Google Patents a Voice Dictation System That Corrects Its Own Transcription Errors
Google is patenting a dictation system that doesn't just transcribe what you say — it listens back to its own output and fixes mistakes before they reach the screen. The key trick: it processes your audio and the draft transcript at the same time to catch errors on the fly.
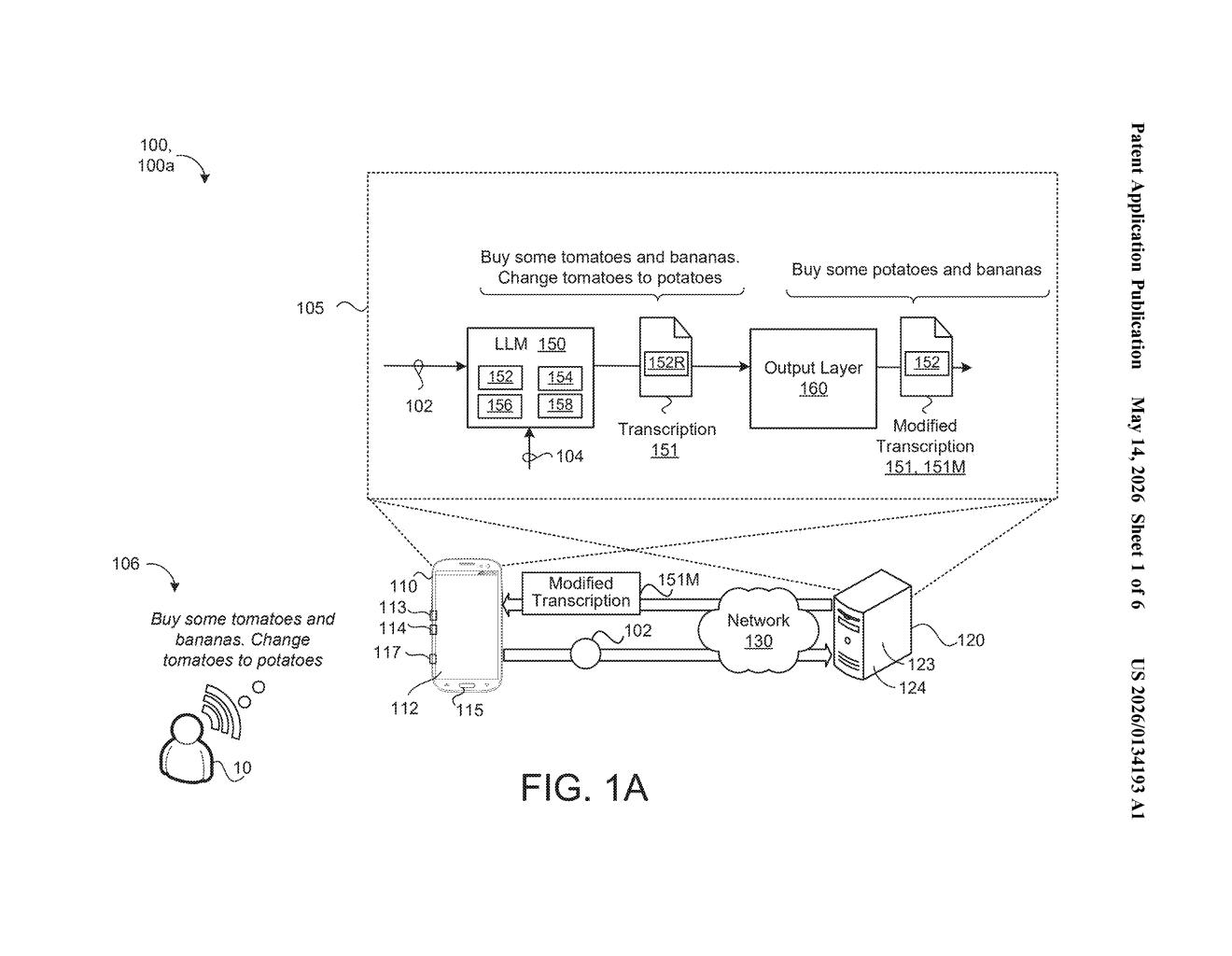
How Google's self-revising voice dictation actually works
Imagine you're dictating a text message and you mumble a word. Current voice-to-text either gets it wrong and shows you garbled text, or asks you to repeat yourself. Neither is great.
Google's patent describes a smarter approach: after generating a first-pass transcription of what you said, a multimodal AI model re-examines both the original audio and that draft text simultaneously. It's looking for "revision terms" — essentially flags in your speech that indicate something needs to change, like a corrected word or a deletion.
The system then edits the transcription automatically based on those flags. You don't have to tap, re-speak, or manually correct anything. The idea is that the AI catches its own mistakes the same way a human proofreader would — by reading back over the work with fresh context.
How the multimodal LLM spots and applies revision terms
The patent describes a four-step pipeline. First, the system captures audio of your spoken utterance. Second, it runs that audio through a model to produce an initial transcription — a sequence of text terms.
The third step is the interesting one. A multimodal large language model (LLM) — meaning a model that can process both audio signals and text together, not just one or the other — takes both the raw audio and the draft transcript as parallel inputs. It analyzes this combined input to detect what the patent calls "revision terms": specific words or signals in the transcription that indicate a correction action should be applied to one or more other terms nearby.
Finally, the system modifies the transcription based on whatever revision actions those terms specify. The claim is broad enough to cover deletions, substitutions, and insertions.
The parallel processing design is notable: rather than running a separate error-correction pass after transcription is complete, the model handles transcription and error-detection in a single unified inference step, which should be faster and more coherent than chaining two separate models together.
What this means for hands-free typing and voice UX
For everyday users, this is about making voice dictation less embarrassing to use in public. If the AI can silently fix its own errors without prompting you to repeat yourself, dictation becomes genuinely usable for longer-form writing — not just short commands to a smart speaker.
For Google, this fits squarely into its broader push to make Gemini-class multimodal models useful in productivity surfaces like Docs, Messages, and Pixel's voice features. A dictation engine that self-corrects using audio context — rather than just language statistics — could meaningfully close the gap between voice input and keyboard accuracy, which has been the stubborn ceiling on voice adoption for years.
This is a genuinely useful idea with a clean technical hook: running audio and text in parallel through a single multimodal model is a more elegant approach than the bolted-on correction layers most current dictation systems use. It's not flashy research, but it's exactly the kind of pipeline improvement that ships in a product. Watch for this in Pixel's Recorder or Gboard.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.