that automatically.
The patent specifically covers:
- Applying the same spatial transformations (rotations, flips, crops) to both the original image and the network's predicted segmentation
- Using the agreement — or disagreement — between those two outputs to guide training
- Doing all of this without any labeled training data (the unsupervised part)
Image segmentation is already used in self-driving cars, medical imaging, and augmented reality — anywhere a system needs to know not just what is in a scene but where each thing is, down to the pixel level.
What this means for AI vision in robotics and self-driving
Labeling data is one of the largest costs in building production AI systems. Any technique that reduces or eliminates that cost has real consequences for how fast — and how cheaply — AI vision can be deployed across new domains. For Nvidia, whose hardware runs most of the world's AI training workloads, owning a method that makes training more efficient is strategically important.
For you as a user, the downstream effects could show up in products like autonomous vehicles, where collecting labeled data for every road condition in every country is practically impossible. A system that learns segmentation from raw experience rather than hand-labeled datasets could adapt much faster to new environments — and do it without a massive data labeling operation behind it.
This is a genuinely interesting research patent, not a routine filing. Unsupervised segmentation is a hard problem that the vision research community has been working on for years, and the transformation-consistency approach is a clean, testable idea. Whether Nvidia can make it work at scale on the kinds of complex, cluttered scenes that real applications demand is the real question — but the direction is worth watching.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.