Meta Patent Uses Dual AI Models to Isolate Clean Audio Signals
Most audio cleanup tools treat noise removal as a single-step job. Meta's new patent splits the work across two AI models that were trained together to hand off the task in sequence, and that division of labor appears to produce cleaner results.
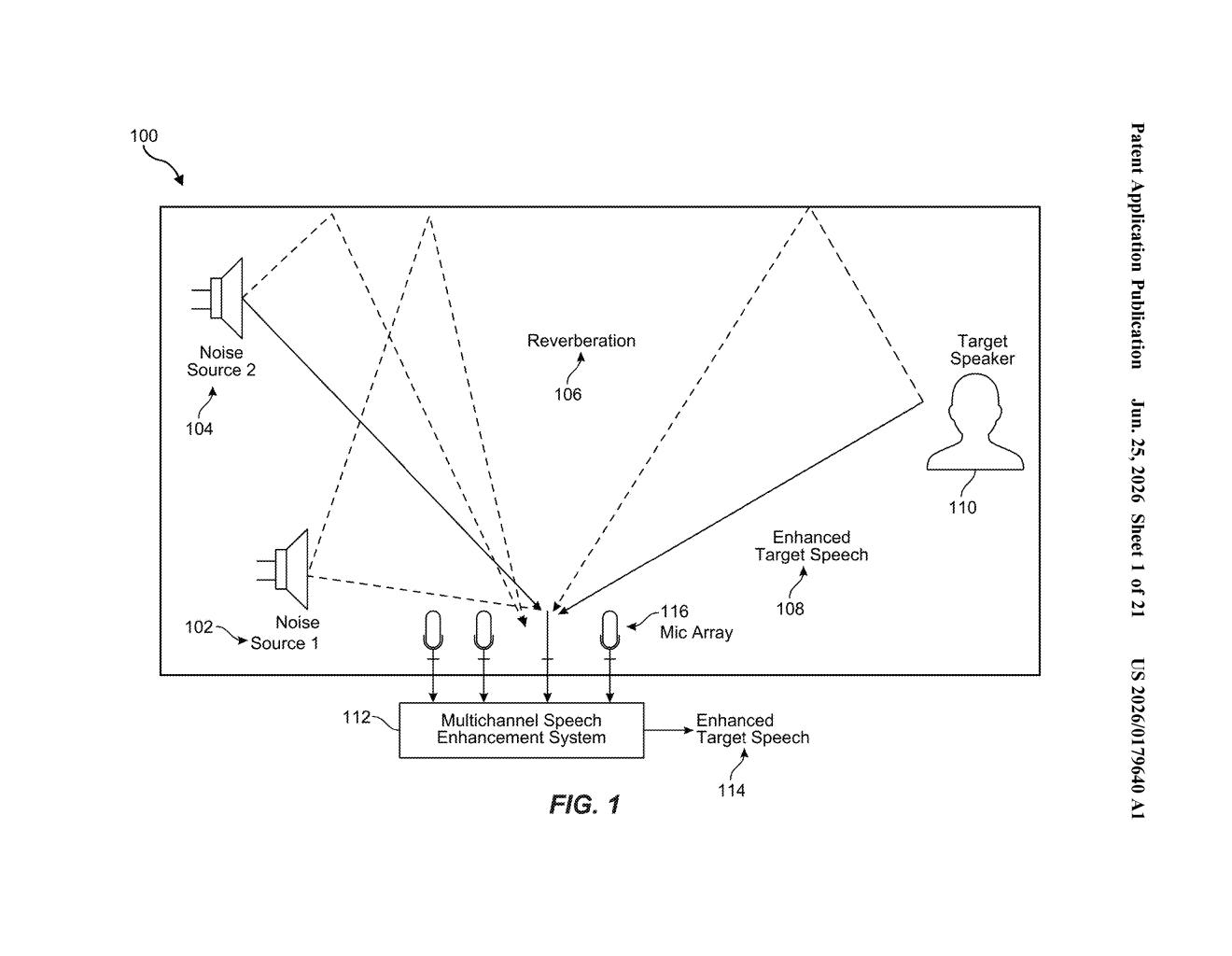
What Meta's two-step AI audio cleaner actually does
Imagine you're on a video call and a lawnmower starts up outside. Your device's audio system has to figure out which sounds are your voice and which are noise, then strip out the noise without making your voice sound robotic or hollow. That's a hard problem, and most systems make tradeoffs.
Meta's patent describes a smarter split: a first AI model listens to the raw audio and makes an educated guess about what the target sound (say, your voice) probably sounds like. That guess is then used to configure a traditional audio filter, which does a first pass of cleanup. A second AI model takes that filtered audio and polishes it further.
The key twist is that both models are trained together from the start, so they learn to cooperate rather than work independently. The first model learns to make guesses that are useful for the filter, and the second model learns to handle whatever the filter leaves behind.
How the estimate-then-filter pipeline is structured
The system chains two machine-learning models with a classical signal-processing step between them.
- The first model takes raw input audio and generates an "intermediate estimate" of what the target signal (usually speech) looks like on its own.
- That estimate, combined with the original audio, is used to calculate the parameters of an adaptive filter (a filter whose behavior changes based on the input, rather than being fixed).
- The adaptive filter runs on the original audio to produce a cleaner, filtered version.
- The second model takes that filtered audio and generates a final enhanced output.
The defining feature is joint end-to-end training, meaning both models are trained simultaneously on the same objective: make the final output sound as close to the clean target signal as possible. In most conventional pipelines, components are designed or trained separately. Here, the first model's behavior is shaped by how well the second model ultimately performs, so the two learn to complement each other.
Adaptive filters are well-established in audio engineering, but using a neural network to dynamically compute their parameters in real time is a more recent approach. Wrapping that inside a second neural network that refines the output adds another layer of correction for artifacts the filter introduces.
What this means for Meta's AR and VR audio hardware
Meta makes the Quest VR headsets and is deep in development on AR glasses (the Ray-Ban Meta line already has microphones). Both product categories depend heavily on audio quality: voice commands, calls, spatial audio, and passthrough communication all require good noise separation in real time on constrained hardware.
A two-model approach like this could allow Meta to tune the tradeoff between the two stages depending on the device. A lightweight first model and filter could run on a low-power wearable chip, with the second model adding refinement when more compute is available. Whether this shows up in a headset, glasses, or a future device isn't clear from the patent alone, but the direction is obvious: Meta wants cleaner voice audio without waiting for a single massive AI model to do all the work.
This is a solid audio-ML patent, not a flashy one. The two-model-plus-adaptive-filter structure is a genuine engineering idea, and the joint training angle is the part worth paying attention to. If you care about how AR glasses will handle calls in a noisy coffee shop, this is exactly the kind of foundational work that makes that possible.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.