Red Hat Patents a Method to Score and Filter AI Training Sources
An AI model is only as good as the data it learns from — and Red Hat just filed a patent for a system that automatically figures out which sources are worth trusting before training even begins.
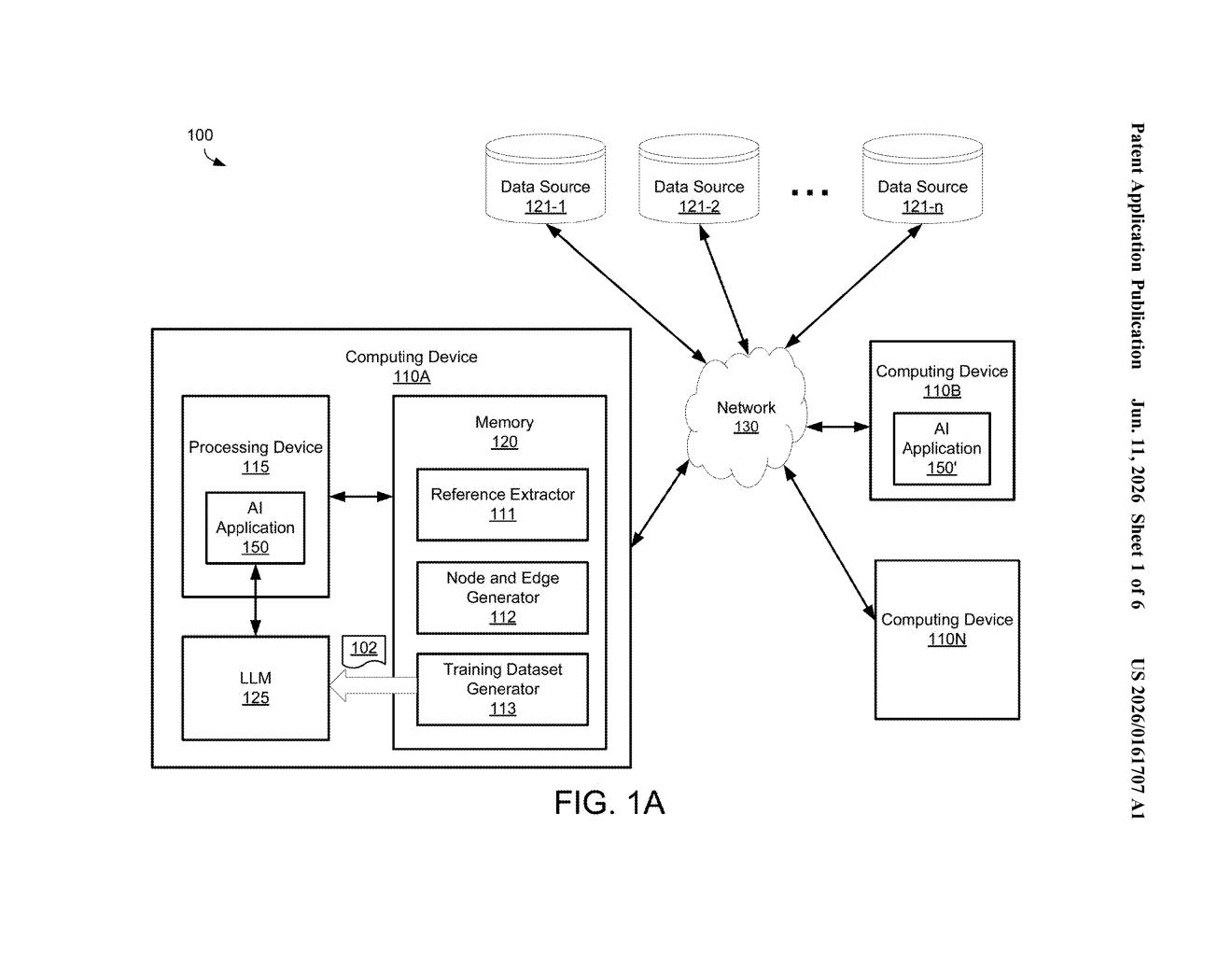
How Red Hat scores data before feeding it to an AI
Imagine you're building an AI assistant and you have to teach it by feeding it thousands of documents pulled from dozens of websites, databases, and internal wikis. Some of those sources are meticulous and well-cited; others are sloppy or just plain wrong. If you treat all of them equally, your AI picks up the bad habits right along with the good ones.
Red Hat's patent describes a system that scores each data source before the AI starts learning. It does this by mapping out how often one source cites or references another — essentially building a web of credibility. Sources that are frequently cited by other reliable sources score higher, and their content gets more weight when shaping the AI's knowledge.
The result is a training dataset where trustworthy sources punch above their weight and low-quality ones are quietly sidelined — without a human having to manually review every document. It's a quality filter built directly into the data pipeline.
How the graph scores and weights each data source
The system works in three main steps.
First, it extracts references from every document in the incoming data pool — links, citations, footnotes, or any signal that one piece of content points to another. Second, it builds a graph data structure (think a network diagram) where each data source is a node and every reference between sources is a drawn edge connecting them. A source cited by many others will have many edges; an isolated or rarely-cited source will have few.
Third, it computes a quality score for each source using a weighted formula that combines two things:
- How many references point to that source (its "citation count" in the graph)
- Pre-established reliability information about the source itself (e.g., whether it's a known authoritative domain or internal verified dataset)
Those two inputs are combined into a weighted sum and then normalized (scaled to a consistent range so scores are comparable across sources of very different sizes). Finally, when the training dataset is assembled, documents from high-scoring sources exert greater influence on what the large language model learns — while documents from low-scoring sources are included at reduced weight or filtered out entirely.
What better training data means for enterprise AI models
For companies building or fine-tuning their own AI models on internal and external data, the quality of that data is one of the hardest problems to solve at scale. Manual curation is expensive and slow; blindly scraping the web produces noisy, unreliable training sets. A system that automatically ranks sources based on how they cite each other borrows a well-proven idea — it's essentially PageRank for AI training data — and applies it to a problem that costs organizations real money.
Red Hat occupies an interesting position here: as a major open-source enterprise software company, it trains and deploys AI models (including through its InstructLab project) for business customers who care deeply about model reliability. A patent on automated training-data quality scoring fits squarely into that strategy and could show up in Red Hat's AI tooling.
This is a sensible, well-scoped patent that tackles a genuine pain point in enterprise AI development. The graph-based citation approach isn't conceptually exotic — it echoes link-analysis algorithms that have existed for decades — but applying it systematically to LLM training pipelines is practical and timely. Red Hat isn't swinging for the fences here, but it's staking a clear position in the increasingly competitive world of AI training infrastructure.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.