Qualcomm Patents On-Device AI That Reads Mixed Inputs and Acts on Them
Qualcomm is patenting a way for a device's AI to simultaneously take in a photo, some text, and a voice clip — then figure out what to do with all of it, without sending anything to a cloud server.
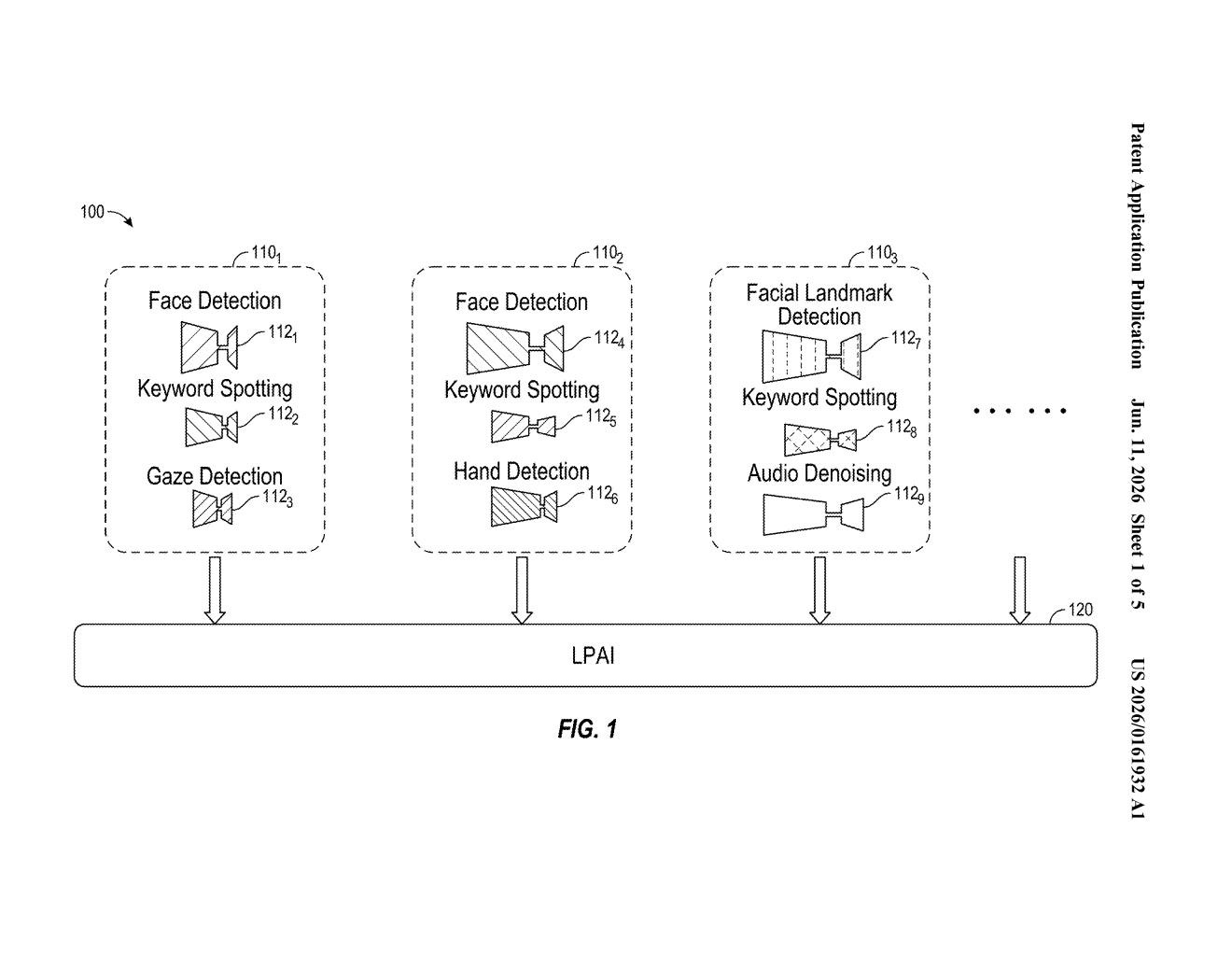
How Qualcomm's all-at-once input AI actually works
Imagine you point your phone at a restaurant menu, say 'find something vegetarian under $15,' and tap a dish you like. Today, most AI assistants handle those inputs one at a time, often by shipping your data off to a remote server. Qualcomm's new patent describes a system that processes all those different input types — images, text, voice — together, right on your device.
The system first compresses everything into a compact shared representation, then uses a generative AI model to write a plain-language description of what it understood. From there, the device takes whatever action fits — maybe pulling up a search result, opening an app, or drafting a reply.
The key engineering detail is that Qualcomm wants to run this on the device itself using smaller, distilled versions of larger AI models — meaning the heavy lifting happens in your pocket, not in a data center. That's a big deal for speed, privacy, and offline reliability.
Inside Qualcomm's encode-then-describe-then-act pipeline
The patent describes a four-step pipeline designed to run on a mobile or edge processor:
- Receive mixed inputs: The device accepts data from multiple modalities simultaneously — that could be an image, a block of text, an audio clip, a video frame, or any combination.
- Encode everything together: A multimodal encoder model (think of it as a universal translator that converts images, words, and sounds into the same mathematical format) generates a single compact representation of all the inputs at once.
- Generate a language description: A generative AI model — similar in concept to the technology behind ChatGPT, but compressed for on-device use — takes that compact representation and writes a natural-language summary of what the inputs mean collectively.
- Take action: The device uses that description to execute one or more follow-up actions, such as launching an app, returning search results, or composing a message.
A technically notable aspect is the use of model distillation — a process where a large, capable AI model is used as a teacher to train a smaller, faster student model that retains most of the performance. Qualcomm is explicitly calling out that its multimodal encoder was distilled this way, which is how the whole pipeline fits on a chip rather than requiring a server farm.
What this means for AI assistants running on your phone
On-device AI processing is Qualcomm's core commercial argument for its Snapdragon chips — the idea that your phone or laptop can run meaningful AI workloads without a constant cloud connection. This patent shores up the multimodal side of that story, which has been a weak spot: most on-device AI today handles one input type at a time, or routes complex queries to the cloud anyway.
For you as a user, a working version of this system would mean faster AI responses, no dependency on a Wi-Fi or cellular connection for complex tasks, and — potentially — better privacy since your photos and voice clips never leave your device. It also positions Qualcomm's silicon as the layer where this intelligence lives, which matters for every phone maker that relies on Snapdragon processors.
This patent is doing real work for Qualcomm's on-device AI strategy — multimodal input handling is genuinely one of the harder problems in edge AI, and the explicit call-out of model distillation shows they're thinking about the constraints of mobile hardware seriously. It's not flashy in isolation, but it's the kind of infrastructure patent that quietly underpins everything an AI assistant eventually does.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.