Microsoft Patent Reuses Voice AI Training Data Across Different Microphone Configurations
Training a voice AI from scratch for every new microphone setup is expensive and slow. Microsoft's new patent describes a way to take training data built for one device and mathematically reshape it to work on another.
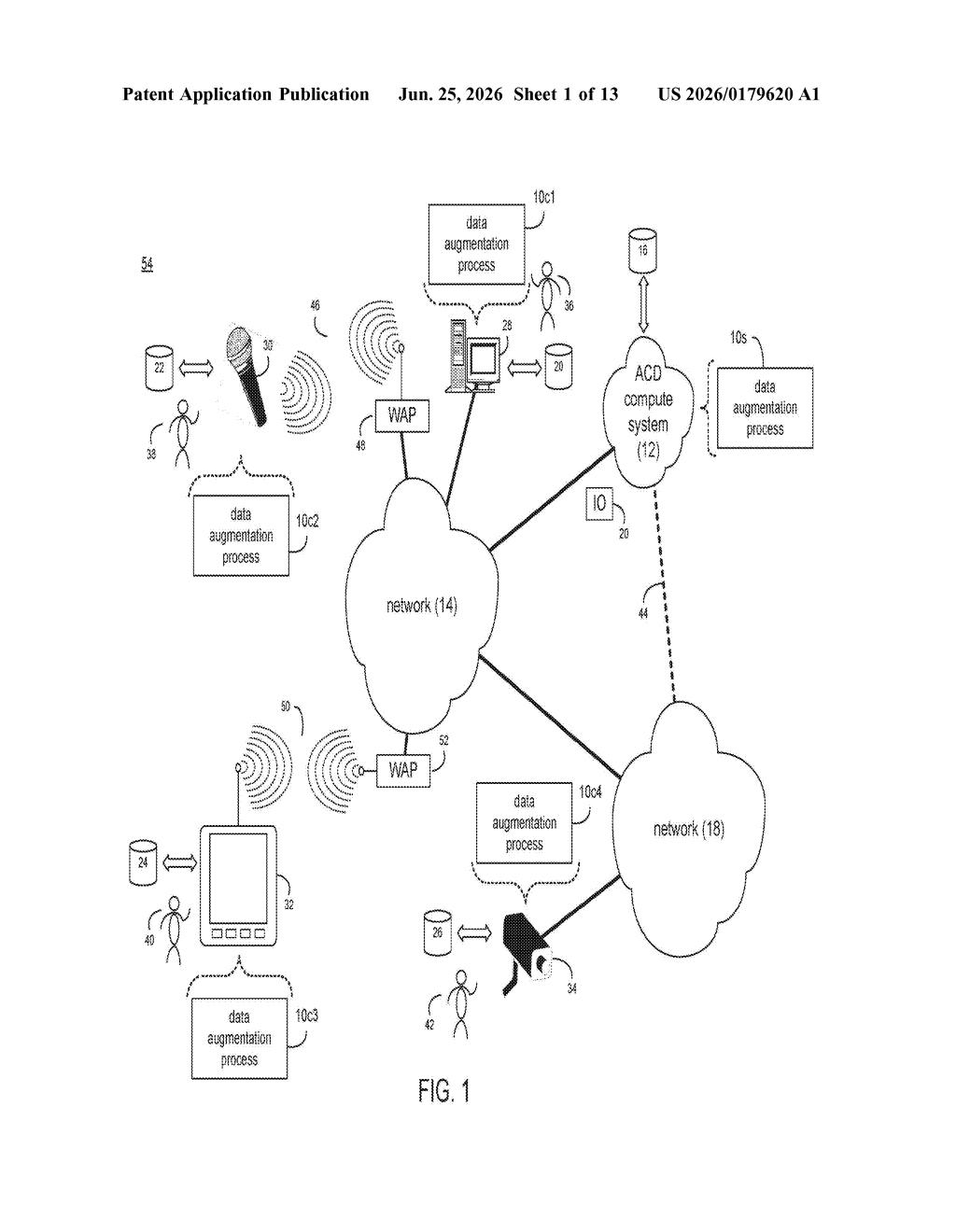
How Microsoft reuses voice training data across devices
Imagine you spend years teaching a voice assistant to understand you perfectly on your laptop. Then you buy a new smart speaker with completely different microphones, and the AI has to start from scratch, learning all over again. That's a real problem for companies building voice technology.
Microsoft's patent tackles this by measuring the acoustic "fingerprint" of two devices: how each one captures echoes, room noise, and the color of sound in a room. Once it knows the difference between the two, it can mathematically transform the old training data so it sounds like it was recorded by the new device.
The result is that a second device can be trained on augmented data built from the first device's library, without needing a massive new recording effort. For you as a user, the idea is that a new microphone-equipped product could get a well-trained voice model faster and more cheaply.
How the acoustic transfer function bridges two devices
The patent describes a pipeline with a few clear steps:
- Record speech on a first device (the one that already has a trained voice AI and a large library of training audio).
- Record the same or similar speech on a second device (the new hardware with different microphones).
- Compute an acoustic relative transfer function (RTF), which is essentially a mathematical description of how the two devices differ in capturing sound: things like how each microphone handles echoes bouncing off walls (reverberation) or background noise.
- Apply that RTF to the first device's existing training data to generate augmented training data that mimics how those recordings would have sounded on the second device.
- Use the augmented data to train a new speech processing ML model tailored to the second device.
The key insight is that the RTF acts as a translation layer. Instead of collecting thousands of hours of new recordings specifically for the second device, the system borrows from the first device's data and warps it to fit the new acoustic environment.
The patent covers both reverberation (room echo) and noise characteristics, meaning the transformation accounts for more than just microphone sensitivity differences.
What this means for Microsoft's voice AI products
Collecting and labeling audio training data is one of the most time-consuming and costly parts of building voice AI. Every time a company ships a product with a new microphone array, like a new laptop, headset, or conference speaker, they ideally want a model trained on audio that sounds like it came from that exact hardware. This patent gives Microsoft a systematic way to skip most of that recording work.
For Microsoft's product lineup, which spans Teams meetings, Surface devices, Xbox headsets, and Azure-based voice services, the ability to transfer a trained voice model to new hardware quickly is a genuine operational advantage. It could also make it easier to keep voice recognition quality consistent across the wide range of third-party devices that connect to Microsoft's cloud services.
This is solid, practical engineering rather than a flashy AI announcement. The problem it solves is real and unglamorous: voice AI breaks when you change the microphone. Microsoft is filing this at a time when it ships voice features across a large and diverse hardware ecosystem, so the business logic is clear. Don't expect a product launch announcement tied to this, but do expect it to improve the consistency of voice features across Microsoft's portfolio.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.