Samsung Patents a Graphics Chip That Redirects Its Own Data Lookups Mid-Task
Most GPU shaders fetch data from memory the same way every time. Samsung's new patent describes a shader module that can update its own memory-search strategy mid-pipeline — a subtle but potentially meaningful change in how graphics data gets loaded.
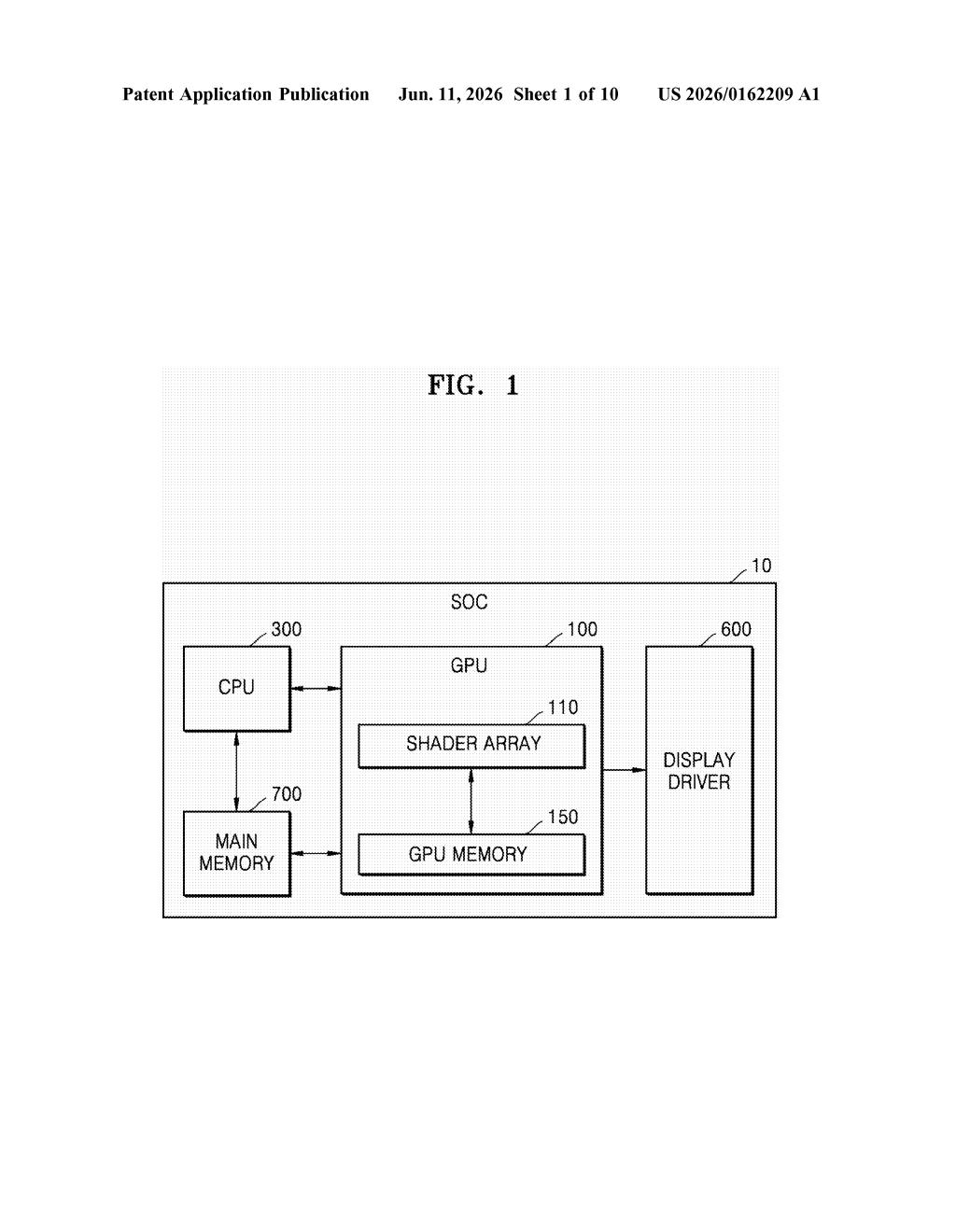
What Samsung's self-updating GPU shader actually does
Imagine a chef who has to retrieve ingredients from a giant warehouse. The normal approach: always walk the same route, in the same order. Samsung's patent describes something more like a chef who reads the recipe first, then decides the fastest route to grab exactly what's needed for this dish.
In GPU terms, each shader module — the small processor that handles coloring and lighting calculations — now has a built-in circuit that looks at how the current graphics pipeline is configured, then figures out the best way to pull the right data from memory. Instead of using a fixed search pattern, it adapts based on what the pipeline actually needs.
The result is that data loading becomes tightly coordinated with what the shader is actually about to do. Whether this pays off in real framerates depends heavily on implementation, but the idea is to cut wasted memory trips before the heavy shading work even begins.
How the address generator updates its search pattern
The patent describes a shader module — one of many small parallel processors inside a GPU — redesigned with four distinct internal components working together.
- Data address generation circuit: Reads pipeline information (metadata about what kind of graphics job is running) stored in a dedicated first memory, then updates a search pattern — essentially a strategy for where to look in memory — before generating the actual memory addresses it needs.
- Data loading circuit: Uses those addresses plus the pipeline information to fetch the raw input data from a second, separate memory bank.
- Controller: Schedules the sequence of instructions needed to run the graphics pipeline, coordinating the work across the module.
- Processing circuit: Performs the actual shading — computing colors, lighting, shadows — on the data that was loaded.
The key novelty is in step one: the address generator doesn't just passively translate requests into memory lookups. It actively adjusts its search strategy based on pipeline state before issuing any memory requests. Samsung splits GPU memory into two pools — one for pipeline metadata, one for actual data — so the shader can consult the first without interfering with the second.
What this means for GPU efficiency in graphics workloads
GPU memory bandwidth is one of the biggest bottlenecks in graphics and compute workloads. If a shader module wastes cycles fetching data it doesn't need, or fetches it in the wrong order, the pipeline stalls. Adaptive address generation at the shader level is a way to attack that problem before it starts, rather than compensating for it with bigger caches or faster memory buses.
For Samsung, which makes both consumer GPUs (via its Exynos SoCs) and produces chips for other companies' designs, a more efficient shader architecture has obvious appeal across mobile and server markets. This is incremental engineering work rather than a paradigm shift — but the kind of incremental work that quietly adds up in chip efficiency benchmarks.
This is solid, unglamorous GPU architecture work. The adaptive search-pattern idea is a real engineering refinement, not a marketing concept — and the dual-memory-pool design shows careful thinking about separating metadata from payload. It's not a patent that signals a dramatic new product direction; it signals that Samsung's GPU team is grinding through the details of shader efficiency, which is exactly what competitive chip design requires.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.