Google Patents a Single Text Box That Finds Photos and Generates New AI Content From Them
What if you could type one message — 'Make a Father's Day card using a photo of Viktor and Hannah' — and your phone found the right photo *and* generated the card, all in one step? That's exactly what Google is patenting.
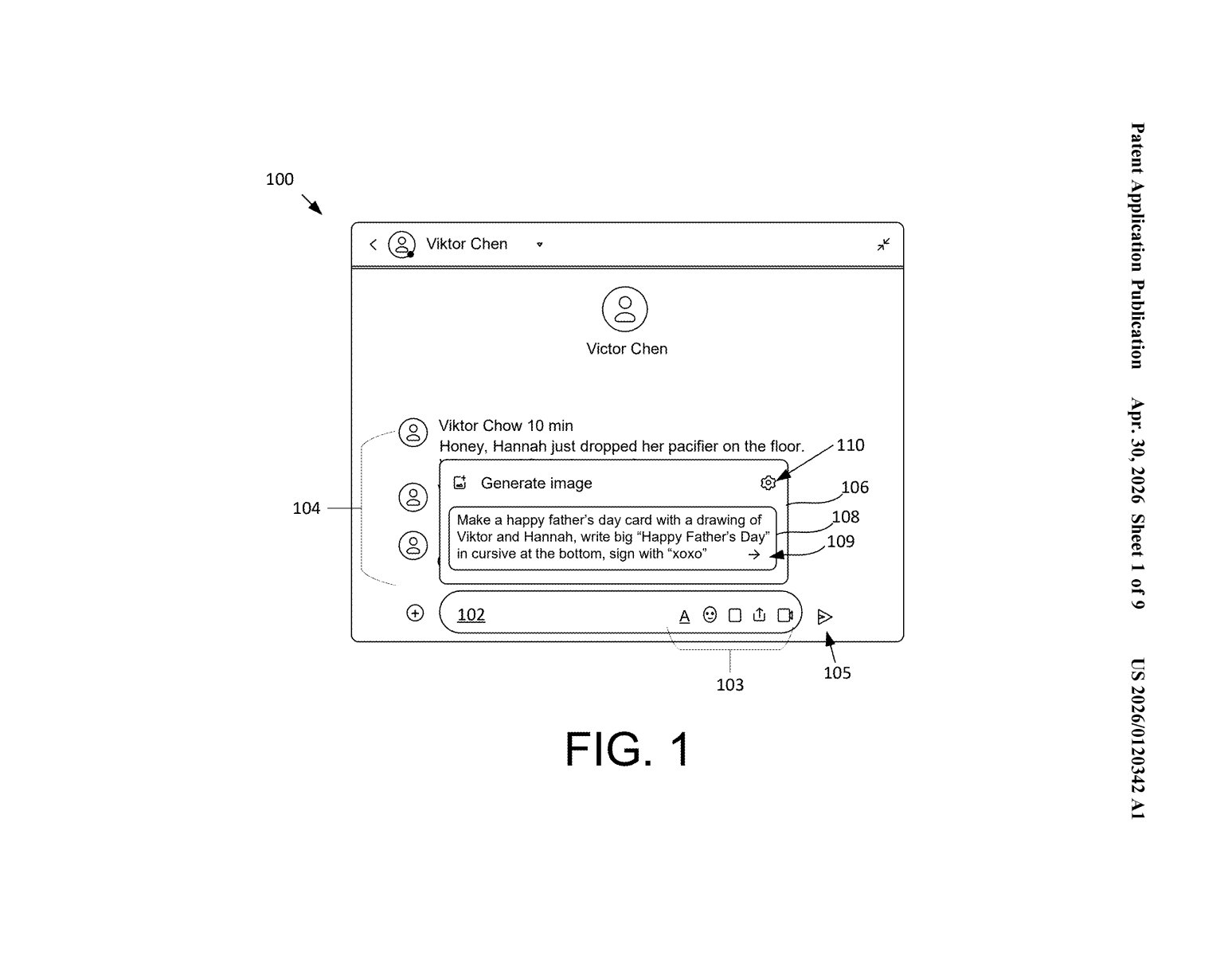
What Google's combined search-and-generate box actually does
Imagine you're texting a family member and want to whip up a quick greeting card. You type something like, 'Make a happy Father's Day card with a drawing of Viktor and Hannah, write Happy Father's Day in cursive at the bottom.' Right now, that would take at least three apps: your photo library, an AI image generator, and something to stitch it together.
Google's patent describes a single input box that handles the whole thing. You type your request once, and the system quietly splits it into two jobs: find the relevant content (like a photo of Viktor and Hannah from your library) and generate something new using that content as a creative starting point.
The result — a brand-new AI-generated image, card, or other media — gets handed off directly to whatever app you're using. No switching between apps, no hunting for the right photo first. It's the kind of 'just works' experience that sounds simple but requires a surprising amount of coordination under the hood.
How Google parses one input into two separate AI tasks
The patent describes a unified input pipeline that lives inside a user interface — think a chat-style text box or a share-sheet — and handles two fundamentally different tasks from a single typed request.
When you submit text, the system runs a parsing step that classifies parts of your input as either a content request (find me an existing item, like a photo or document) or a generation request (make something new based on instructions). These are treated as distinct sub-tasks, not a single blob.
The retrieval leg identifies a matching item — called the 'first content item' in the claim — from a content store like Google Photos. The generation leg then feeds that retrieved item plus the creative instructions into a generative model (almost certainly a diffusion or multimodal model) to produce a 'second content item.' The example in the patent's own figures shows a message thread where a user asks to generate a Father's Day card drawn in a specific style, signed with 'xoxo,' using real people as subjects.
Finally, the output is provided to an application — so the generated image could land directly in your Messages thread, a document, or a sharing UI without any manual export step.
What this means for Google Photos and on-device AI
Google Photos already has AI editing and search. Google's Gemini already generates images. What this patent describes is the glue layer between them — a single natural-language interface that collapses retrieve-then-generate into one seamless action. That's meaningful because the friction of switching between apps is often exactly what stops people from using AI tools at all.
For you as a user, this shows up most naturally in something like Google Messages or the Photos app: type a casual request, get a finished, shareable image back in the same thread. For Google, it's a strategic consolidation — if one text box can replace the need to open Gemini, Photos, and a design app separately, that's a stickier product and more data about how people want to use generative AI in real, everyday moments.
This is a genuinely clever UX patent, not just a feature patent. The hard part isn't retrieval or generation separately — it's the parsing logic that figures out which parts of your free-form request are 'find this' versus 'make that,' and then chains them together fluidly. Google is essentially patenting the interface pattern for grounded image generation, and given that the patent's own figures show a real messaging UI, this is almost certainly headed for Google Messages or Google Photos sooner rather than later.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.