OpenAI Patents a Custom AI Chip That Stacks Memory Directly on the Processor
Moving data around inside a chip burns a surprising amount of energy — and OpenAI thinks the fix is to stop moving it very far at all. This patent describes a chip where memory sits almost directly on top of the math units that need it.
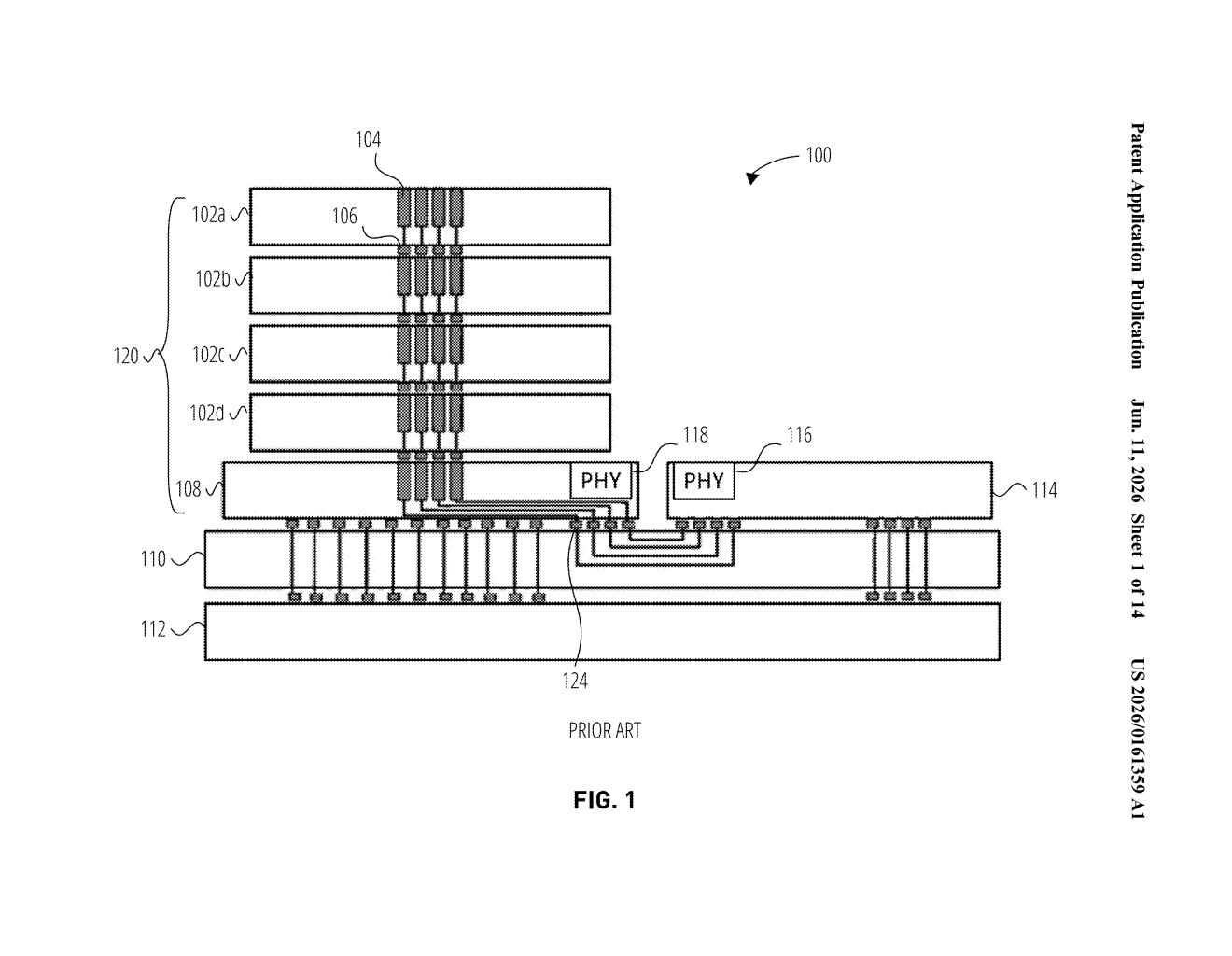
What OpenAI's memory-on-processor chip actually does
Imagine a library where the librarian has to walk half a mile to retrieve every single book you request. Now imagine the books are stored on a shelf two feet away. That second library gets things done much faster and with a lot less effort. That's essentially the problem OpenAI is trying to solve with this patent.
Today's AI chips spend a lot of energy just shuttling data back and forth between memory and the parts of the chip that do the actual math. OpenAI's design stacks the memory chips physically on top of the processor, connecting them with tiny vertical wires — some as short as 0.05mm. The result is that data barely has to travel at all.
This matters most for a specific job AI does constantly: looking up and retrieving information stored during a conversation (called a key-value cache). The faster and more cheaply a chip can do that lookup, the less it costs to run a powerful AI model at scale.
How the stacked-die design cuts wire length to under 1mm
The patent describes a hardware accelerator — a specialized chip built to do one specific job extremely well — designed around a technique called a dot-product lookup. In plain terms, a dot product is a way of measuring how similar two pieces of information are, which is exactly what an AI does when it searches its memory for relevant context during a conversation.
The key structural innovation is the physical arrangement of the chip's layers:
- Memory stacks — multiple layers of DRAM (standard computer memory) built on their own silicon dies and stacked vertically
- Processor die — the layer sitting underneath the memory stacks, containing the arithmetic logic units (ALUs) that do the math
- Ultra-short wires — vertical connections called through-silicon vias (TSVs) linking the layers, with wire lengths below 2mm and potentially as short as 0.05mm
The patent also describes processing-in-memory ALUs — math units embedded directly inside the memory layers themselves, so some calculations happen right where the data lives rather than requiring any movement at all.
The explicit target workload is the transformer key-value cache — the memory system that lets large language models like GPT keep track of everything said in a long conversation. This cache lookup is a major bottleneck and energy sink in modern AI inference.
What this means for the cost of running AI models
Running large AI models is expensive, and a substantial chunk of that cost comes from the energy required to move data inside chips — not from the math itself. By shrinking wire lengths to under 1mm, OpenAI's design attacks that cost directly. At the scale OpenAI operates, even modest per-query efficiency gains translate into enormous savings.
This also signals that OpenAI is investing in custom silicon rather than relying entirely on off-the-shelf GPUs from Nvidia or others. Companies that build their own chips can optimize them for their exact workloads — something Google did with its TPUs and Amazon did with Trainium. If OpenAI pursues this path, it could change your experience as a user: faster responses, lower costs, and potentially models that can hold much longer conversations without slowing down.
This is a legitimately interesting patent because it targets a real and well-documented inefficiency in AI hardware — the memory bandwidth bottleneck — with a specific physical architecture rather than a software trick. The 0.05mm wire-length figure is the kind of concrete engineering claim that suggests this came from actual chip designers, not a defensive filing. Whether OpenAI ever manufactures this at scale is a different question, but the direction is credible.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.