Adobe Patents a Single-Pass Streaming String Similarity Matching System
Finding a matching phrase inside a firehose of incoming text — without buffering, without backtracking — is harder than it sounds. Adobe's new patent describes a system that does it in a single sequential scan.
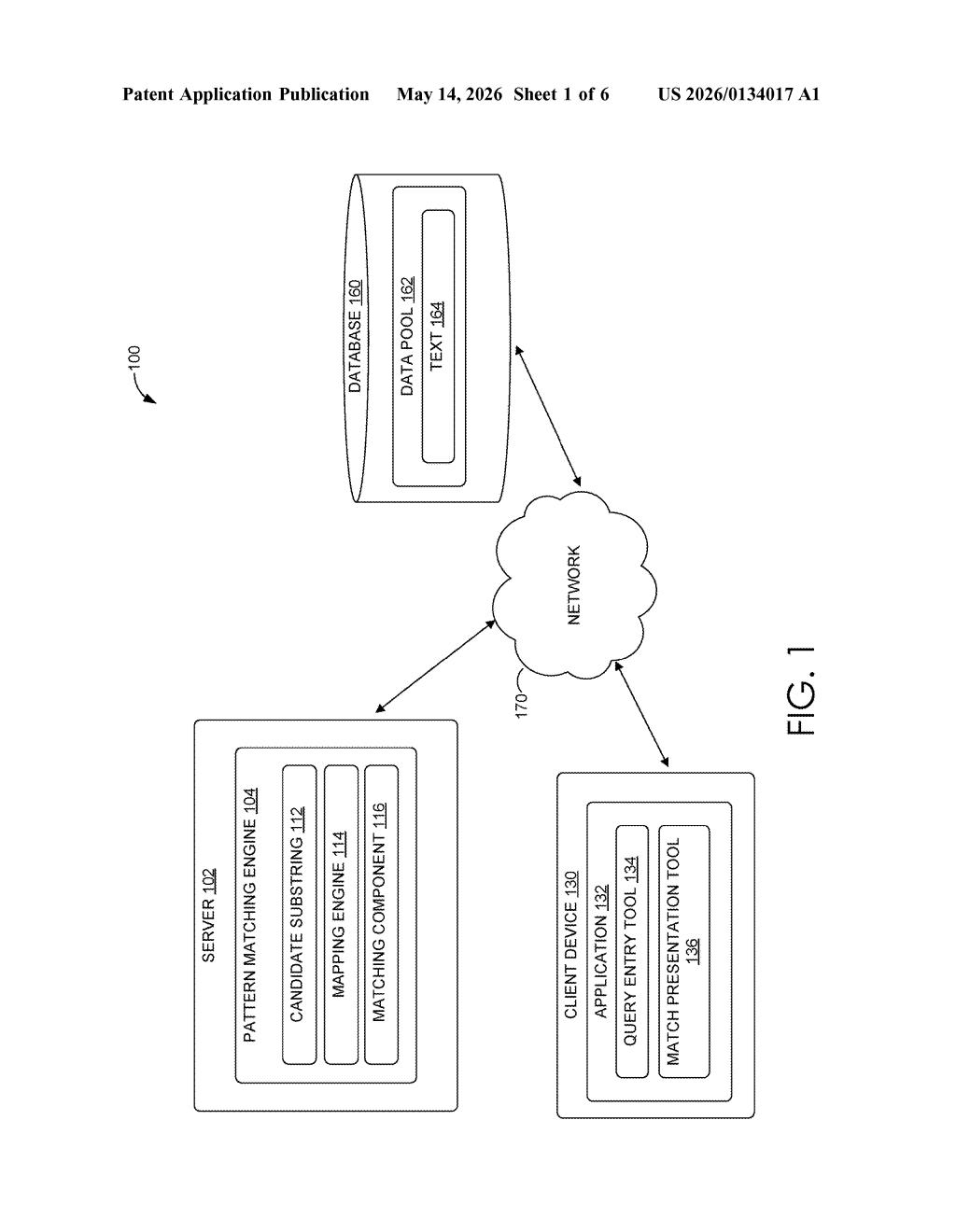
What Adobe's streaming text-search system actually does
Imagine you're searching for a specific phrase inside a live stream of text — think log files rolling in, documents being typed in real time, or content being ingested from a network feed. Normally, a search engine would wait until it had the whole document, then scan it. Adobe's patent describes a smarter approach: search the text as it arrives, one character at a time, without ever needing to go back.
The system takes your query string (the phrase you're looking for) and converts it into a compact numerical fingerprint. As new text streams in, it does the same for every candidate chunk of incoming text. If the two fingerprints are similar enough — above a set threshold — the system flags a match and tells you exactly where it was found.
This isn't just exact matching, either. The patent covers approximate matches, so typos or near-duplicates can still surface a hit. That makes it useful for fuzzy search, plagiarism detection, or real-time content moderation — anywhere you need fast answers on a moving stream of text.
How Adobe's mapping function scores substring similarity
The core of the patent is a mapping function applied to substrings of incoming text. As a stream of characters arrives, the system carves it into substrings whose lengths correspond to portions of the query string — a prefix, an infix, or any arbitrary sequence within it.
For each candidate substring, the system computes a mapping value (essentially a numeric fingerprint or embedding). It does the same for the corresponding portion of the query string. Then it calculates a similarity score between the two mapping values — think of this like a distance metric between two points in mathematical space. If that score exceeds a preset threshold, the system declares a match and records the location.
Key design properties described in the patent include:
- Single sequential pass: the stream is never rewound or re-read — important for low-latency and memory efficiency
- Approximate matching: the similarity score allows near-matches, not just exact hits
- Longest-match detection: when no exact match exists, the system can identify the longest overlapping substring it did find
The inventors — Tung Mai, Ryan Rossi, and Anup Rao — are researchers with backgrounds in sketching algorithms and graph/data-stream methods, which lines up with the probabilistic fingerprinting approach described here.
What this means for real-time document search at scale
For Adobe, which runs document processing, content intelligence, and Experience Cloud analytics at massive scale, being able to search streaming text without buffering entire documents could meaningfully reduce latency and infrastructure cost. Think real-time content tagging as a document is uploaded, or near-instant similarity checks across millions of incoming support tickets.
The approximate-matching angle is what elevates this beyond a routine text-search patent. If your search pipeline can tolerate configurable similarity thresholds, you can tune it for precision or recall depending on the use case — tighter for legal document deduplication, looser for content recommendation. That flexibility, baked into a streaming architecture, is the genuinely interesting engineering bet here.
This is a solid algorithms patent rooted in real research — the streaming, single-pass constraint is a meaningful engineering choice, not just a claim decoration. It's not flashy consumer tech, but Adobe's data pipeline needs are real, and approximate streaming search has legitimate commercial value in document intelligence and content moderation. Worth a second look if you're tracking Adobe's AI content infrastructure moves.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.