IBM Patents a System That Automatically Finds Sensitive Data Hiding in Databases
Most companies don't actually know where all their sensitive data lives — it's buried somewhere between the app your employees use and the database underneath it. IBM's new patent describes a system that watches both layers at once and figures out the connections automatically.
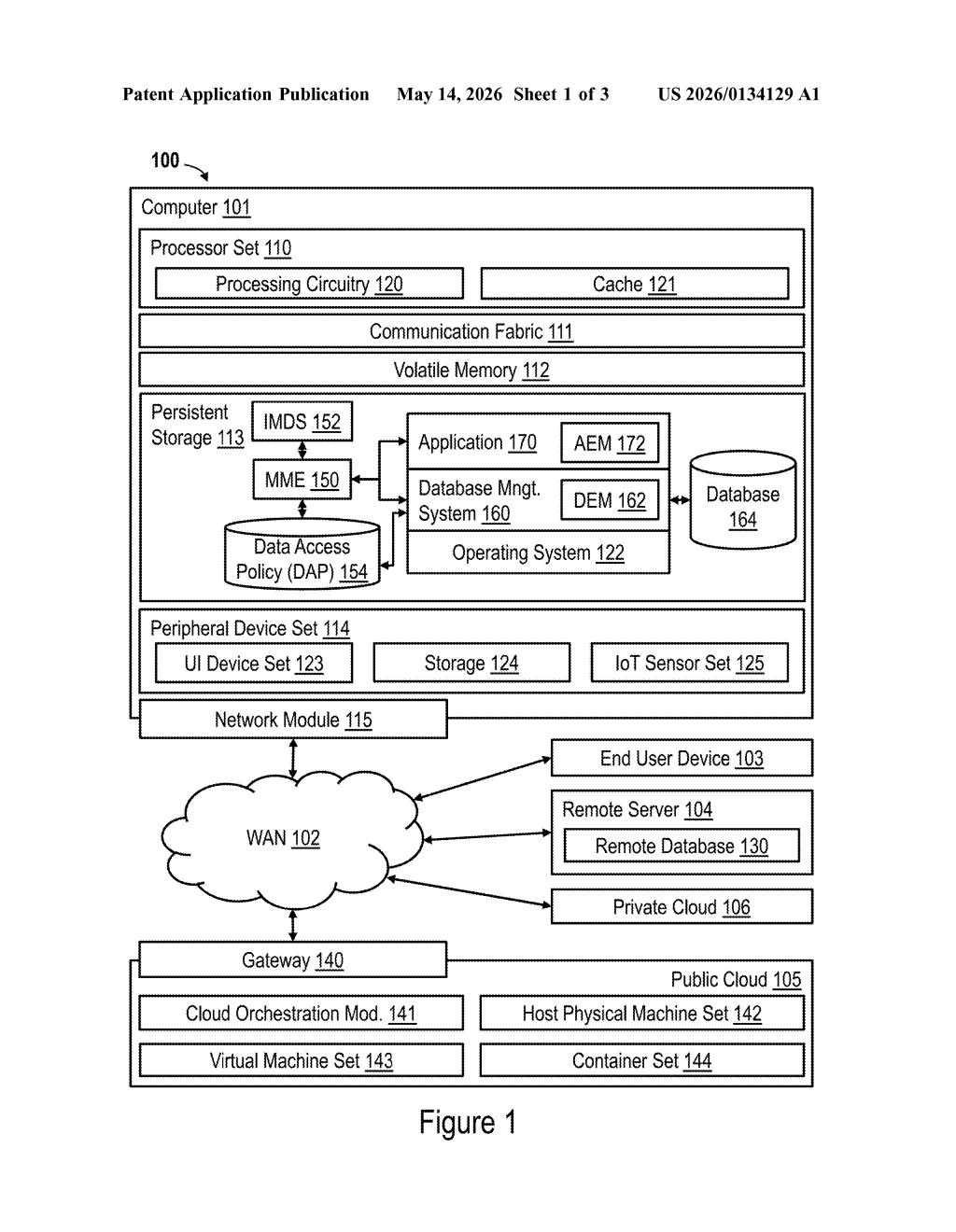
How IBM connects app screens to database fields automatically
Imagine your company has a customer portal where employees can look up account details. The portal shows a field labeled "Social Security Number" on screen — but somewhere in the database, that same value might be stored in a column called cust_id_secondary or something equally cryptic. Nobody connected those dots in writing. This happens constantly in large enterprises.
IBM's patent describes a system that watches the application and the database at the same time, in a kind of test mode. It notices which screen fields light up when a user interacts with the app, and which database columns get queried in response. By matching the actual data values flowing through both layers, it can infer that "this screen field = that database column."
Once those mappings are established, the system runs classification checks to flag which database fields likely contain sensitive data — things like personal IDs, health records, or financial info. It then automatically tightens the database access policy to protect those fields. The goal: close the gap between what should be protected and what actually is.
How the mapping engine links UI fields to database objects
The patent describes a multi-component architecture with two main monitoring agents running in parallel. A Database Event Monitor (DEM) watches every query the database management system executes. An Application Event Monitor (AEM) watches the application's UI layer — specifically which data fields are rendered or tagged during user sessions.
A core component called the Mapping and Monitoring Engine (MME) correlates the outputs of both monitors. It matches data values seen in application interface fields against values retrieved from database object-fields (tables, columns). When the same value appears in both layers, the MME creates an entry in an Inter-layer Mapping Data Store (IMDS) — essentially a lookup table connecting UI fields to their database counterparts.
The system also handles a tricky edge case: duplicate associations, where the same database column might map to multiple app fields (or vice versa). A deduplication step resolves these ambiguities before classification runs.
- Classification processing then scans the identified database fields against known sensitive-data patterns (PII, PHI, financial data, etc.)
- The results feed directly into an updated data access policy — so the database's permission rules reflect the newly discovered sensitive fields
- The whole process runs in a test mode, meaning it can profile an application's behavior without touching production traffic
What this means for enterprise data compliance teams
Most data governance tools require someone to manually label what's sensitive and where it lives — a process that's slow, error-prone, and perpetually out of date as databases evolve. IBM's approach automates the discovery leg entirely by observing real application behavior rather than relying on documentation or static schema scans.
For enterprises navigating regulations like GDPR, HIPAA, or CCPA, this kind of automated mapping could shrink the gap between a compliance audit and reality. The self-updating policy piece is the real hook: instead of waiting for a human to notice a new sensitive column got added to a table, the system adjusts access rules on its own. That's a meaningful shift for teams managing hundreds of databases and thousands of app integrations.
This is squarely in IBM's wheelhouse — enterprise data governance infrastructure that most consumers will never see but that compliance and security teams genuinely need. The core idea of correlating UI layer behavior with database-layer queries to infer sensitive data mappings is clever and solves a real, expensive problem. It's not a flashy AI patent, but it's the kind of foundational plumbing that could slot neatly into IBM's Guardium data security platform.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.