IBM Patents a Mixture-of-Experts System for Tracing Text Back to Its Source
IBM is patenting a way to figure out where a piece of text originally came from — using a Mixture of Experts neural network where each 'expert' has been trained to recognize text from a specific source.
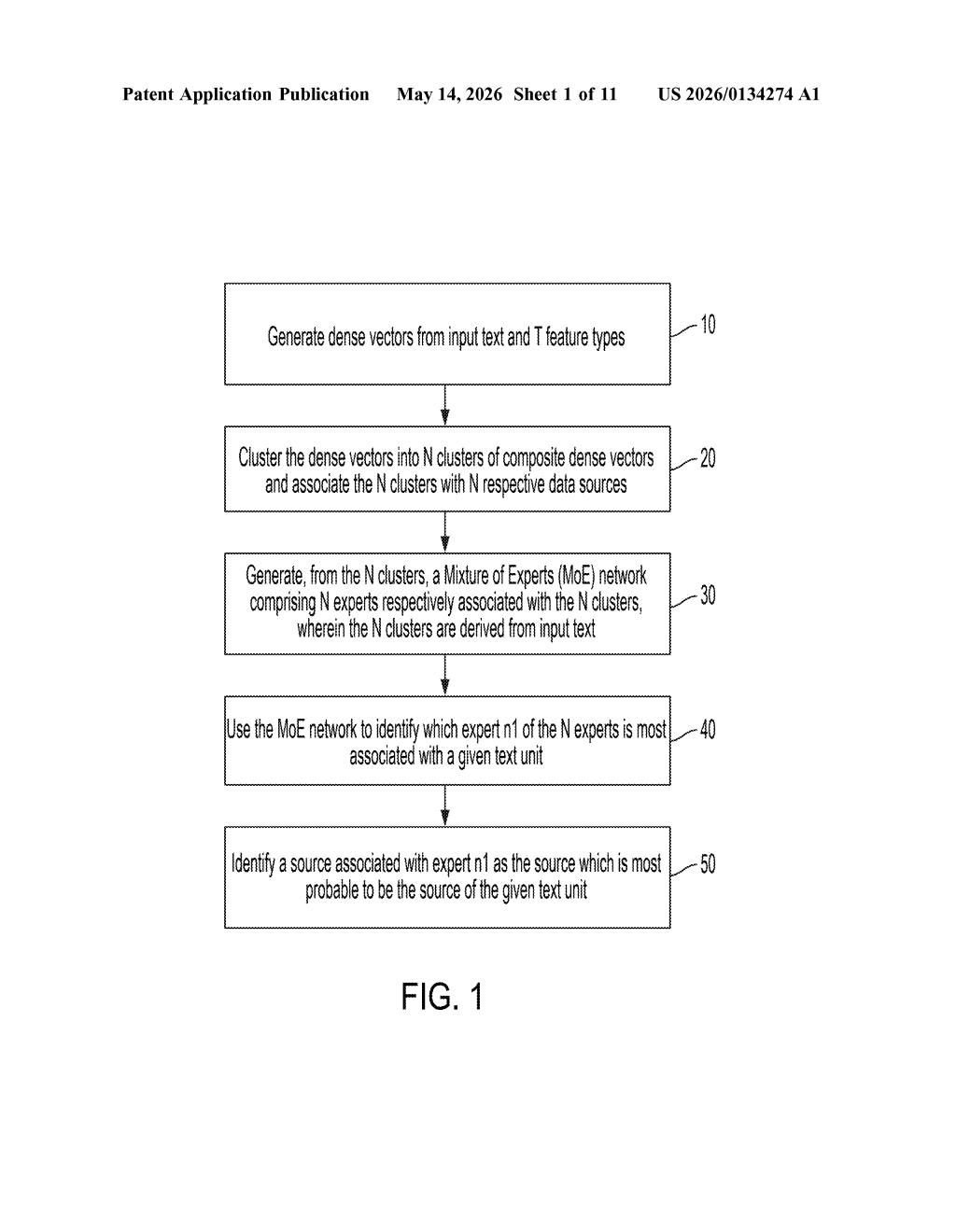
What IBM's text-source detection system actually does
Imagine you find an article online and you want to know whether it came from a news wire, a corporate press release, a social media post, or maybe an AI model. Telling those apart automatically is harder than it sounds — they can all look like normal paragraphs. IBM's patent describes a system designed to do exactly that.
The system works by grouping sample texts into clusters based on their writing patterns, then training a separate small neural network — called an expert — on each cluster. Together, those experts form a Mixture of Experts (MoE) network. When you feed the system a new piece of text, it figures out which expert recognizes it most strongly and uses that to label the text's probable source.
Think of it like having a panel of specialists: one who knows academic writing, one who knows ad copy, one who knows AI-generated prose. Rather than one generalist guessing, the right specialist speaks up.
How IBM's MoE network clusters and classifies text origins
The patent describes a pipeline with a few distinct stages:
- Dense vector generation: Input text is converted into numerical representations (dense vectors) that capture its meaning and style across T feature types — things like vocabulary, sentence structure, or semantic content.
- Clustering: Those vectors are grouped into N clusters (at least 2). Each cluster is associated with a distinct data source — essentially, texts that look alike end up in the same bucket.
- Expert training: A separate transformer model (a type of neural network architecture, the same family as GPT and BERT) is trained on each cluster, becoming an 'expert' tuned to that source's style and patterns.
- Inference: When a new text unit is submitted, the MoE network identifies which expert most strongly claims it, and that expert's associated source is returned as the most probable origin.
The Mixture of Experts design is important here. Rather than training one monolithic model to distinguish all sources simultaneously — which can muddy internal representations — each expert specializes. The routing logic then acts as a lightweight classifier on top of the specialized sub-models.
The claim is broad: it covers the training procedure itself, meaning the core novelty IBM is asserting is the method of building the MoE network from clustered text data for provenance purposes.
What this means for AI content attribution and provenance
Text provenance is becoming a genuinely hard problem. As AI-generated content floods the web, organizations — from publishers to compliance teams to social platforms — increasingly need tools that can label where content came from, not just whether it's 'good' or 'bad.' IBM's approach is interesting because it's source-agnostic at setup: you define your source clusters from data, and the model learns the rest.
For IBM, this slots naturally into its enterprise AI and data governance portfolio. Think compliance use cases, media monitoring, or internal document classification. The practical catch is that the system is only as good as the clusters you start with — if your training data doesn't cleanly represent distinct sources, the experts will blur together.
This is solid, useful infrastructure work rather than a flashy AI demo. The MoE-for-provenance angle is legitimately interesting as a framing — it's a reasonable architectural choice for a multi-source classification problem. But the first independent claim is quite broad and abstract, which means its real-world novelty will likely live or die in the implementation details IBM doesn't fully spell out here.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.