Nvidia Patents a Dynamic KV Cache Scheduler to Keep LLMs Running Smoothly
Every time you have a long back-and-forth with an AI chatbot, the model has to remember everything that came before — and that memory fills up fast. Nvidia's new patent tackles exactly this problem by building a smarter, tiered memory system for AI inference.
How Nvidia's KV cache trick keeps long AI chats alive
Imagine you're having a long conversation with an AI assistant. You've sent dozens of messages, asked follow-up questions, and the AI has been tracking everything. Under the hood, the model stores small "memory tokens" called KV pairs (key-value pairs) for every piece of that conversation — and GPU memory fills up surprisingly quickly.
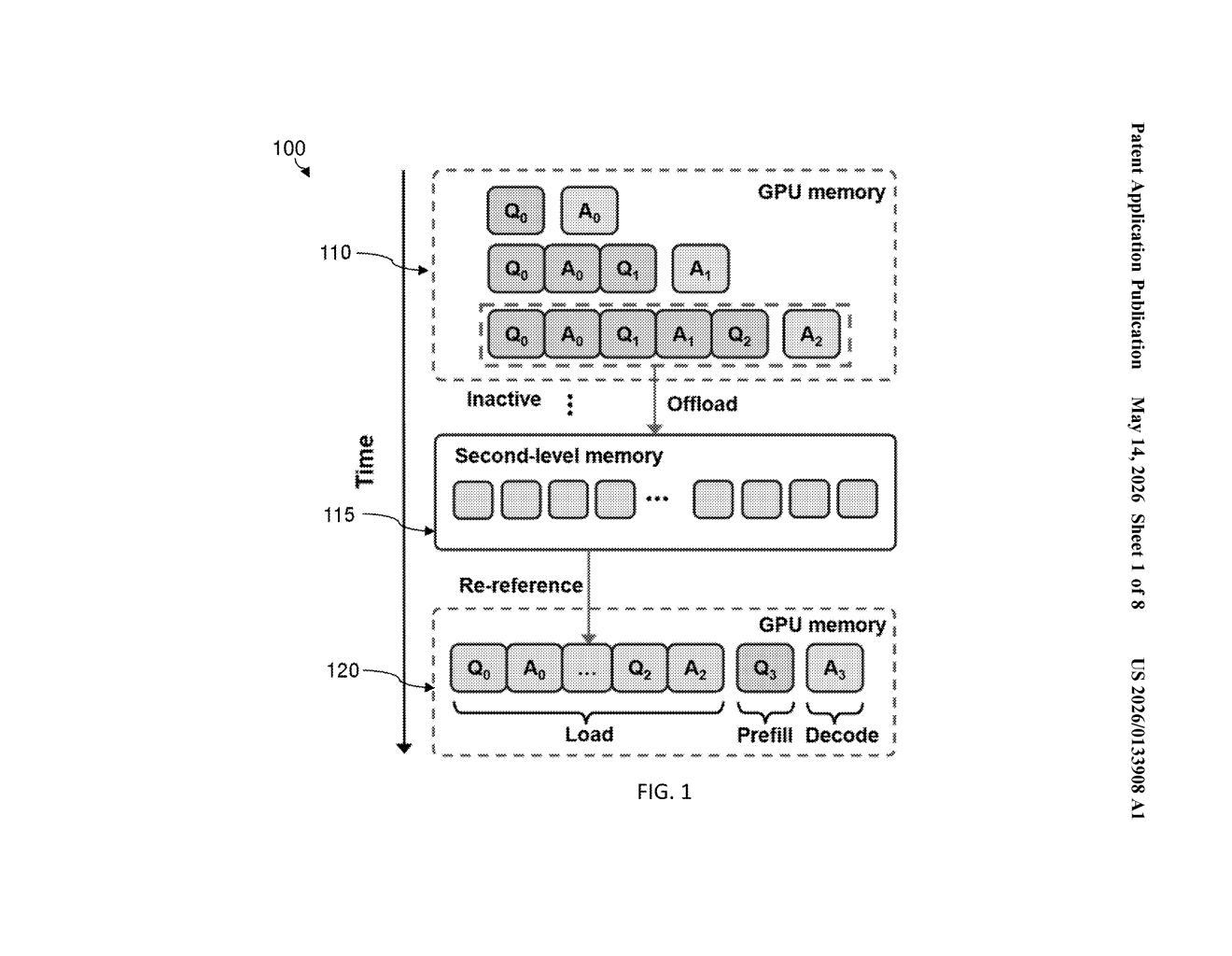
Nvidia's patent describes a system that automatically decides which of those memory tokens to keep close (in fast, on-chip GPU memory), which to park in slower nearby storage, and which to toss out entirely when they're no longer useful. Think of it like a chef who keeps today's mise en place on the counter, stashes yesterday's prep in the fridge, and throws away anything that's expired.
The clever part is that the system can reload a memory token from that slower storage the moment the model actually needs it again — so nothing important is truly lost, it's just stored smarter. This is especially useful for multi-turn conversations, where the AI needs to keep juggling context across many exchanges without grinding to a halt.
How the KV hierarchy moves pairs on and off the GPU
At the core of every transformer-based LLM is an attention mechanism — a process where the model looks back at everything it's seen so far to generate each new word. To do this efficiently, it stores precomputed key-value (KV) pairs (essentially cached attention data) so it doesn't have to recompute them from scratch every time.
The problem: in a multi-turn conversation, the number of KV pairs grows with every exchange. GPU VRAM is finite and expensive, so something has to give.
Nvidia's patent proposes a KV cache hierarchy — multiple tiers of storage, structured like this:
- On-processor cache (L1/L2 equivalent): Fast GPU memory holding KV pairs actively needed right now.
- Off-processor second-level memory: Slower memory (possibly HBM stacks or system RAM connected over a bus) where less-urgent pairs are "offloaded."
- Discard: Pairs deemed unlikely to be needed again are dropped entirely.
A scheduling policy continuously evaluates each KV pair — tracking things like recency and re-reference likelihood — and decides which tier it belongs in. Critically, if the model suddenly needs an offloaded pair during the current turn, the system reloads it just in time. This is essentially a demand-paging model (the same concept your OS uses when RAM fills up and swaps data to disk), but purpose-built for LLM inference.
What this means for long-context AI on constrained hardware
GPU memory is the single biggest bottleneck for running large language models — especially for long conversations or documents. Today, many inference systems either cap context length or require expensive multi-GPU setups to handle it. A smarter KV cache scheduler means you could run longer, richer conversations on the same hardware, which matters enormously for enterprise deployments and edge inference where you can't just throw more GPUs at the problem.
For Nvidia, this also dovetails neatly with its existing inference stack — TensorRT-LLM, NIM microservices, and the broader push to maximize throughput on H100 and Blackwell hardware. If this scheduling logic lands in software, it could quietly unlock longer context windows without any hardware upgrade.
This is solid, unglamorous systems work — the kind of optimization that doesn't ship as a product announcement but ends up mattering enormously at scale. KV cache management is a known pain point in LLM serving, and a principled hierarchical approach is the right direction. Don't sleep on this one just because it's a memory management patent.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.