Nvidia Patents Software That Turns Still Images Into Smooth, Consistent Video
Nvidia is patenting a way to generate video that stays visually consistent frame-to-frame — by training neural networks on 3D point clouds, a kind of depth-mapped snapshot of a scene.
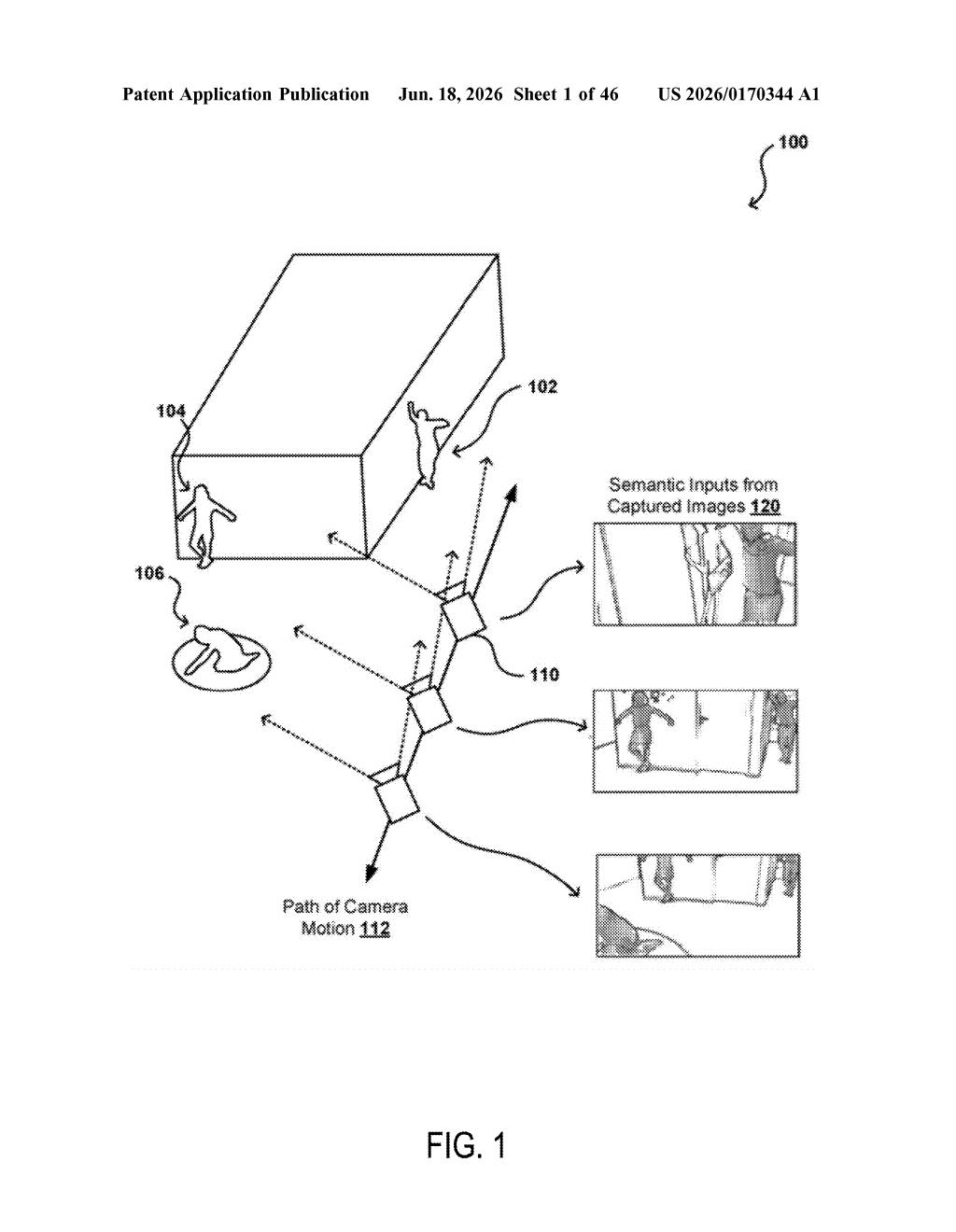
How Nvidia turns 3D scans into smooth video frames
Imagine watching a video where the camera slowly moves through a room. For that footage to look real, every frame has to agree on where walls, furniture, and light sources are. If they don't, you get flickering or objects that seem to jump around — a giveaway that something's been artificially generated.
Nvidia's patent describes a system where a neural network uses point clouds — think of these as thousands of tiny dots mapping out the 3D shape of a real scene — as a guide for generating new video frames. Instead of inventing each frame from scratch, the network anchors itself to that 3D dot-map and works from there.
The goal is consistency: the kind where objects stay in the right place and lighting feels stable as the video plays. This has obvious value anywhere synthetic or AI-generated video needs to hold up to real scrutiny — whether that's film production, game engines, or autonomous vehicle simulation.
How point cloud data feeds the video synthesis pipeline
The patent describes a processor with circuits that run one or more neural networks tasked with generating new images — or sequences of images, i.e., video — by drawing on point cloud representations of source images.
A point cloud is a collection of data points in 3D space, each marking a surface location captured by depth sensors or reconstructed from photos. Think of it like a connect-the-dots drawing in three dimensions. By encoding source images into this format first, the system gives the neural network a structured spatial understanding of the scene before it starts synthesizing new frames.
The key claim is that the generated frames are informed at least in part by those point cloud inputs — meaning the 3D geometry acts as a constraint. This is different from purely pixel-based generation, where the network has no explicit sense of physical depth or structure.
- Input: One or more existing images converted to point cloud form
- Process: Neural network(s) interpret the 3D spatial data
- Output: New synthesized images or video frames that respect the underlying 3D geometry
What this means for synthetic video and game graphics
Consistency is the hardest problem in AI-generated video. Current tools often produce frames that look plausible in isolation but drift or flicker when played back — objects shift slightly, textures change, lighting feels unstable. Using a 3D point cloud as a structural backbone is a practical approach to keeping frames anchored to a shared sense of space.
For Nvidia, this fits squarely into its existing work on simulation for autonomous vehicles (through its DRIVE platform) and its Omniverse 3D collaboration environment, both of which need photorealistic synthetic video that behaves like the real world. If this approach works at scale, it could also strengthen AI video generation tools — the kind that compete with Sora or Runway — by making them more geometrically reliable.
This is a technically credible patent from a team — Mallya, Wang, Liu, and Sapra — with a solid publication record in video synthesis research, including the GauGAN and Vid2Vid lines of work. The abstract is deliberately sparse, but the underlying idea of grounding video generation in 3D point cloud data is a real and active research direction, not a placeholder filing. Worth watching as Nvidia builds out its generative media stack.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.