Adobe Patents a Privacy-Minded System for Comparing Ad Audience Targeting vs. Reality
Ever wonder if the audience that actually saw your ad campaign matches the one you intended to reach? Adobe is patenting a system that answers that question — without handing over raw user data to anyone.
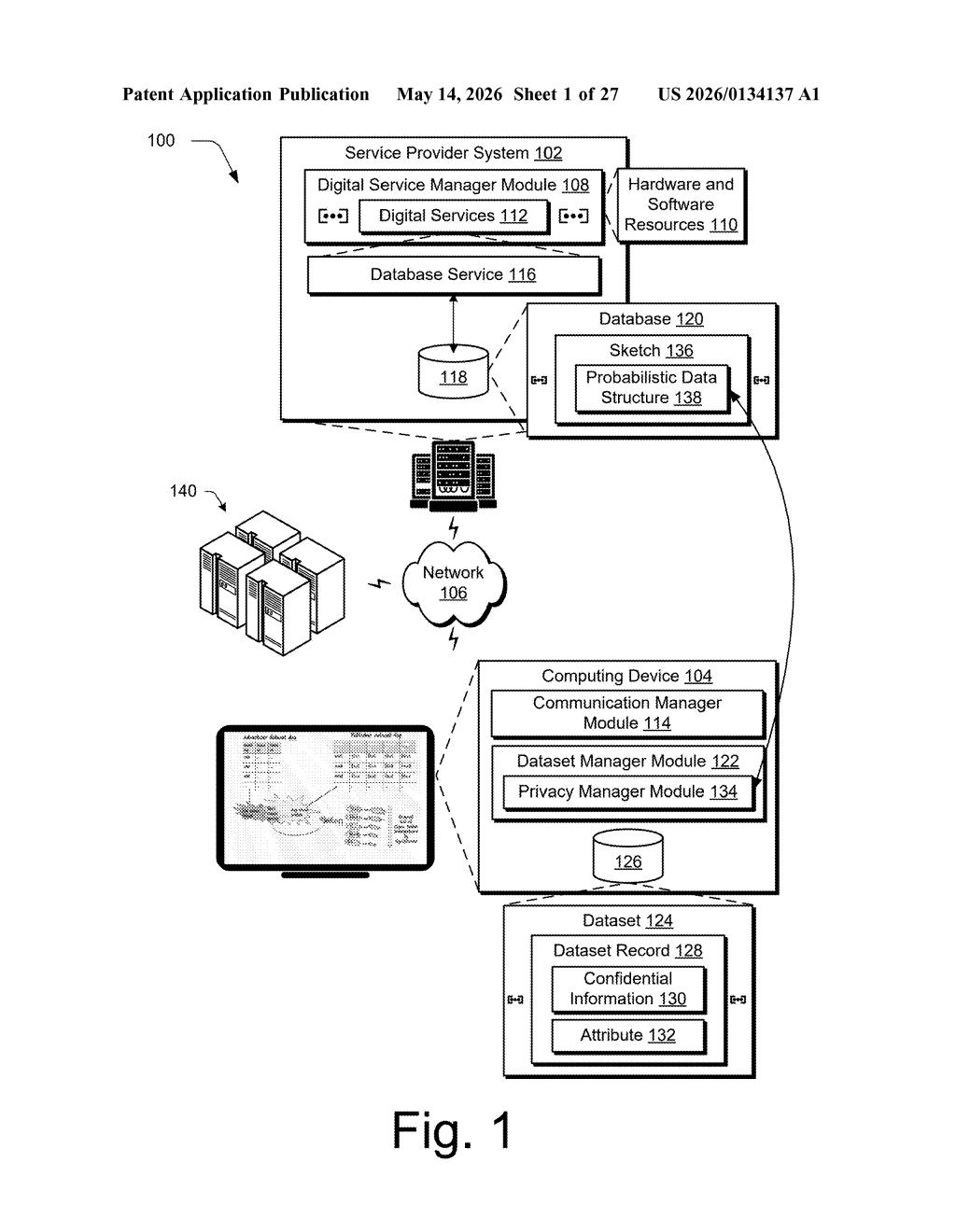
What Adobe's probabilistic audience sketches actually do
Imagine you run a marketing campaign targeting 25-to-35-year-old outdoor enthusiasts. Adobe's patent describes a system for checking whether the people who actually saw your ads matched that original target — but here's the catch: it does this without ever exposing the underlying user-level data.
The trick is something called a probabilistic sketch — a compact, mathematical fingerprint of a dataset that lets you answer questions like "how much do these two groups overlap?" without revealing who's in either group. One party sends a sketch of the intended audience; another sends a sketch of the actual audience. Adobe's system stores both and runs comparisons against them.
This matters in a world where advertisers, publishers, and data brokers are constantly trading audience information but regulators (and users) are increasingly uncomfortable with that. Sketches let you get useful answers while keeping the raw data locked away.
How Adobe's sketch-based query system compares audiences
The patent describes a pipeline with two distinct data flows feeding into a central comparison engine.
First, a targeted dataset arrives from one entity — say, an advertiser — describing the audience they wanted to reach as part of a targeted content control strategy (think: a programmatic ad buy or content suppression list). The system converts this into a targeted set of sketches, which are compact probabilistic data structures (algorithms like HyperLogLog or MinHash that approximate set properties — cardinality, intersection, union — in a fraction of the space a full dataset would require).
Second, a realized dataset arrives from a different entity — say, a publisher or DSP — describing who actually saw the content. This also gets converted into a realized set of sketches.
Both sketch sets are stored in a database. When a query comes in — "how many people in the realized audience were also in the target audience?" — the system runs the computation against the sketches and returns a probabilistic result (an approximation with a known error bound, not an exact count).
- Privacy benefit: raw records never need to be shared cross-entity
- Scale benefit: sketches are orders of magnitude smaller than source data
- Flexibility: multiple queries can run against stored sketches without re-ingesting data
What this means for ad measurement and data privacy
Ad measurement is heading into increasingly choppy waters — third-party cookies are being deprecated, privacy regulations like GDPR and CPRA restrict cross-party data sharing, and clean-room solutions are expensive and slow. A sketch-based system lets Adobe's ad tech stack (Adobe Advertising, Audience Manager, Real-Time CDP) offer campaign verification and overlap analysis without the legal and engineering overhead of a full data clean room.
For you as an advertiser or publisher using Adobe's tools, this could mean faster, cheaper audience reconciliation after a campaign ends — essentially a lightweight audit of whether your targeting actually worked, built into the platform rather than bolted on.
This is quiet infrastructure work, but it's pointed at a real and growing problem: how do you do audience analytics in a world where sharing raw data is legally risky and technically expensive? Adobe is essentially building a privacy-preserving measurement layer into its ad stack, and that's a defensible moat as clean-room mandates tighten across the industry. Don't expect a press release — but do expect this to show up as a feature in Real-Time CDP or Adobe Advertising quietly.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.