Samsung Patents a Layer-by-Layer Method for Compressing AI Models
Running a powerful AI model on a phone means making it smaller without making it dumb. Samsung's new patent tackles exactly that tradeoff, layer by layer.
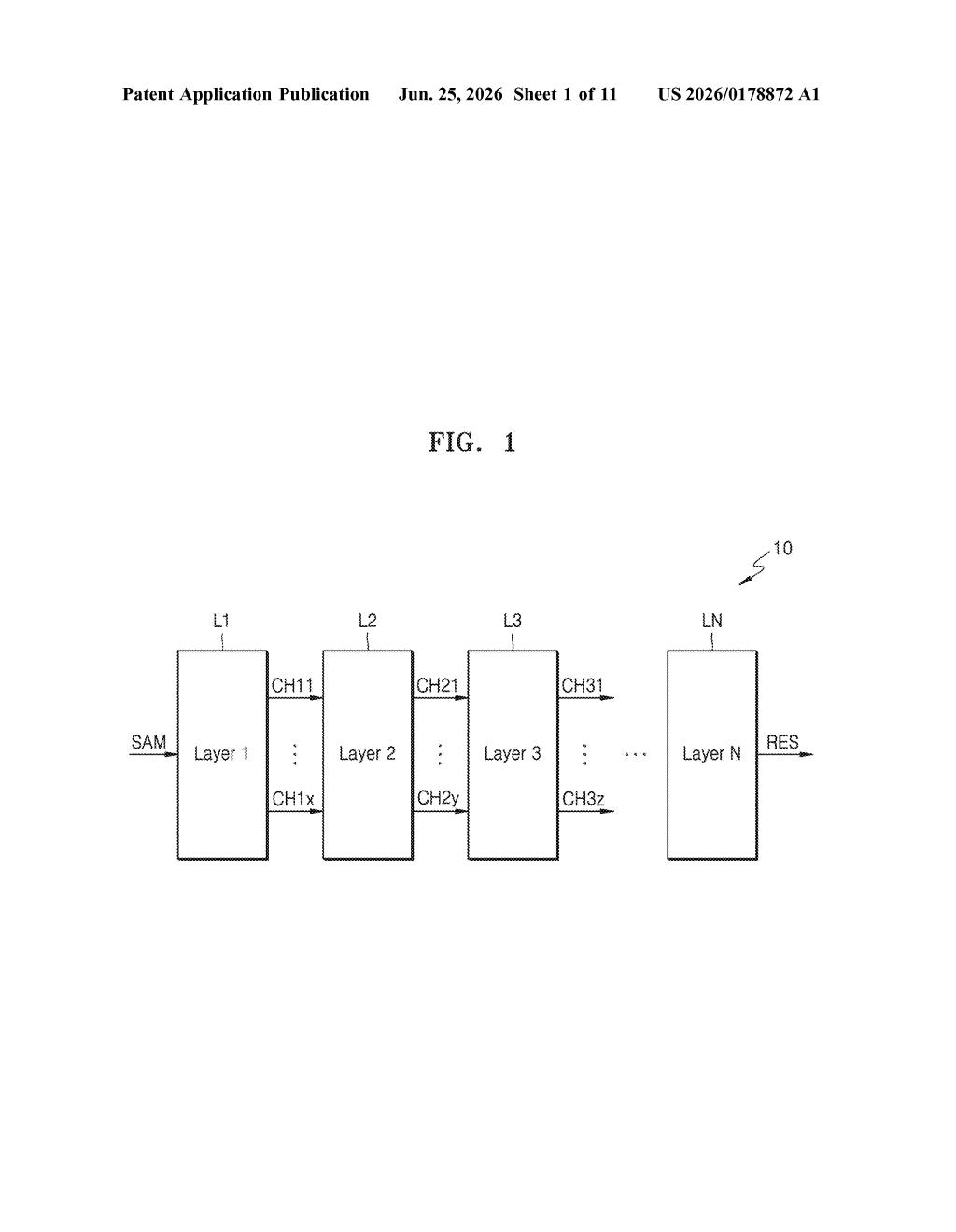
How Samsung's AI compression method actually works
Imagine a high-resolution photo that you need to send quickly. You could compress the whole image at the same quality level, or you could be selective: keep the sharpest detail where it matters most and blur the parts nobody notices. Samsung's patent applies that same logic to AI models.
AI models are made up of dozens or hundreds of layers, each doing a different piece of the calculation. This patent describes a system that figures out how sensitive each layer is to being simplified, then picks the right level of precision for each one individually. Some layers can afford to be rough; others need to stay accurate.
The goal is a model that runs faster and uses less memory on a device like a phone or tablet, without a noticeable drop in quality. That matters a lot when you want AI features that work locally on your device rather than sending your data to a server.
How the sensitivity baseline guides bit-width selection
Neural network quantization is the process of reducing how many bits a model uses to represent numbers internally. A standard AI model might use 32 bits per value; a quantized one might use 8, 4, or even fewer. Fewer bits means smaller files, faster math, and less battery drain, but push it too far and the model starts making mistakes.
Samsung's patent describes a more precise approach to this tradeoff. For each layer in a neural network, the system calculates a quantization sensitivity baseline set, essentially a profile of how much accuracy that layer loses at different precision levels. Think of it as a tolerance test: how much can you compress this layer before things go wrong?
With those profiles in hand, the system then evaluates candidate bit-width strategies (proposed plans for assigning precision levels across all layers) by estimating the total quantization error each plan would introduce. It picks the plan that keeps overall error lowest.
- Calculate per-layer sensitivity profiles across multiple bit-width options
- Score candidate precision plans based on predicted accuracy loss
- Select the best plan and apply it to the model
- Run multimedia processing tasks using the optimized model
What this means for AI on Samsung devices
On-device AI is only practical if the model fits in limited memory and finishes calculations before the user gets bored. Quantization is one of the main tools for getting there, and doing it layer-by-layer rather than uniformly is a meaningful efficiency gain. Samsung ships AI features across its Galaxy phone and tablet lineup, so a better compression pipeline directly affects how capable those features can be.
This patent is also notable for its focus on multimedia data specifically, which points toward use cases like photo processing, video enhancement, and audio tasks. If this method works as described, it could help Samsung pack more capable AI into mid-range devices where memory and compute are tight, not just flagship models.
This is solid, unglamorous engineering work. Quantization optimization is a real bottleneck in shipping AI to consumer hardware, and a more systematic sensitivity-based approach is genuinely useful. It's not a flashy consumer feature, but it's the kind of infrastructure patent that ends up inside products millions of people use.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.