Adobe Patents a Machine Learning System for Reading Schematic Diagrams
Computers are great at reading words in a PDF, but terrible at understanding the circuit diagram or flowchart sitting right next to those words. Adobe is filing a patent to fix that.
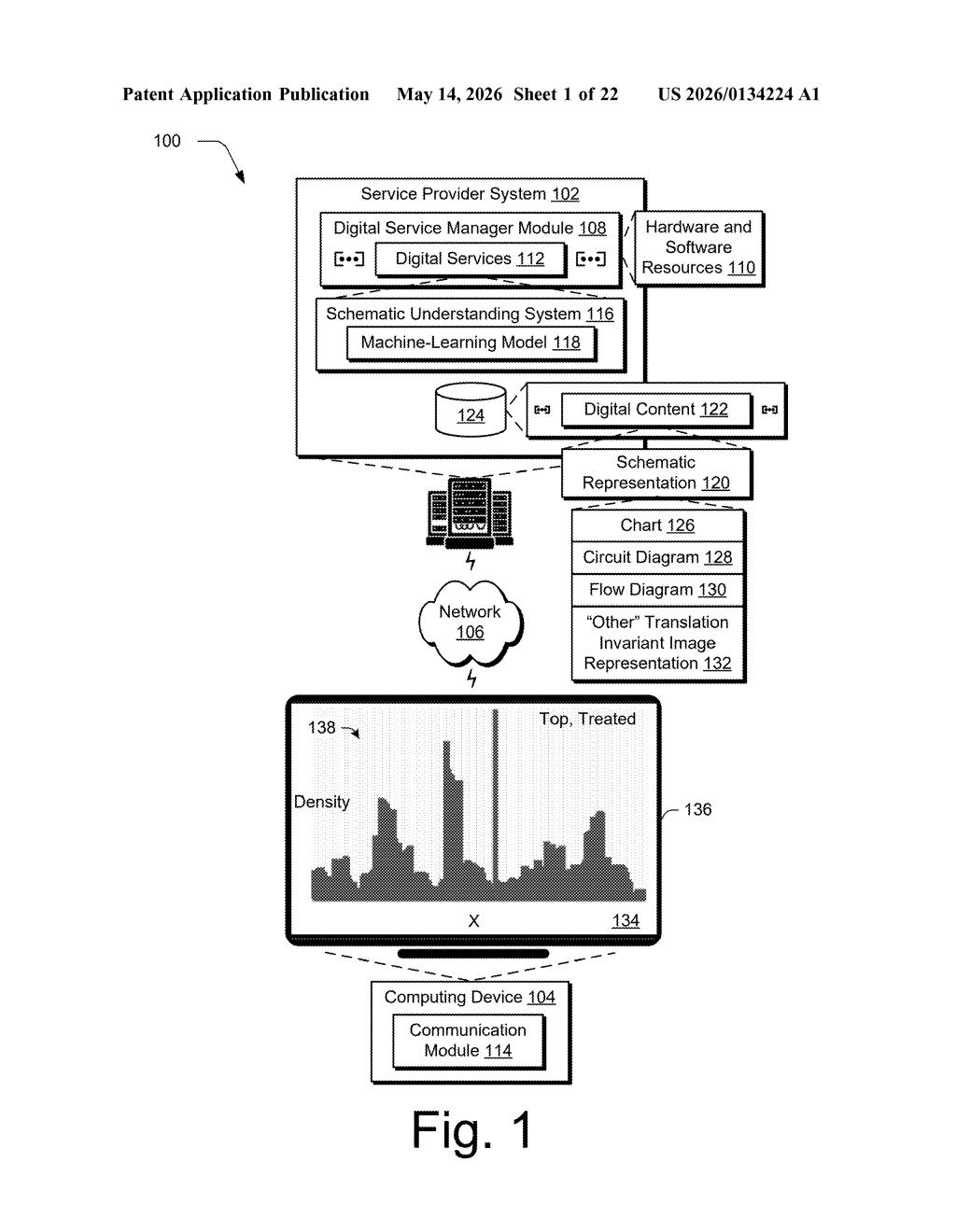
What Adobe's schematic-reading AI actually does
Imagine you paste a PDF containing an electrical circuit diagram or a network topology chart into an AI tool and ask, 'What does this diagram show?' Right now, most AI systems just see a flat image and shrug. Adobe's new patent describes a smarter approach: teaching software to actually understand what's inside a schematic, not just see it.
The system works by pulling apart the raw data stream that a PDF uses to draw the diagram — things like coordinates, lines, and labels — then filtering that stream to isolate only the parts that belong to the schematic. From there, a machine-learning model interprets the layout and outputs a structured understanding of what the diagram represents.
This could apply to a wide range of visuals: flowcharts, circuit diagrams, network maps, and more. The goal is for Adobe's tools to treat diagrams as meaningful content, not just decorative pictures.
How Adobe filters content streams to extract diagram data
The patent describes a pipeline with four main stages:
- Layout element identification: The system first detects that a schematic — like a chart, circuit diagram, or flow diagram — exists somewhere inside a digital document.
- Content stream extraction: PDFs and similar formats use a 'content stream' (essentially a low-level rendering script that tells the viewer where to draw every line, shape, and glyph). The system taps directly into that stream rather than treating the diagram as a finished image.
- Schematic layout data generation: The raw content stream is filtered to isolate data points specifically associated with the schematic. This removes surrounding page noise and surfaces the structural information — coordinates, connections, labels — that describe the diagram's meaning.
- Understanding result output: A machine-learning model consumes the cleaned-up layout data and produces a schematic understanding result — essentially a machine-readable interpretation of what the diagram depicts.
One interesting detail: the patent mentions an 'invariant image representation' — a normalized version of the schematic that's consistent regardless of scale, rotation, or styling. This suggests the ML model is trained to recognize diagram semantics independent of cosmetic differences, which is a non-trivial challenge.
What this means for Adobe's document AI ambitions
Adobe is already deep into document AI with Acrobat AI Assistant, which lets you chat with PDFs. Right now, that assistant largely works with text — ask it about a circuit diagram embedded in an engineering spec and you'll probably get a vague answer. A system that genuinely understands schematics would make document AI far more useful for technical professionals: engineers, architects, network admins, and anyone who works with diagram-heavy documents.
It also fits Adobe's broader strategy of making every element of a document queryable and editable by AI, not just the prose. If diagrams become first-class citizens in Adobe's AI layer, that's a meaningful expansion of what Acrobat and related tools can actually do for you.
This is a genuinely useful problem to solve — schematic understanding is a real gap in current document AI, and Adobe is one of the few companies with the PDF infrastructure depth to attack it from the content-stream level rather than relying on pure computer vision. Whether it ships as a polished feature or stays an internal capability is another question, but the technical direction is sound.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.