IBM Patents a Vector Table System for Smarter Processor Register Access
Accessing registers in a processor sounds like plumbing — until you realize that how efficiently a chip can juggle its internal scratch space has a direct impact on how fast it runs complex workloads. IBM is filing a patent for a more flexible way to do exactly that.
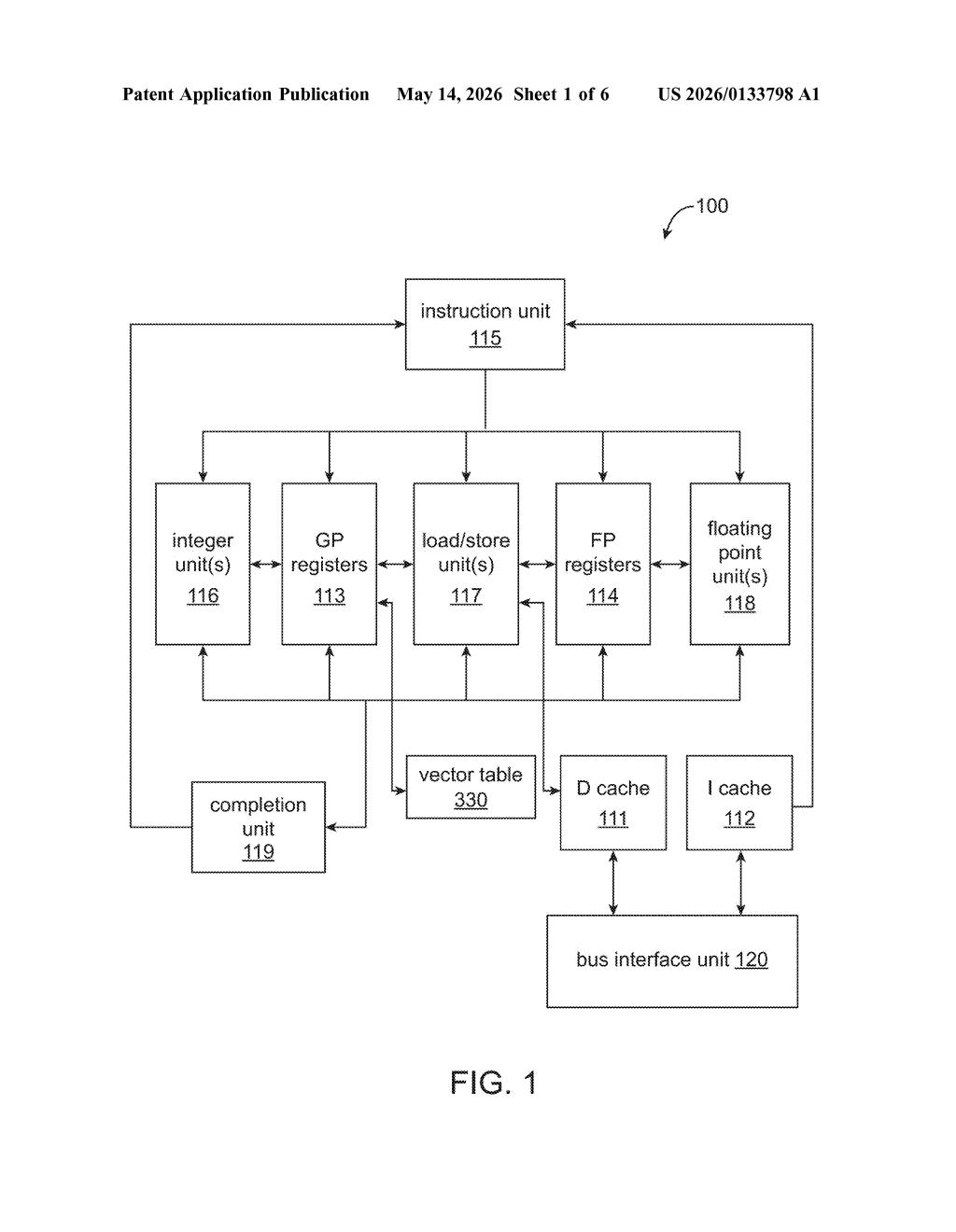
What IBM's indirect register addressing actually does
Imagine a hotel concierge desk with a master key ring. Instead of handing you one key at a time, the concierge can hand you a card that says "rooms 301, 303, and 305" all at once — and you don't need to know the individual room numbers, just the card number. That's roughly what IBM is patenting here for processor registers.
Inside a processor, registers are tiny, ultra-fast storage slots used constantly during computation. Normally, instructions have to name specific registers directly. IBM's approach adds a vector table — a lookup structure that sits between the instruction and the registers, letting a single index in an instruction point to one register or a whole pattern of registers at once.
Each entry in the table stores three things: which register to start at, how many to grab, and the spacing ("stride") between them if you're grabbing several. The practical payoff is that code can be more compact and flexible — you change the table entry, not every instruction that uses it.
How the vector table maps one index to many registers
The patent describes an indirect register addressing system built around a structure called a vector table. Rather than hard-coding register addresses directly into each instruction, instructions carry a vector table index — a small number that points into the table, which then resolves to the actual register or registers.
Each entry in the vector table has three components:
- Register entry number field — identifies the starting register in the set.
- Vector length field — specifies whether this entry resolves to a single register or multiple registers simultaneously (i.e., the "width" of the access).
- Vector stride pattern field — when multiple registers are accessed, this defines the spacing between them. A stride of 2, for example, means every other register starting from the base.
The stride pattern is the subtler innovation here. It allows non-contiguous register sets to be addressed as a logical group — useful for data layouts where elements are interleaved in memory or register files. Think of it like telling the CPU: "grab every other register starting from slot 10, four of them total."
The design also implies that re-targeting code to use different registers is as simple as updating a table entry rather than recompiling or patching individual instructions — a meaningful flexibility gain in dense compute pipelines.
What this means for high-performance processor design
For IBM's high-performance and mainframe processor lines — where instruction density, register file efficiency, and compiler flexibility are serious engineering concerns — this kind of indirection layer is genuinely useful. Workloads like matrix operations, signal processing, and AI inference regularly need to sweep through non-contiguous register patterns, and doing that efficiently at the hardware level saves cycles.
For you as a developer or architect, the downstream effect would be smaller, more portable code and more compiler flexibility without sacrificing raw throughput. It's the kind of hardware feature that doesn't make headlines but quietly makes a compiler engineer's job easier — and that tends to show up as sustained performance gains over time.
This is a focused, well-scoped processor architecture patent — not flashy, but squarely in IBM's wheelhouse of deep hardware engineering for enterprise compute. The stride-pattern indirection is the genuinely interesting piece; it's a real solution to a real problem in dense register-file workloads. Worth tracking if you care about ISA design or IBM's POWER/z architecture roadmap.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.