Google Patents an AI Training Method That Protects User Data Without Sacrificing Accuracy
Training a recommendation AI on real user data is a privacy minefield. Google's new patent describes a way to do it with mathematical privacy guarantees — and a million-times reduction in the amount of data the model has to process per step.
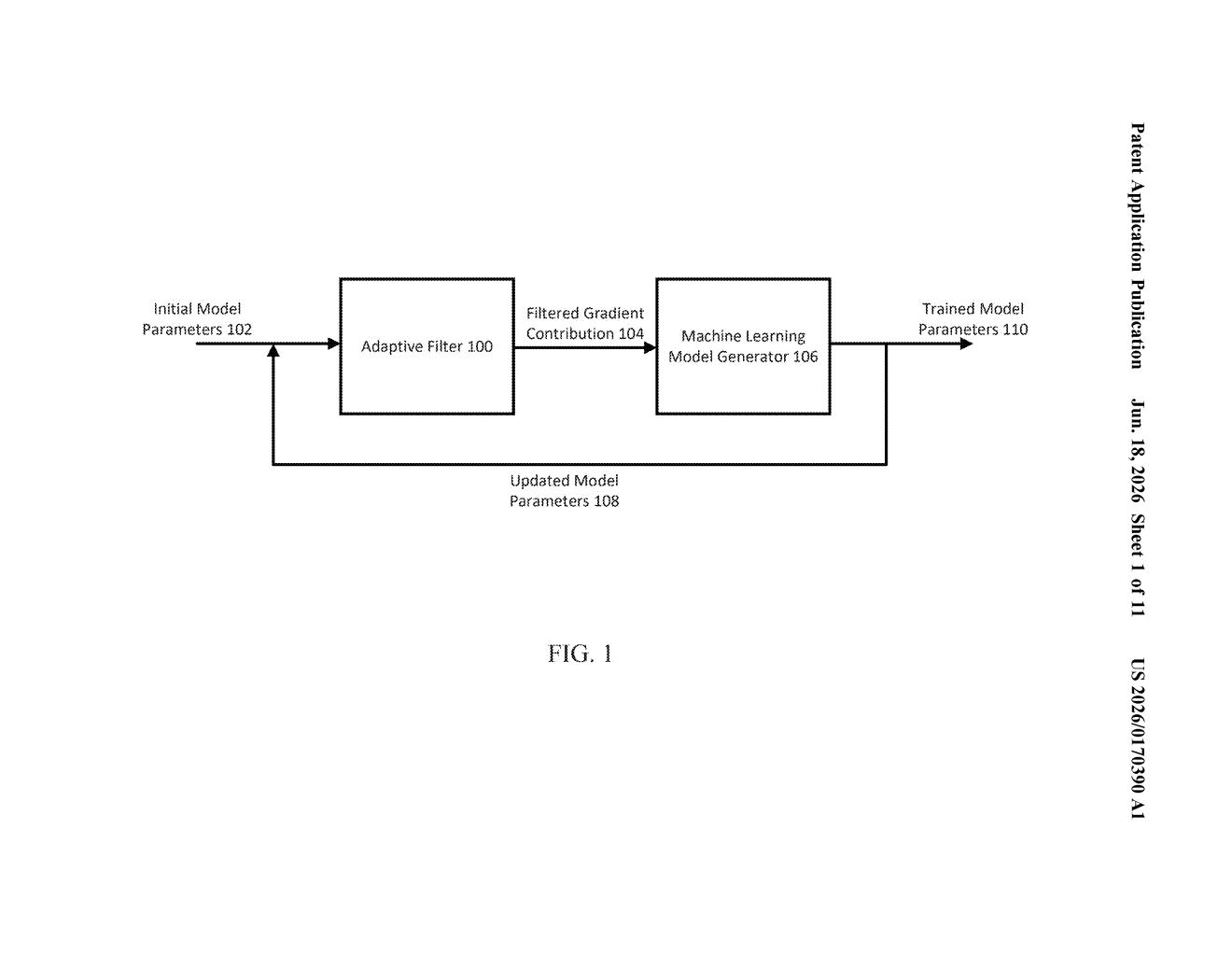
What Google's privacy-safe sparse training actually does
Imagine your streaming service wants to improve its recommendation algorithm using data from millions of real users. The problem: every time the system learns from your watch history, there's a risk it could inadvertently memorize private details about you.
Google's patent tackles this by injecting carefully calibrated random noise into the learning process — a technique called differential privacy — so the model can't reliably trace what it learned back to any individual. That part already exists. The new piece is what happens next: instead of letting all that noisy data slow everything down, the system filters out the vast majority of it, keeping only the signals that showed up frequently enough to be meaningful.
The result, Google claims, is a model that learns about as well as one trained without privacy protections, while processing roughly one million times less data per training step. For companies trying to train large AI models responsibly, that's a meaningful engineering improvement.
How the noise-then-filter pipeline preserves gradient sparsity
The patent describes a training pipeline for what are called sparse embedding models — a type of AI commonly used in recommendation systems (think: ranking search results, surfacing ads, or suggesting videos). These models are "sparse" because at any given step, only a small fraction of their parameters actually get updated.
The core challenge: when you add privacy-protecting noise to a sparse model, the noise tends to fill in all the gaps, making the model dense and computationally expensive. Google's approach preserves the sparsity through a two-stage process:
- Noise injection: Random noise is added to the raw gradient contributions (the signals that tell the model what to adjust), making it impossible to isolate any individual user's influence on the result.
- Frequency filtering: The noisy gradient is then filtered based on how often each signal appeared across the training batch — rare signals get dropped, frequent ones survive. This is the key innovation that keeps the update sparse.
- Model update: Only the filtered, still-sparse gradient is used to adjust the model's parameters.
The patent also describes an adaptive variant where the filtering threshold adjusts dynamically during training. The claimed reduction in gradient size — up to 10⁶ (one million) times — comes from aggressively discarding low-frequency gradient components that would otherwise bloat the computation.
What this means for AI models trained on personal data
Large embedding models sit at the heart of nearly every major recommendation system — Google Search, YouTube, Google Shopping — and training them on real user behavior is how they get good. Differential privacy has long been the gold standard for doing that responsibly, but it's traditionally come with a steep performance cost. A method that closes that gap would make it easier for Google (and anyone following the same approach) to deploy privacy-safe AI at scale without compromising on relevance.
For you as a user, this is the kind of foundational work that could mean your data is used to improve a product in a way that's verifiably private — not just promised to be. It's also the kind of patent that matters in regulatory conversations about AI and data protection.
This is genuinely interesting infrastructure work. The million-times gradient reduction claim is the kind of number that either holds up under peer scrutiny or doesn't — but if it does, it represents a real step toward making privacy-preserving AI training practical at Google's scale. It won't make headlines outside of ML research circles, but it's the sort of filing that quietly reshapes how responsible AI training gets done.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.