Microsoft Patents a 2D Parallel Method for Cheaper Transformer Self-Attention
Training large language models on very long documents is expensive — partly because the math that lets tokens 'attend' to each other gets brutally slow at scale. Microsoft's new patent describes a smarter way to split that math across a grid of processors so the work gets done in parallel without the usual bottlenecks.
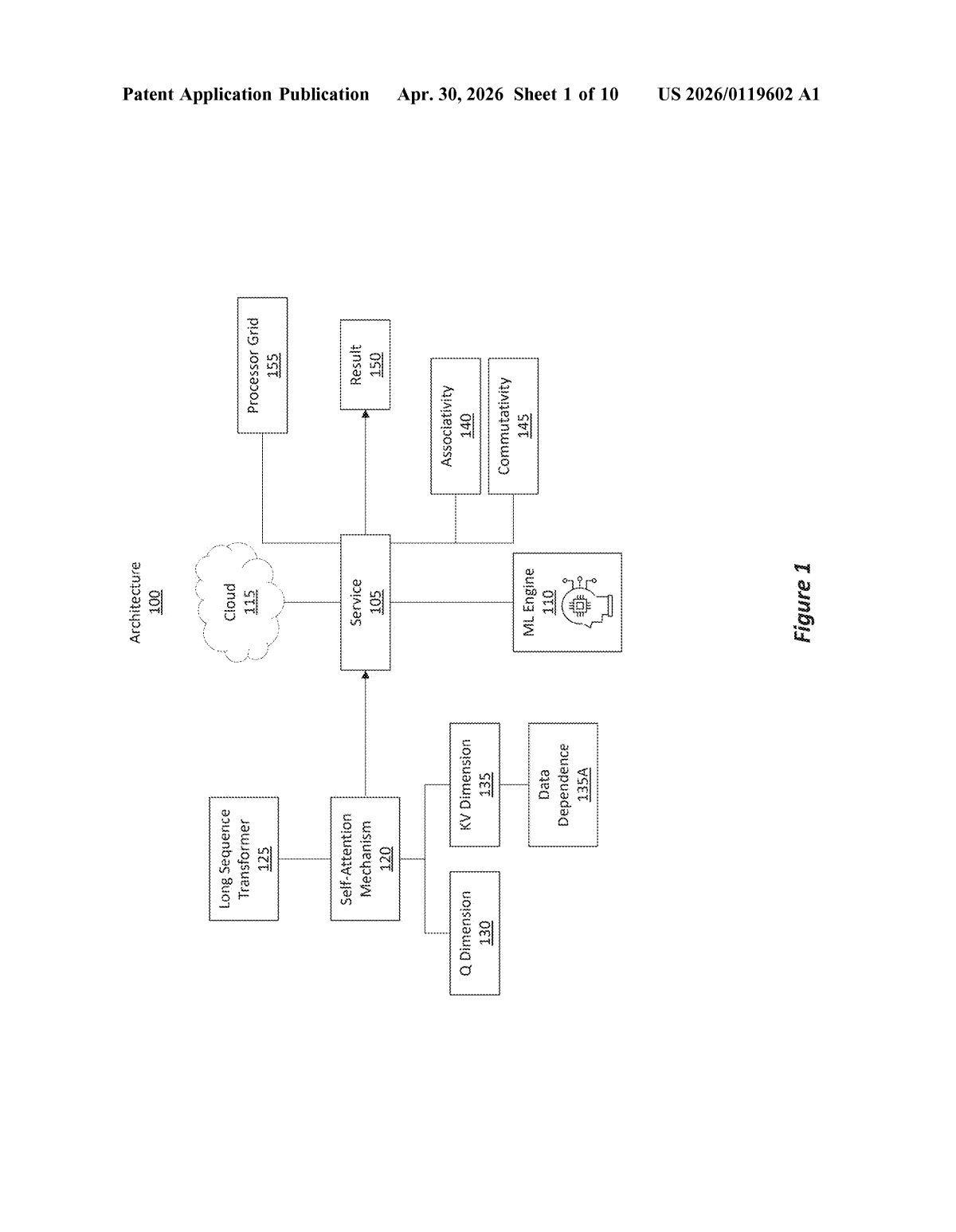
What Microsoft's 2D attention split actually does
Imagine you're trying to read a 10,000-word document and summarize every sentence's relationship to every other sentence. That's basically what a transformer's self-attention mechanism does — and the computation explodes as documents get longer. It's one of the most expensive parts of running a modern AI model.
Microsoft's patent describes a way to split that work across a two-dimensional grid of processors, rather than handing it to a single machine or splitting it along just one axis. The clever part: the math has two halves with different properties. One half (the 'Q' side, representing queries) can be split freely with no coordination between processors. The other half (the 'KV' side, representing keys and values) normally requires processors to share results — but the patent uses a mathematical trick to make even that part temporarily parallel.
The processors all work simultaneously, then combine their answers at the end. The goal is to handle much longer input sequences — think entire books, codebases, or long conversation histories — without the cost spiraling out of control.
How the Q and KV dimensions get divided across processors
Self-attention is the mechanism that lets each token in a sequence 'look at' every other token. Mathematically, it involves three matrices: Q (queries), K (keys), and V (values). Computing attention across a long sequence means multiplying huge matrices together — work that scales quadratically with sequence length.
This patent introduces a 2D parallelism scheme. Instead of distributing work along a single axis, the system uses a logical 2D grid of processors and exploits two different mathematical properties:
- Q-dimension parallelism: Queries carry no data dependencies (each query chunk is independent), so they're split freely across processor rows — no communication needed.
- KV-dimension parallelism: Keys and values do have dependencies (later tokens need earlier context), but the patent uses the associativity and commutativity of the underlying math (meaning you can reorder and regroup operations without changing the answer) to temporarily treat this dimension as parallel too.
- Reduction operation: Once each processor has computed a partial result (a piece of the final attention score), a coordinated reduction step — combining partial answers row-by-row and column-by-column — produces the correct final result.
The net effect is that a processor grid that previously could only parallelize along one dimension can now parallelize along both, cutting the communication overhead that normally makes long-sequence attention expensive.
Why cheaper long-context attention matters for AI services
Long-context transformers — models that can reason over 100,000 tokens or more — are increasingly central to enterprise AI products like Microsoft Copilot and Azure OpenAI Service. The bottleneck isn't always model quality; it's often the raw compute cost of running attention over huge inputs. A more efficient parallelism scheme means Microsoft can serve longer contexts at lower cost, or pack more requests onto the same hardware.
For you as a developer or enterprise customer, this kind of infrastructure work is what determines whether long-context features are affordable to use at scale — or reserved for deep-pocketed customers. It's not glamorous, but it's exactly the kind of systems-level optimization that separates competitive cloud AI platforms from also-rans.
This is squarely an infrastructure patent — no new model architecture, no consumer-facing feature. But it's a real technical contribution: 2D parallelism for attention is a genuine engineering challenge, and Microsoft's approach to temporarily decoupling the KV dependency using algebraic properties is clever. This is the kind of work that quietly makes large-context AI cheaper to run, and that matters a lot in a market where cost-per-token is a competitive battleground.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.