Meta Patents a Decentralized Group Audio System for Wearable Devices
Imagine a group of people all wearing AR headsets in the same room, all trying to talk at once — without a Wi-Fi router or cloud server to sort things out. Meta's new patent describes a clever self-organizing system that lets the headsets figure out who speaks when, entirely on their own.
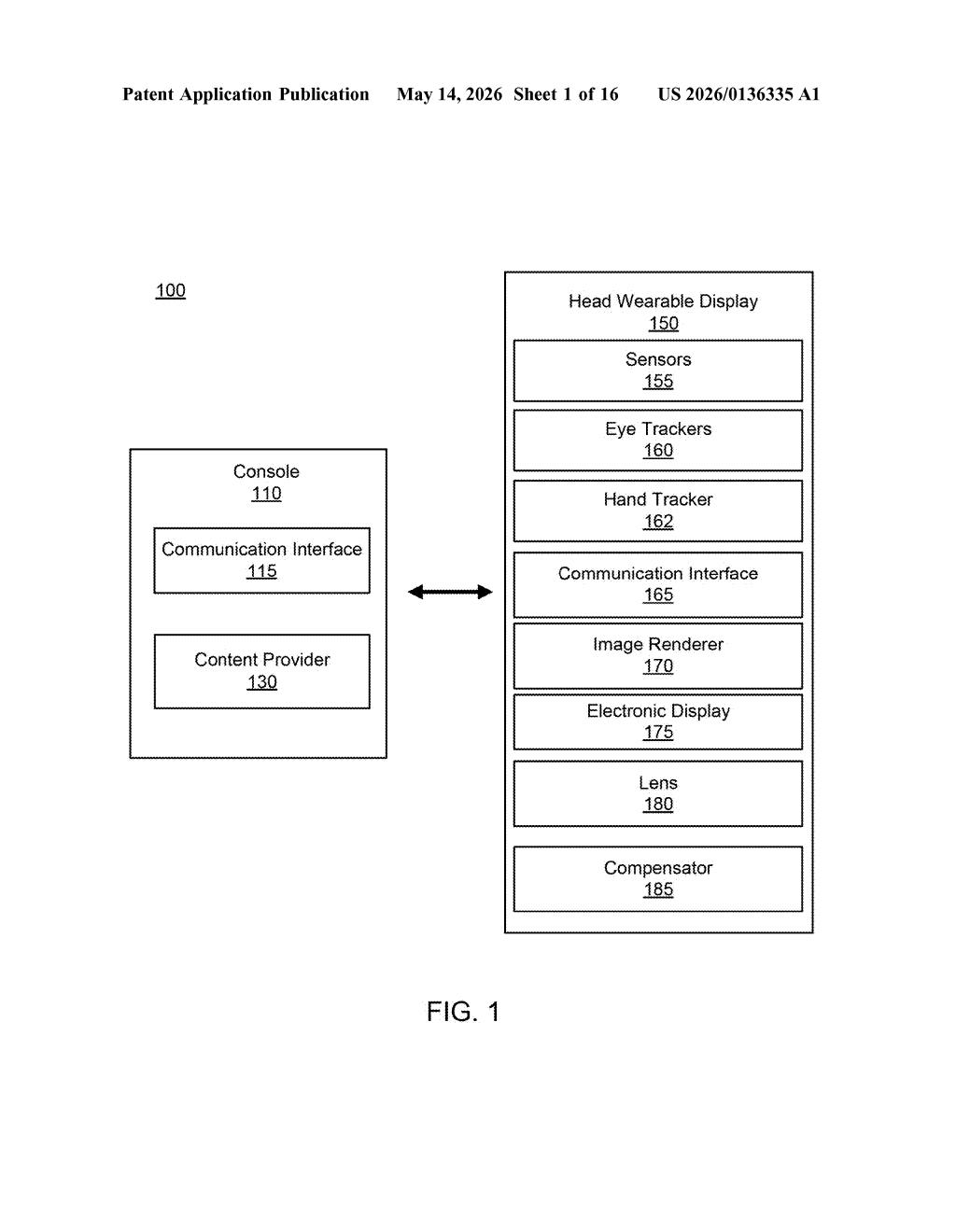
How Meta's headsets take turns talking without a server
Picture a group of friends wearing AR headsets at a concert, a theme park, or a warehouse floor where there's no reliable internet. Normally, a group voice chat needs a central server to coordinate who's talking. Meta's patent describes a way to skip that server entirely.
One headset acts as the coordinator — the "primary" device — and broadcasts a regular timing signal to everyone in the group. When you start to speak, your headset detects that and sends a quick request to the primary device asking for a speaking slot.
The primary device then assigns you a dedicated time window in its next broadcast, and your headset transmits your voice audio during that slot. Everyone else's headsets receive it directly. No internet, no server — just headsets talking to each other in an orderly queue.
How slot allocation keeps group audio from colliding
The system works using a time-division scheme — essentially a rotating schedule that prevents two devices from broadcasting audio at exactly the same moment (which would cause garbled overlap, the wireless equivalent of two people talking over each other).
The primary device continuously broadcasts a periodic "beacon" signal containing the parameters for the group session — things like timing structure and how to request a slot. Any secondary device in range can tune in and join.
When a secondary device's on-device sensor detects speech — likely via a microphone or a voice-activity detector — it sends a slot allocation request back to the primary. The primary's next beacon then includes an assignment: "device X, you get slot 3." The secondary device then broadcasts its captured audio only during that assigned window.
- Primary device: manages the beacon schedule and assigns speaking slots
- Secondary device: listens, detects speech, requests a slot, then transmits in its assigned window
- Sensor trigger: speech detection kicks off the whole request flow automatically
The patent specifically calls out a Head Wearable Display (HWD) as the target hardware, with references to eye trackers, hand trackers, and an image renderer — making it clear this is designed for AR/VR headsets, not generic Bluetooth earbuds.
What this means for AR glasses and shared spaces
The most obvious application is Meta's Ray-Ban smart glasses or a future Quest-class headset used in environments where cloud connectivity is unreliable or undesirable — think warehouses, outdoor events, or remote field work. By cutting out the server, you get lower latency and no dependency on a hotspot.
This also has implications for multiplayer AR experiences where co-located users need real-time voice coordination. As Meta pushes harder into the "presence" story for mixed reality, having a robust offline-capable voice layer is a quiet but meaningful infrastructure piece — the kind of thing you only notice when it's missing.
This is solid, unsexy infrastructure work — the kind of patent that quietly ends up inside a product rather than being announced at a keynote. Decentralized audio coordination for co-located AR devices is a real unsolved problem, and Meta clearly has a concrete architecture here. It's worth paying attention to if you follow spatial computing or Meta's hardware roadmap.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.