Nvidia Patents a Way to Blend Real Voices Into New Synthetic Ones
Nvidia has filed a patent for a text-to-speech system that doesn't just copy a single speaker's voice — it blends two or more voice 'fingerprints' together to produce an entirely new synthetic voice that belongs to no one.
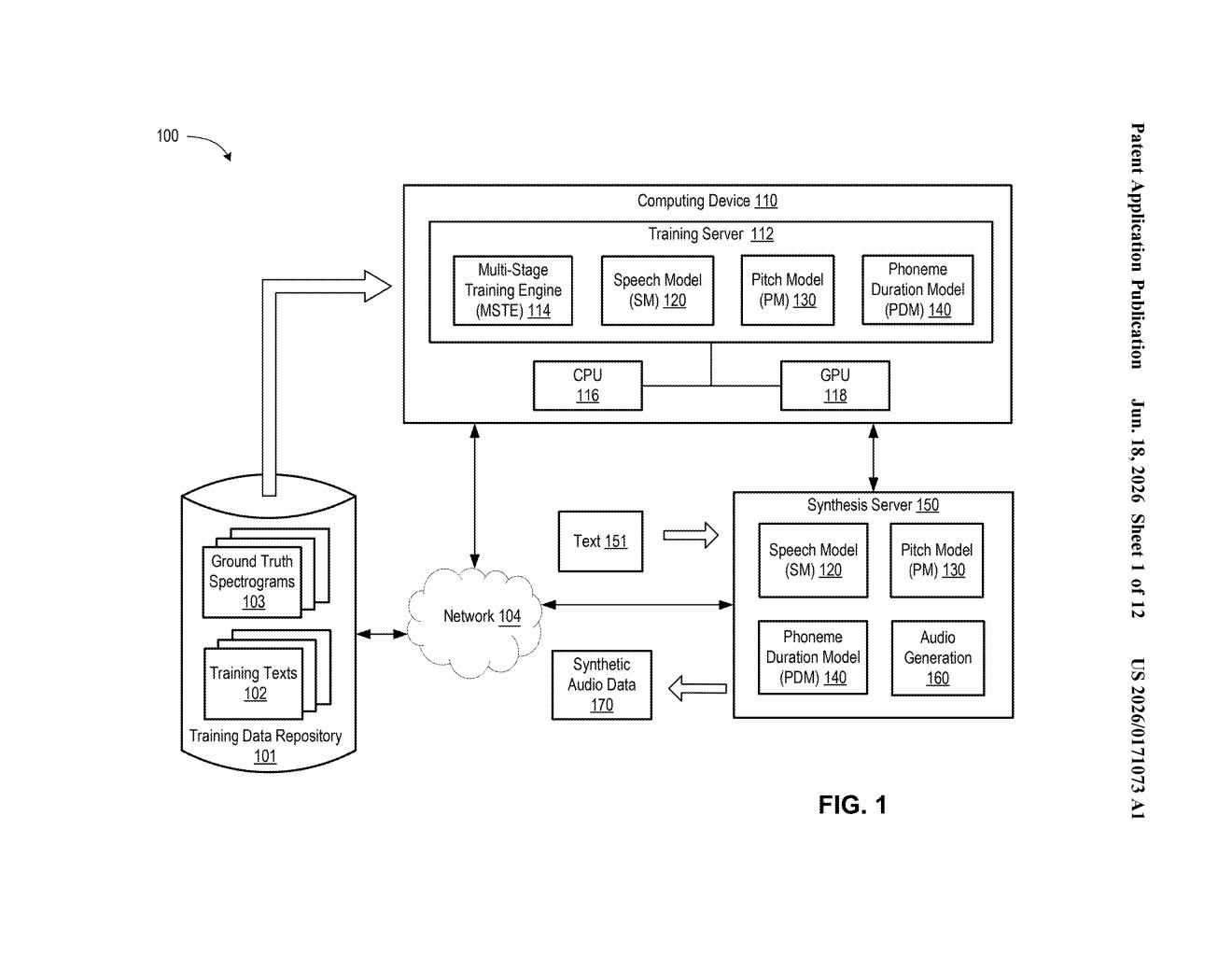
How Nvidia's voice-blending system actually works
Imagine a paint-mixing machine, but for voices. Instead of red and blue making purple, you feed it recordings of two different speakers, and it creates a new voice that sits somewhere between them — not quite either person, but a brand-new synthetic identity.
That's the core idea here. Nvidia's patent describes a system where a machine learning model learns what makes each speaker's voice distinct — call it a voice fingerprint — and then lets you dial between multiple fingerprints to generate a completely new one. The resulting voice never belonged to any real person.
The twist that makes this more than a basic mashup: Nvidia's training process starts the model on lower-quality audio recordings and gradually feeds it cleaner, higher-quality speech as training progresses. The idea is that the model builds a broad understanding of speech first, then refines it — similar to how a music student might learn rhythm before worrying about perfect pitch.
How the model trains on progressively cleaner audio
The patent centers on what are called speech embeddings — numerical representations (think of them as compact fingerprints) that capture the unique acoustic character of a speaker's voice. A machine learning model learns these embeddings from real speech recordings.
The key step is interpolation (blending): instead of using one embedding directly, the system computes a weighted average of two or more embeddings to create a synthetic embedding that corresponds to no real speaker. Feed that synthetic embedding into a text-to-speech model, and you get audio in a voice that has never existed before.
The other distinctive piece is multi-stage training. Rather than training the model on a fixed dataset from the start, Nvidia's approach begins with lower-quality audio and progressively introduces higher-quality recordings as training continues. This curriculum-style approach — common in how humans learn skills — is meant to produce better, more general voice representations.
Put together, the system can:
- Learn voice fingerprints from real speakers
- Blend those fingerprints into new, non-existent voices
- Generate spoken audio in those blended voices from text input
What this means for AI-generated voices and digital assistants
For Nvidia, which sells the hardware that powers most large AI model training, this patent plants a flag in the text-to-speech software space. Synthetic voice generation is a fast-growing area — used in everything from audiobook narration and game characters to voice assistants and accessibility tools. A system that can produce novel voices on demand, rather than cloning a specific person's voice, sidesteps some of the ethical and legal landmines around voice cloning.
For you as a user, the downstream effect could be AI assistants or apps that let you pick a voice that isn't tied to any real celebrity or actor — something original. The progressive training approach is also worth noting: it's a technique that could apply well beyond speech, making this patent relevant to how Nvidia might train audio AI models more broadly.
This is a tidy, well-scoped patent that addresses a real problem: voice cloning is legally and ethically fraught, but demand for diverse synthetic voices is real. Blending embeddings to create voices that belong to no one is a practical workaround, and the curriculum-training angle adds genuine technical substance. It's not a flashy consumer announcement, but it's the kind of infrastructure IP that could quietly underpin a lot of AI audio products.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.