Red Hat Patents a Self-Updating Background Dataset for AI Explainability
Getting an AI model to explain its own decisions is hard enough — but doing it accurately when your data is constantly changing is even harder. Red Hat's new patent tackles exactly that problem with a system that rebuilds its explanation context fresh with every single prediction.
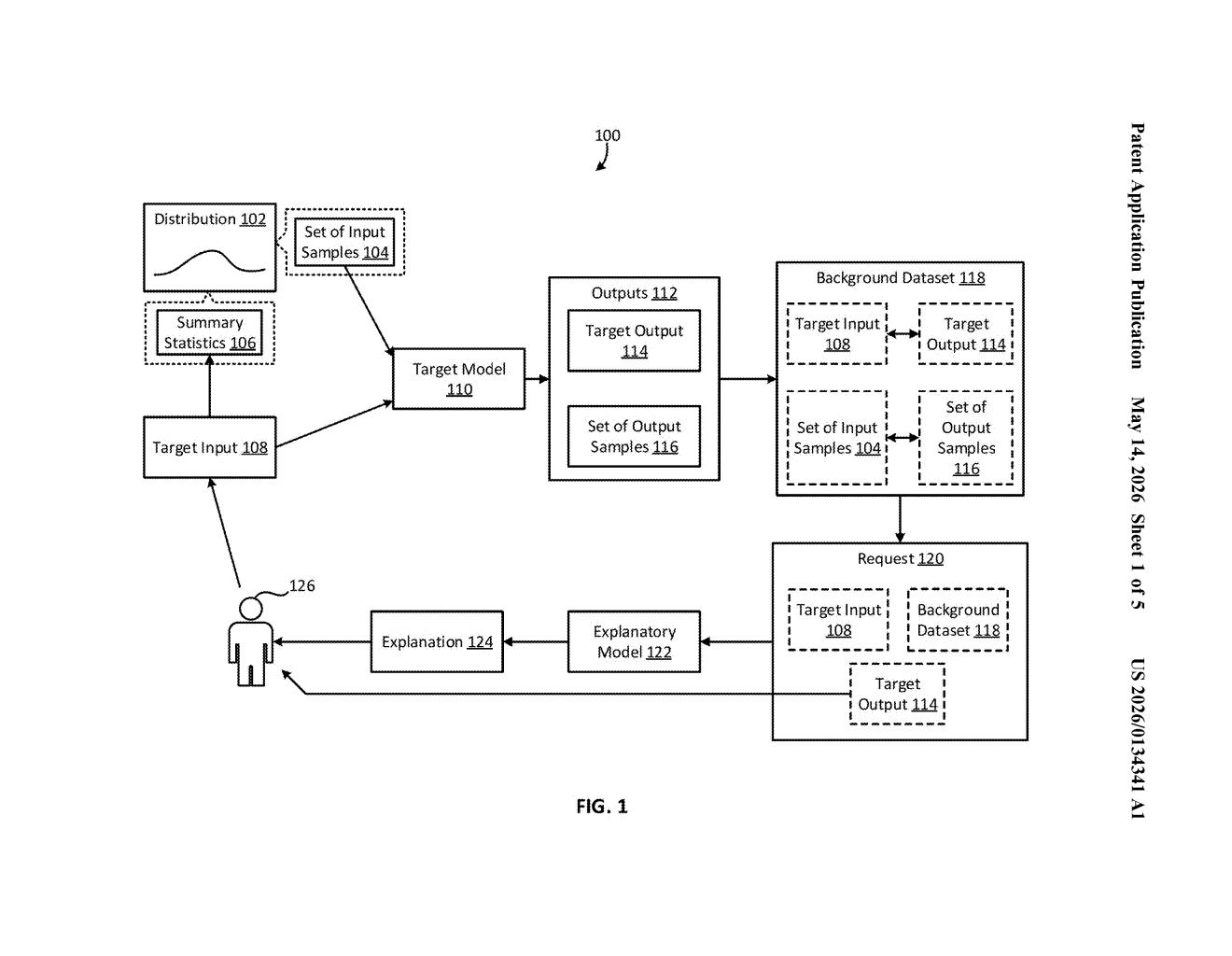
What Red Hat's rolling AI explanation system actually does
Imagine you ask an AI system to approve or flag a job application, and it does — but you want to know why. Most explainability tools (like SHAP or LIME) need a reference set of "normal" examples to compare against, kind of like needing to know what a typical application looks like before you can say why this one is unusual. The catch: that reference set is usually built once and then frozen, which means it goes stale as the world changes.
Red Hat's patent describes a system that never freezes that reference set. Every time the AI makes a prediction, the system generates fresh comparison examples on the fly, runs them through the same model, and uses the results to update a living dataset. That updated dataset feeds straight into an explanation engine.
The result: you always get an explanation grounded in the AI's current behavior, not its behavior from six months ago when the reference data was last compiled. For teams running AI in production — where data drifts and models get retrained — that's a meaningful improvement over the status quo.
How the distribution sampling loop builds context per inference
The system operates as a continuous loop, one iteration per incoming prediction. Here's the sequence:
- Receive a target input — the actual data point the model needs to evaluate (a loan application, an image, a log entry).
- Update a distribution summary statistic — the system maintains a statistical model of all inputs seen so far (think: a running mean and variance). That model gets nudged with each new input.
- Sample the distribution — the system draws a batch of synthetic "what-if" inputs from that distribution. These are plausible neighbors of the real input, not random noise.
- Run everything through the target model — both the real input and the synthetic samples get scored. The model returns a real output and a set of counterfactual outputs.
- Update the background dataset — the real input-output pair and all the synthetic pairs get logged. This is the reference context that explanation tools need.
- Query the explanatory model — the fresh background dataset, the real input, and the real output are bundled into a request to an explanation layer (likely a SHAP-style or LIME-style model), which explains why the target model produced that output.
The key innovation is that the background dataset is never static. It grows and shifts with every inference, staying aligned with the model's actual behavior over time. The distribution used for sampling also updates continuously, so the synthetic examples remain statistically representative — not artifacts of an old data snapshot.
What this means for real-time explainable AI in production
For most production AI systems, explainability is a post-hoc add-on that relies on a fixed reference dataset baked in at training time. When the model's input distribution shifts — seasonal trends, changing user behavior, a model retrain — the explanations quietly become less accurate, and nobody notices. Red Hat's approach makes the explanation infrastructure adapt at the same cadence as the model itself.
This is especially relevant for regulated industries like finance, healthcare, and HR, where you may be legally required to explain individual AI decisions to affected users. A system that always explains based on current context is a much more defensible audit trail than one frozen to a snapshot from last quarter. For Red Hat's OpenShift AI and Trusty AI customers, this fits neatly into the explainability tooling they already ship.
This is genuinely useful infrastructure work, not a flashy AI-hype filing. The problem it solves — stale explanation baselines in production ML — is real and under-discussed. Red Hat's explainability tooling (Trusty AI) is an actual shipping product, which gives this patent a credible path to deployment rather than a shelf somewhere.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.