Samsung Patents Technology That Learns How Variables Influence Each Other to Forecast Outcomes
Before Samsung's new patent tries to predict anything, it first draws a map of how different pieces of data are connected — and then uses that map to build its prediction model, rather than learning everything from scratch.
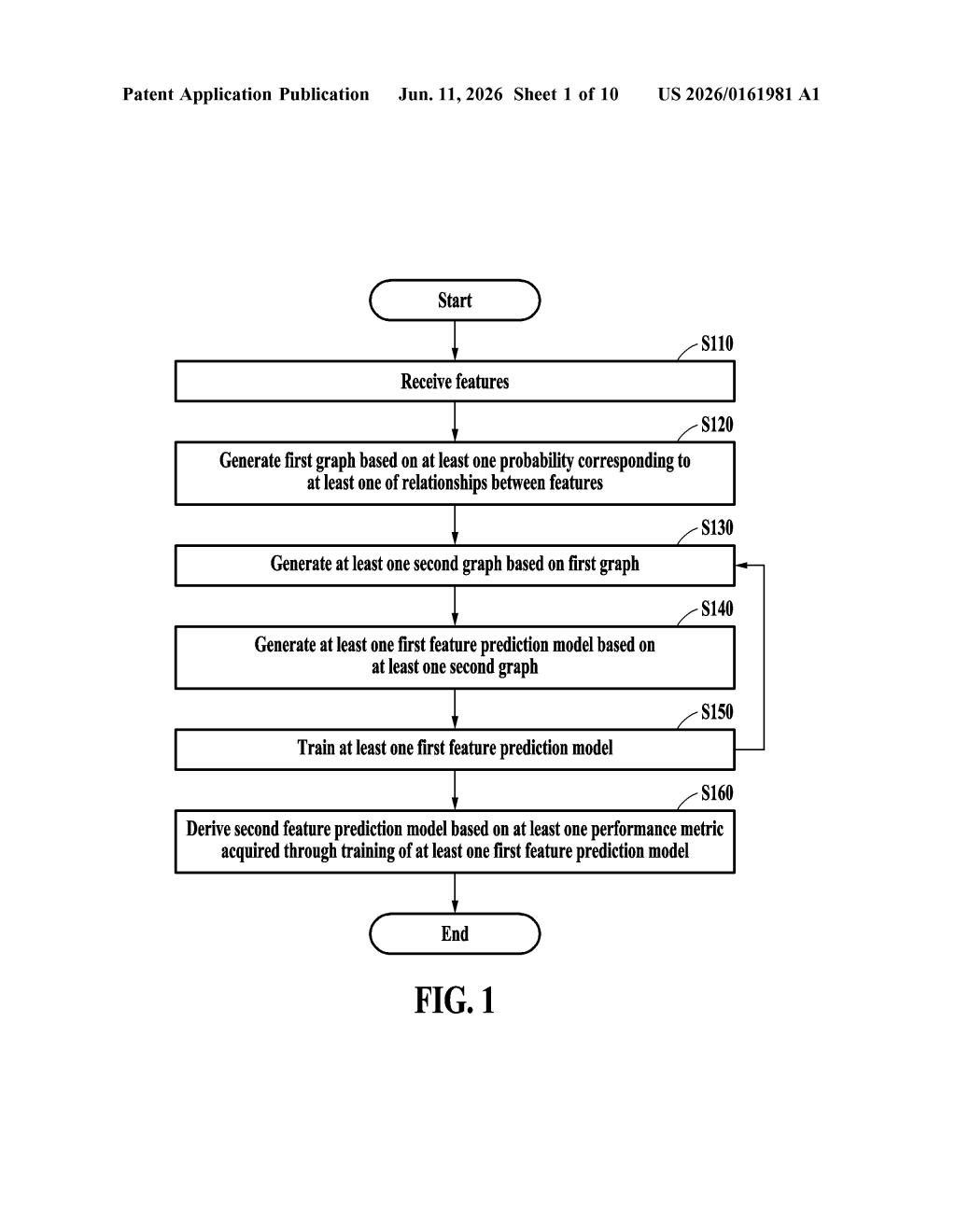
How Samsung's relationship-graph prediction system works
Imagine you're trying to predict whether someone will like a movie. You might look at their age, their past ratings, the genre, and the director — but those things also influence each other. A model that ignores those connections can make worse guesses than one that understands them.
Samsung's patent describes a system that starts by building a kind of relationship map — think of it like a web diagram showing which data points influence which other data points. That map then guides the construction of a prediction model, and the whole process repeats in multiple rounds, each time refining both the map and the model.
The end result is a prediction model that's been shaped by an understanding of how your input data is actually structured — not just what the raw numbers say. This kind of approach is relevant anywhere you need to forecast outcomes from complex, interrelated data, from health diagnostics to product recommendations.
How the graph structures guide each training round
The patent describes a multi-round machine learning pipeline built around a concept called a relationship graph — a data structure where each node represents a feature (an individual variable, like a sensor reading or a user attribute) and each edge represents a probable relationship between two features.
The process works in layers:
- A first graph is generated based on estimated probabilities of relationships between features — essentially a soft, probabilistic map of how the input variables might interact.
- In each round, the system samples a directed acyclic graph (DAG) — a stricter version of the map where relationships only flow in one direction and never loop back — from that first graph.
- A multi-feature prediction model is built from each DAG and trained on data.
- After multiple rounds, a final model is derived from the collection of trained models — essentially distilling what was learned across all iterations.
The use of a DAG is important: it enforces a causal structure (meaning the system tries to understand which features cause changes in others, not just which ones correlate). This is a well-studied approach in probabilistic machine learning called structure learning, and it's designed to produce models that generalize better to new data.
What this means for Samsung's AI model pipeline
For Samsung, which ships AI features across a vast range of products — smartphones, home appliances, semiconductors, and health wearables — having a more principled way to build prediction models from messy, interrelated data is genuinely useful infrastructure. A system that explicitly models how your data variables relate before training could reduce the amount of labeled data needed and improve accuracy in domains where cause-and-effect matters, like health monitoring or device diagnostics.
That said, this is foundational research-level IP, not a consumer feature announcement. The technique is well-grounded in academic machine learning, and Samsung filing a patent here suggests they want ownership over a specific implementation of structure-learning-guided model training — useful leverage in enterprise AI and on-device ML contexts where model efficiency and interpretability are priorities.
This is solid, methodical AI infrastructure work — not flashy, but the kind of foundational patent that matters if Samsung wants to compete seriously in on-device and enterprise machine learning. The DAG-based structure learning approach has real academic credibility, and wrapping it in a patentable training pipeline is a smart defensive move. It's worth watching if you follow Samsung's AI strategy, but it won't show up in a product announcement anytime soon.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.