Microsoft Patents a Way to Help AI Models Search Databases by Meaning
When you ask an AI a question about a company's data, the AI has to go find the answer somewhere. Microsoft's new patent is about making that retrieval step far more accurate by teaching databases to index information the way AI actually thinks.
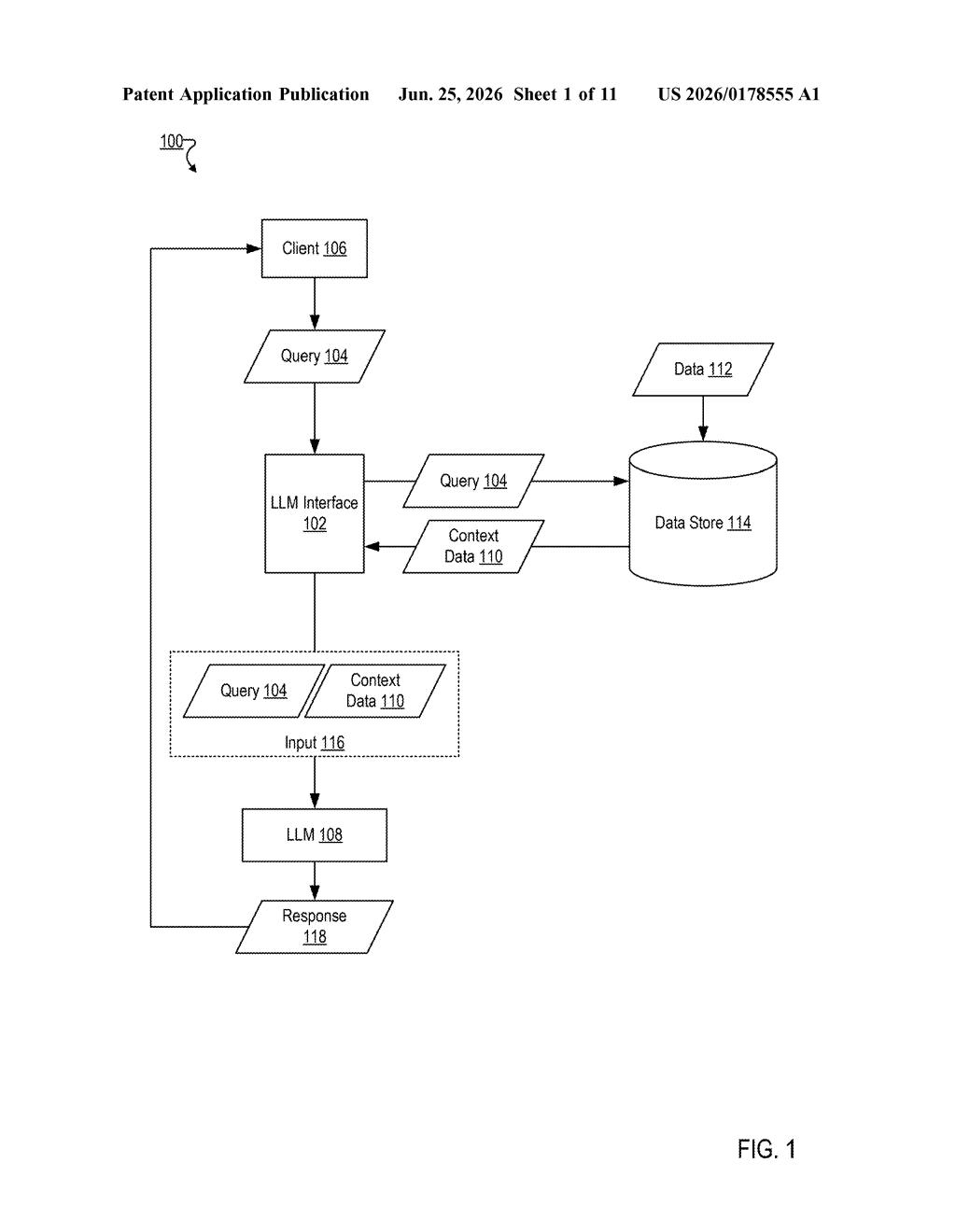
How Microsoft's semantic index helps AI read your data
Imagine asking a work chatbot: "Which customers complained about shipping last quarter?" The bot needs to go dig through a database to find the answer. Right now, that search often works like a basic keyword hunt, which means it can miss rows where someone wrote "delivery was late" instead of "shipping complaint."
Microsoft's patent describes a system that builds two kinds of indexes on a database table at once. For columns full of freeform text (like customer feedback), it creates a meaning-based index so that "delivery was late" and "shipping complaint" are treated as the same idea. For columns with exact values (like product IDs or dates), it keeps a traditional word-for-word index.
The result is that when an AI model asks a question, the database can return the most relevant rows, not just the ones that happen to use the exact same words. That's the core idea behind what's called retrieval-augmented generation, where an AI pulls real data before writing its answer.
How the vector and full-text indexes split the work
The patent describes a method for building a semantic index on a database table, designed specifically to work with language models (LMs) that use retrieval-augmented generation (RAG), a technique where an AI fetches relevant data from an external source before generating a response.
When a command is issued to index a table, the system automatically iterates over every column and decides how to index it:
- Vector index (for meaning-heavy columns): Text-heavy columns get converted into vector embeddings (mathematical representations of meaning, where similar phrases end up close together in a multi-dimensional space). These are stored as a vector index, enabling similarity-based search.
- Full-text index (for exact-value columns): Columns with structured or categorical data get a traditional full-text index, which is fast and precise for lookups on known values like IDs, names, or codes.
When a user's query arrives via a language model, it is converted into a search string and applied against this combined index. The system can then find rows that are semantically related to the query, not just rows that share the exact same words.
The key engineering decision is that the system picks the right index type per column automatically, rather than requiring a developer to configure each one manually.
What this means for AI tools built on top of databases
The practical target here is enterprise AI tools: internal chatbots, data assistants, or copilot-style features that need to pull accurate rows from company databases before answering a question. If the retrieval step is poor, the AI's answer is wrong regardless of how capable the underlying model is. Better indexing means fewer hallucinated answers.
For Microsoft, this fits squarely into its Copilot and Azure AI strategy, where enterprise customers want AI that talks to their existing SQL databases, not just pre-trained general knowledge. A system that automatically builds the right index type per column lowers the barrier for getting RAG working on real business data without requiring a data engineer to hand-tune every table.
This is infrastructure work, not a flashy consumer feature, but it's the kind of plumbing that determines whether enterprise AI tools actually give correct answers. Microsoft is trying to make RAG over SQL databases work well out of the box, and that's a real problem worth solving. If this ends up in Azure SQL or Fabric, it will matter a lot to the developers building on those platforms.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.