Xilinx Patents a System That Routes AI Workloads Better Than You Can
What if the chip system running your AI model knew better than you did about where to put each piece of it — and could quietly overrule your instructions to get better results? That's exactly what Xilinx is patenting.
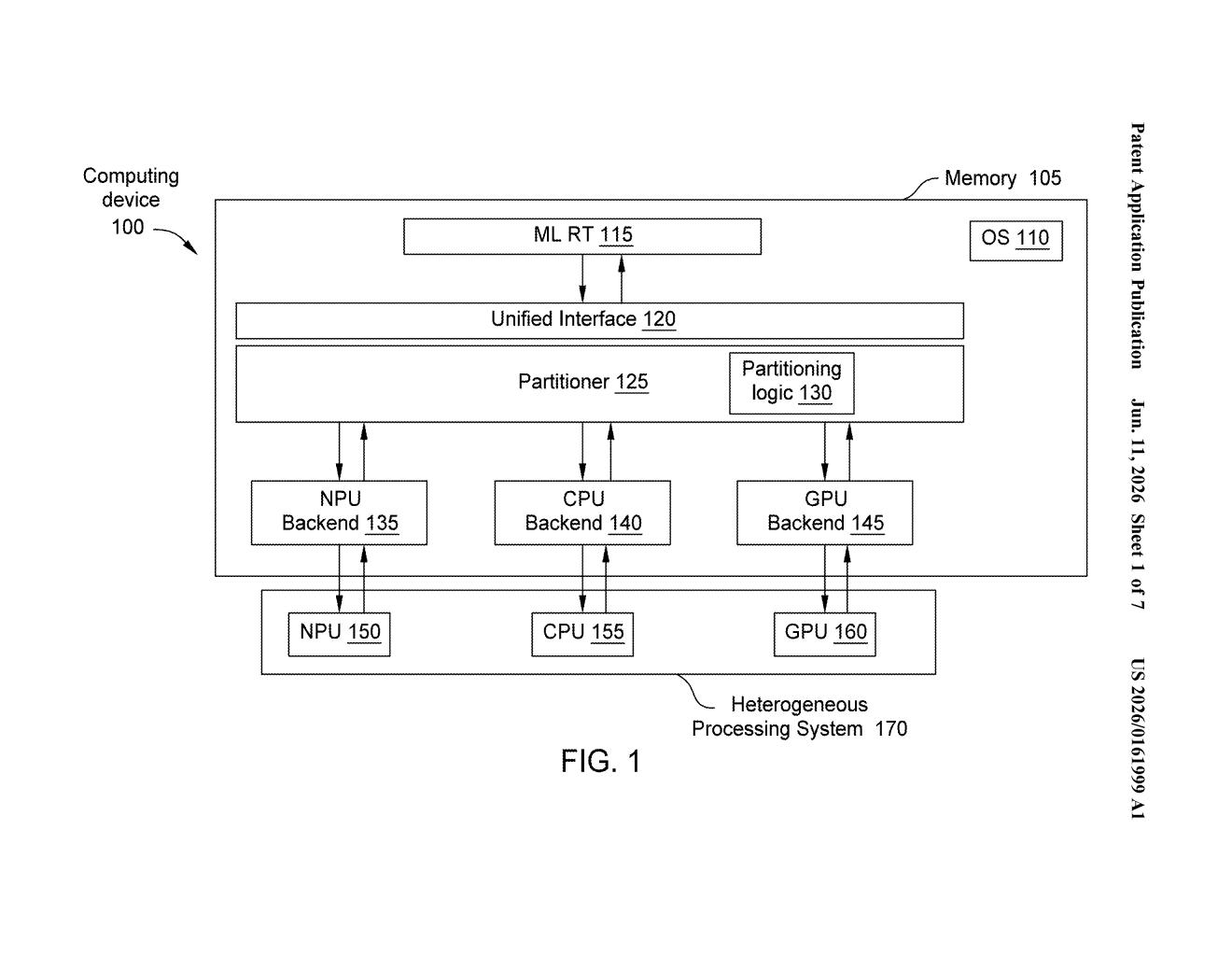
What Xilinx's processor-override system actually does
Imagine you're setting up a powerful computer to run an AI model — say, one that processes images or understands language. You tell it: "Run this part on the fast AI chip, and that part on the regular processor." But what if the AI chip is already slammed with other work, or barely has enough memory? Your instructions might actually slow everything down.
Xilinx's patent describes a system that watches all the processors in a device — an AI chip, a general-purpose processor, a graphics chip — and figures out in real time who has capacity, who's running hot, and who can handle which chunk of the AI model. It then spreads the work across those processors however makes the most sense, even if that means ignoring what you told it to do.
The key word in the patent is "violate" — the system is explicitly allowed to break user-entered instructions when the data says that's the smarter move. You still set preferences, but they're treated as suggestions the system can override.
How the unified interface decides to break your instructions
The patent describes a unified interface that sits on top of a device containing multiple different processor types — typically a Neural Processing Unit (NPU) (a chip purpose-built for AI math), a CPU (the general-purpose processor), and a GPU (originally for graphics, now widely used for AI).
When you load an AI model, the unified interface does a few things simultaneously:
- It polls each processor for its current capabilities — how busy it is, how much power it's drawing, and what kinds of AI operations it can run efficiently.
- It analyzes the AI model itself, breaking it into subgraphs (smaller chunks of the model's computation flow) to figure out which processor is best suited for each chunk.
- It generates a deployment strategy — a plan for which processor runs which piece — based on that live data rather than static user rules.
- If the strategy contradicts what the user specified, the system deploys according to its own plan anyway.
The key technical insight is that the system treats user preferences as soft constraints, not hard rules. Prior approaches locked the partitioning to whatever the developer specified at setup time, which means they couldn't adapt to changing workloads or hardware states.
What this means for AI chip efficiency at scale
For companies building AI-powered hardware — phones, laptops, data center accelerator cards — this kind of dynamic workload routing could meaningfully improve throughput and energy efficiency without requiring the developer to perfectly predict how the hardware will behave under real conditions. Xilinx, now part of AMD, makes exactly the kind of heterogeneous chips (FPGAs combined with CPU and AI cores) where this approach would be most useful.
For you as an end user, the implication is AI features that stay fast and responsive even when the device is under load — because the system is constantly rebalancing behind the scenes rather than following a rigid plan written before anything was actually running.
This is a genuinely practical patent addressing a real pain point in AI deployment: the fact that static partitioning instructions age badly once a device is running real workloads. The 'violate user instructions' framing is blunt, but the underlying idea — treat developer preferences as soft hints rather than hard rules — is sound engineering. Whether it ships as a discrete product or quietly powers AMD's AI PC stack, it's worth tracking.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.