Nvidia Patents Software That Groups Similar Data Together Before Processing It
Before an AI model can learn anything, someone has to decide how to package the raw data. Nvidia's new patent describes a neural network that organizes that data automatically — grouping things that are alike, in sequence, before any learning even begins.
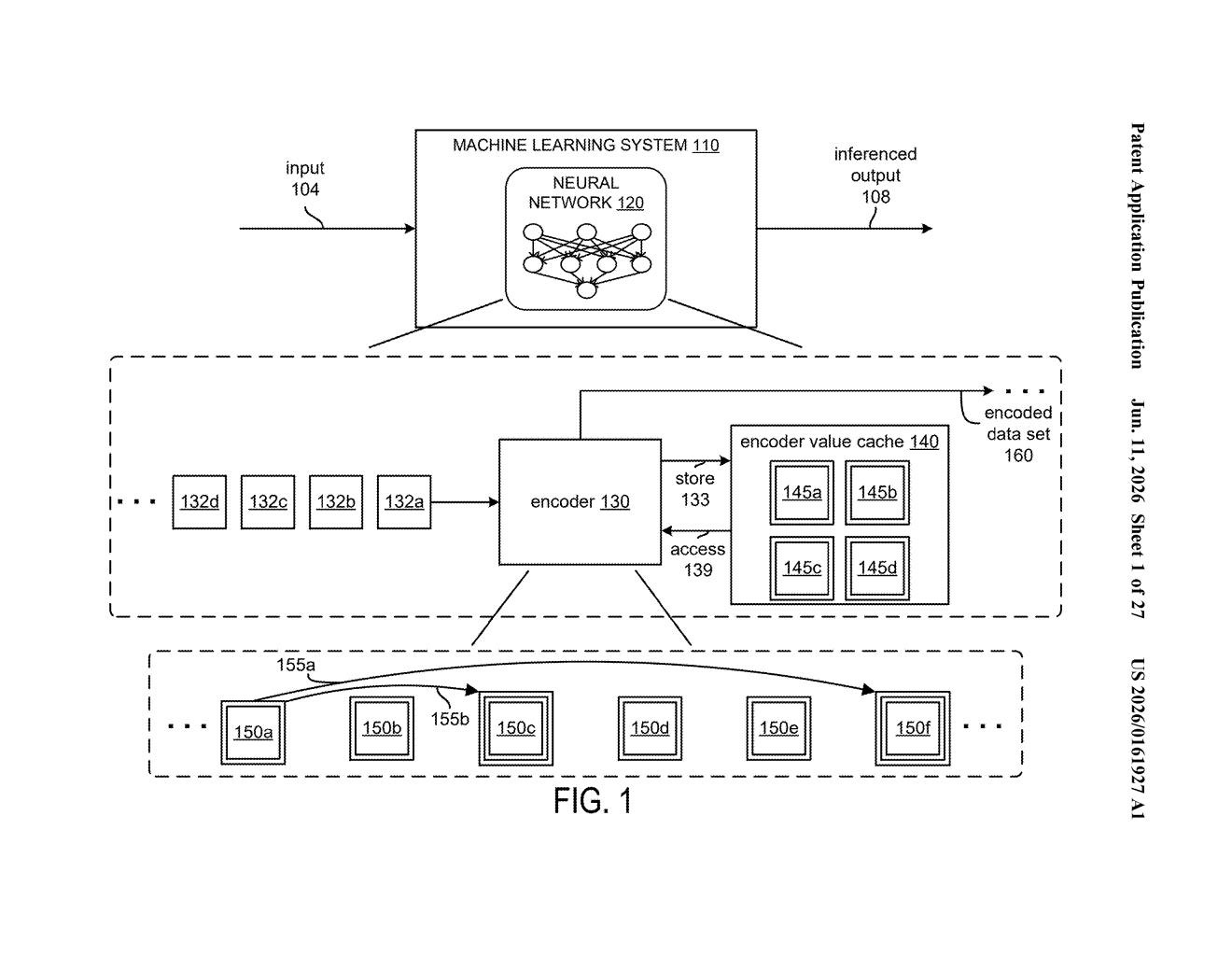
What Nvidia's similarity-based encoding actually does
Imagine you're packing boxes to move a house. You could throw everything in randomly, or you could pack similar items together — books with books, kitchen tools with kitchen tools — so unpacking is faster and less confusing. AI models face the same problem: raw data dumped in without structure slows everything down and makes patterns harder to find.
Nvidia's patent describes a system where a neural network takes an input dataset and automatically organizes it into an ordered sequence. The key is that items are arranged based on how similar they are to each other — things that resemble one another end up close together in the sequence, not scattered randomly.
The idea is that by encoding data this way, whatever AI model receives it downstream has a much easier job spotting patterns, learning relationships, and producing accurate results. Think of it as a smarter filing system built into the very first step of how data gets prepared.
How the network measures and sequences encoded values
The patent describes a processor with dedicated circuits that invoke one or more neural networks to perform a specific kind of data encoding. Rather than converting raw input into a flat or arbitrary list of encoded values, the system produces a sequence — an ordered series where the arrangement itself carries meaning.
The ordering is driven by similarity measurements: the system computes how closely related each encoded value is to others in the sequence, then uses those measurements to determine placement. Think of it like sorting search results by relevance rather than by the time they were uploaded.
- Input stage: A dataset is fed into the system.
- Encoding stage: One or more neural networks convert the raw data into encoded values (compact numerical representations).
- Ordering stage: Similarity scores between encoded values determine the final sequence order.
The patent is deliberately broad about what kind of data this applies to and what neural network architectures are used, which suggests Nvidia is staking out foundational ground rather than describing one narrow use case. The core claim is about the combination of neural encoding with similarity-driven sequencing as a unified step.
What this means for how AI models handle raw data
The quality of data encoding is one of the least-glamorous but most consequential parts of building an AI system. If data arrives at a model poorly organized, the model has to work harder to find structure — which means more computation, more training time, and often worse results. A system that bakes good organization into the encoding step could make downstream models more efficient across the board.
For Nvidia, which sells both the chips that run AI workloads and the software frameworks that manage them, owning a foundational patent on how data gets structured before processing could matter strategically. It's the kind of patent that touches nearly every AI pipeline rather than just one specific application.
This is a genuinely broad filing — broad enough that it's hard to pin down exactly what product or system it's aimed at. That breadth is either a sign that Nvidia is protecting a foundational technique with wide applications, or that the claim is too abstract to hold up under scrutiny. Either way, data encoding is real infrastructure work that affects AI performance at every level, so it's worth tracking.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.